1、通用的Load/Save函数
(*)什么是parquet文件?
Parquet是列式存储格式的一种文件类型,列式存储有以下的核心:
可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
只读取需要的列,支持向量运算,能够获取更好的扫描性能。
Parquet格式是Spark SQL的默认数据源,可通过spark.sql.sources.default配置
()通用的Load/Save函数
读取Parquet文件
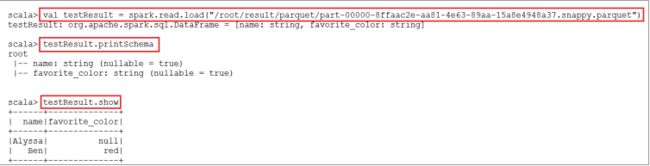
val usersDF = spark.read.load("/root/resources/users.parquet")
查询Schema和数据

查询用户的name和喜爱颜色,并保存
usersDF.select($"name",$"favorite_color").write.save("/root/result/parquet")
验证结果
(*)显式指定文件格式:加载json格式
直接加载:
val usersDF = spark.read.load("/root/resources/people.json")
会出错
val usersDF = spark.read.format("json").load("/root/resources/people.json")
(*)存储模式(Save Modes)
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。需要注意的是,这些保存模式不使用任何锁定,不是原子操作。此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。SaveMode详细介绍如下表:

Demo:
usersDF.select($"name").write.save("/root/result/parquet1")
--> 出错:因为/root/result/parquet1已经存在
usersDF.select($"name").write.mode("overwrite").save("/root/result/parquet1")
(*)将结果保存为表
usersDF.select($"name").write.saveAsTable("table1")
也可以进行分区、分桶等操作:partitionBy、bucketBy
2、Parquet文件
Parquet是一个列格式而且用于多个数据处理系统中。Spark SQL提供支持对于Parquet文件的读写,也就是自动保存原始数据的schema。当写Parquet文件时,所有的列被自动转化为nullable,因为兼容性的缘故。
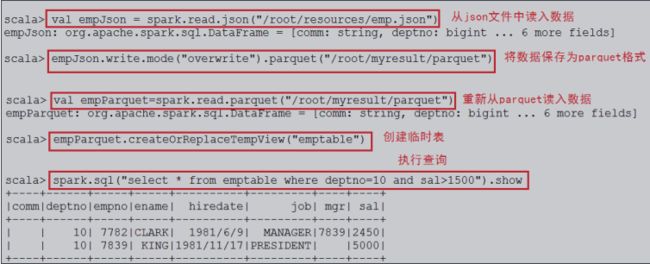
(*)案例:
读入json格式的数据,将其转换成parquet格式,并创建相应的表来使用SQL进行查询。
(*)Schema的合并:
Parquet支持Schema evolution(Schema演变,即:合并)。用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。
Demo:

3、JSON Datasets
Spark SQL能自动解析JSON数据集的Schema,读取JSON数据集为DataFrame格式。读取JSON数据集方法为SQLContext.read().json()。该方法将String格式的RDD或JSON文件转换为DataFrame。需要注意的是,这里的JSON文件不是常规的JSON格式。JSON文件每一行必须包含一个独立的、自满足有效的JSON对象。如果用多行描述一个JSON对象,会导致读取出错。读取JSON数据集示例如下:
(*)Demo1:使用Spark自带的示例文件 --> people.json文件
定义路径:
val path ="/root/resources/people.json"
读取Json文件,生成DataFrame:
val peopleDF = spark.read.json(path)
打印Schema结构信息:
peopleDF.printSchema()
创建临时视图:
peopleDF.createOrReplaceTempView("people")
执行查询
spark.sql("SELECT name FROM people WHERE age=19").show
4、使用JDBC
Spark SQL同样支持通过JDBC读取其他数据库的数据作为数据源。
Demo演示:使用Spark SQL读取Oracle数据库中的表。
启动Spark Shell的时候,指定Oracle数据库的驱动
spark-shell --master spark://spark81:7077 \\
--jars /