hash简介
说到底,他是一种hash算法,那什么是hash算法?
hash算法是一种散列算法,常用的比如MD5。抽象来说,他是将任意长度的输入X,经过hash算法后,变成固定长度的输出Y(输出Y称为散列值),多个X可能对应同一个Y(hash碰撞,概率极小极小极小,MD5的碰撞概率为2/2的64次方),且从Y不能反推出X,对X的任意修改,都将导致输出的Y完全不一样。
基于以上的这些特性,hash算法可以有以下这些应用场景:
用hash算法对网站的登陆密码使用散列值保存(利用的是不可反推这一特性,这样即便淘宝的数据库被盗了,谁也不会知道你到底在淘宝买了些什么...东西)
对比两个文件是否完全一样,假如要对比的txt文件中有上万的字符,如何一个一个去作对比,效率很差,直接对比文件的散列值是否一致即可知道文件是否一致(利用的是输出的散列值是固定长度)
-
负载均衡算法
作为负载均衡算法时,输入X是客户端请求的某个唯一ID或者key,hash之后的输出Y是一个一定范围内的Long类型数字,然后我们对这个Long类型的数字进行取模,取模得到的余数就是需要访问的节点唯一编号,利用取模的特性(假如集群中服务器数量为3台,那么模数是3,可以将大量的数字,映射到[0-3)这个区间段)将key均匀的映射到集群中的机器上,这样就达到了负载均衡的目的,算法公式:hash(key) % n,如下图:
 image.png
image.png
最终key1 - keyn会被均匀的分布在图中的三个节点上,看似已经达到了我们想要的负载均衡的效果了,但是,当客户端请求在某一时段激增的时候(比如双十一),我们常常需要增加服务器,双十一过后,这些增加的服务器又需要下线,那么上图中的算法,就不足以支撑这种情况,假如这时候node3需要被下线,那么客户端请求对应的负载均衡算法就变成了hash(key) % 2,这时候客户端所有请求和节点之间的映射关系就全变了,许多请求会被负载均衡到"错误的"节点上去从而拿不到想要的数据(如果是缓存,那么绝大部分的获取缓存的请求都会失效,大量请求会打到DB),人为的去转移数据,那只能996.ICU网站见了。为了解决这个问题,所以,我们需要一致性hash算法
一致性hash算法原理
假设我们采用的hash算法的值空间为0-P,将0-P构建成一个hash环,如下图:

在普通的hash算法中,我们仅仅对请求唯一标识做了hash,并且它是一个线性的hash空间,而在一致性hash算法中,还会使用同样的hash算法对服务器标识做一次hash运算(一般对服务器IP或者主机名做hash运算),然后将两种hash值映射在这个hash环(java中可以用TreeMap实现)上面,如下图:
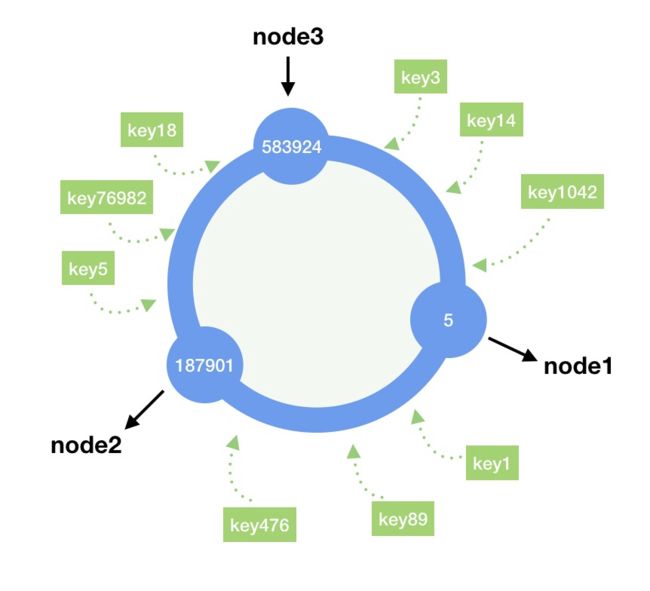
一致性hash算法具备以下特性:
- 客户端请求最终会落到他所在hash环的顺时针方向的第一个节点上,在上图中,key3,key14,key1024请求最终会落到node1上面,而key5,key76982,key18会落到node3上面。
- 当集群中删除节点nodex时,原本应该落在nodex上面的请求,会被转移到nodex顺时针的下一个节点,新增节点同理,可以看到,无论新增还是删除一个节点,受影响的都只有一个节点的数据,如下图:
 image.png
image.png
 image.png
image.png
以上的一致性hash算法相比较普通的hash算法有了很大的改进,但是依然存在问题,以删除节点为例,删除一个节点后,集群中大部分的请求key都会落到node2这个节点上,已经并不是"负载均衡"了。一般的hash环空间会很大,而如果当集群中节点数量不是很多的时候,节点在环上面的位置可能会挤在很小的一部分区域,这样就导致一大部分请求会落到某个节点上(数据倾斜),为了解决这个问题,一致性hash算法引入虚拟节点。
虚拟节点
对每一个服务器节点进行多次hash,将生成的hash值也分布在hash环上,这些新生成的节点称为虚拟节点。假设我们用服务器IP地址来做hash,那么可以在IP地址后面增加编号来做hash运算生成虚拟节点,增加虚拟节点后,hash环如下图:
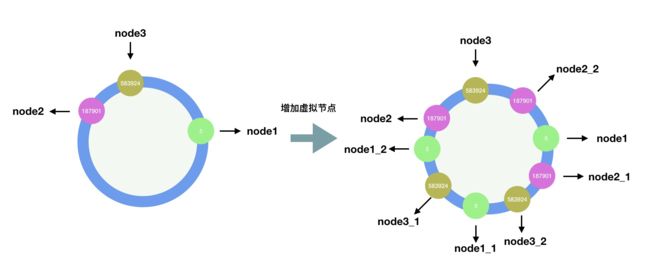
从图中看到,没有增加虚拟节点的时候,大部分的请求会落到node2这个节点上面,导致node2节点请求压力过大,当我们增加虚拟节点后,node1,node2,node3都能均匀的接收到客户端的请求。而删除某个节点nodex的时候,原本应该落在nodex上面的请求,也会被均匀的分配给其他节点。
java实现一致性hash算法
首先我们得需要一个hash算法,hash算法有很多种,这里提供两种实现,一种基于MD5,一种基于FNV1_32_HASH(这种其实是我抄来的,哈哈哈哈~~~~)
基于MD5:
/**
* hash 运算
* @param value
* @return
*/
public Long hash(String value){
MessageDigest md5;
try {
md5 = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("MD5 not supported", e);
}
md5.reset();
byte[] keyBytes = null;
try {
keyBytes = value.getBytes("UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("Unknown string :" + value, e);
}
md5.update(keyBytes);
byte[] digest = md5.digest();
// hash code, Truncate to 32-bits
long hashCode = ((long) (digest[3] & 0xFF) << 24)
| ((long) (digest[2] & 0xFF) << 16)
| ((long) (digest[1] & 0xFF) << 8)
| (digest[0] & 0xFF);
long truncateHashCode = hashCode & 0xffffffffL;
return truncateHashCode;
}
基于FNV1_32_HASH:
public class HashUtil {
/**
* 计算Hash值, 使用FNV1_32_HASH算法
* @param str
* @return
*/
public static int getHash(String str) {
final int p = 16777619;
int hash = (int)2166136261L;
for (int i = 0; i < str.length(); i++) {
hash =( hash ^ str.charAt(i) ) * p;
}
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
if (hash < 0) {
hash = Math.abs(hash);
}
return hash;
}
}
接下来我们实现hash环,负载均衡一般是读多写少(新增或者删除节点毕竟少数),在读多写少的情况下,我们容易想到用二叉树来实现,在java中一般直接可以用TreeMap来实现,TreeMap是由红黑树实现的,很适合作为hash环的存储结构,先实现一个没有虚拟节点的hash环:
public class ConsistentHashingWithoutVirtualNode {
/**
* 集群地址列表
*/
private static String[] groups = {
"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"
};
/**
* 用于保存Hash环上的节点
*/
private static SortedMap sortedMap = new TreeMap<>();
/**
* 初始化,将所有的服务器加入Hash环中
*/
static {
// 使用红黑树实现,插入效率比较差,但是查找效率极高
for (String group : groups) {
int hash = HashUtil.getHash(group);
System.out.println("[" + group + "] launched @ " + hash);
sortedMap.put(hash, group);
}
}
/**
* 计算对应的请求应该落到哪一个节点上
*
* @param key
* @return
*/
private static String getServer(String key) {
int hash = HashUtil.getHash(key);
// 只取出所有大于该hash值的部分而不必遍历整个Tree
SortedMap subMap = sortedMap.tailMap(hash);
if (subMap == null || subMap.isEmpty()) {
// hash值在最尾部,应该映射到第一个group上
return sortedMap.get(sortedMap.firstKey());
}
return subMap.get(subMap.firstKey());
}
public static void main(String[] args) {
// 生成随机数进行测试
Map resMap = new HashMap<>();
for (int i = 0; i < 100000; i++) {
Integer widgetId = (int)(Math.random() * 10000);
String server = getServer(widgetId.toString());
if (resMap.containsKey(server)) {
resMap.put(server, resMap.get(server) + 1);
} else {
resMap.put(server, 1);
}
}
resMap.forEach(
(k, v) -> {
System.out.println("group " + k + ": " + v + "(" + v/1000.0D +"%)");
}
);
}
}
生成10000个随机数字进行测试,最终得到的压力分布情况如下:
[192.168.0.1:111] launched @ 8518713
[192.168.0.2:111] launched @ 1361847097
[192.168.0.3:111] launched @ 1171828661
[192.168.0.4:111] launched @ 1764547046
group 192.168.0.2:111: 8572(8.572%)
group 192.168.0.1:111: 18693(18.693%)
group 192.168.0.4:111: 17764(17.764%)
group 192.168.0.3:111: 27870(27.87%)
group 192.168.0.0:111: 27101(27.101%)
可以看到,请求分布负载不均衡,接下来我们引入虚拟节点:
public class ConsistentHashingWithVirtualNode {
/**
* 集群地址列表
*/
private static String[] groups = {
"192.168.0.0:111", "192.168.0.1:111", "192.168.0.2:111",
"192.168.0.3:111", "192.168.0.4:111"
};
/**
* 真实集群列表
*/
private static List realGroups = new LinkedList<>();
/**
* 虚拟节点映射关系
*/
private static SortedMap virtualNodes = new TreeMap<>();
private static final int VIRTUAL_NODE_NUM = 1000;
static {
// 先添加真实节点列表
realGroups.addAll(Arrays.asList(groups));
// 将虚拟节点映射到Hash环上
for (String realGroup: realGroups) {
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
String virtualNodeName = getVirtualNodeName(realGroup, i);
int hash = HashUtil.getHash(virtualNodeName);
System.out.println("[" + virtualNodeName + "] launched @ " + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
}
private static String getVirtualNodeName(String realName, int num) {
return realName + "&&VN" + String.valueOf(num);
}
private static String getRealNodeName(String virtualName) {
return virtualName.split("&&")[0];
}
private static String getServer(String key) {
int hash = HashUtil.getHash(key);
// 只取出所有大于该hash值的部分而不必遍历整个Tree
SortedMap subMap = virtualNodes.tailMap(hash);
String virtualNodeName;
if (subMap == null || subMap.isEmpty()) {
// hash值在最尾部,应该映射到第一个group上
virtualNodeName = virtualNodes.get(virtualNodes.firstKey());
}else {
virtualNodeName = subMap.get(subMap.firstKey());
}
return getRealNodeName(virtualNodeName);
}
public static void main(String[] args) {
// 生成随机数进行测试
Map resMap = new HashMap<>();
for (int i = 0; i < 100000; i++) {
Integer widgetId = i;
String group = getServer(widgetId.toString());
if (resMap.containsKey(group)) {
resMap.put(group, resMap.get(group) + 1);
} else {
resMap.put(group, 1);
}
}
resMap.forEach(
(k, v) -> {
System.out.println("group " + k + ": " + v + "(" + v/100000.0D +"%)");
}
);
}
}
在上面的代码中,我给每个节点增加了1000个虚拟节点,测试结果如下:
group 192.168.0.2:111: 18354(18.354%)
group 192.168.0.1:111: 20062(20.062%)
group 192.168.0.4:111: 20749(20.749%)
group 192.168.0.3:111: 20116(20.116%)
group 192.168.0.0:111: 20719(20.719%)
可以看到负载已经基本均衡了。我们试一下删除和新增节点的情况:
private static void refreshHashCircle() {
// 当集群变动时,刷新hash环,其余的集群在hash环上的位置不会发生变动
virtualNodes.clear();
for (String realGroup: realGroups) {
for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {
String virtualNodeName = getVirtualNodeName(realGroup, i);
int hash = HashUtil.getHash(virtualNodeName);
System.out.println("[" + virtualNodeName + "] launched @ " + hash);
virtualNodes.put(hash, virtualNodeName);
}
}
}
private static void addGroup(String identifier) {
realGroups.add(identifier);
refreshHashCircle();
}
private static void removeGroup(String identifier) {
int i = 0;
for (String group:realGroups) {
if (group.equals(identifier)) {
realGroups.remove(i);
}
i++;
}
refreshHashCircle();
}
测试结果如下:
running the normal test.
group 192.168.0.2:111: 19144(19.144%)
group 192.168.0.1:111: 20244(20.244%)
group 192.168.0.4:111: 20923(20.923%)
group 192.168.0.3:111: 19811(19.811%)
group 192.168.0.0:111: 19878(19.878%)
removed a group, run test again.
group 192.168.0.2:111: 23409(23.409%)
group 192.168.0.1:111: 25628(25.628%)
group 192.168.0.4:111: 25583(25.583%)
group 192.168.0.0:111: 25380(25.38%)
add a group, run test again.
group 192.168.0.2:111: 15524(15.524%)
group 192.168.0.7:111: 16928(16.928%)
group 192.168.0.1:111: 16888(16.888%)
group 192.168.0.4:111: 16965(16.965%)
group 192.168.0.3:111: 16768(16.768%)
group 192.168.0.0:111: 16927(16.927%)
我们可以看到删除和新增节点,一致性hash算法依然能保持良好的负载均衡。
redis中的一致性hash算法
未完,待续。。。。。睡觉!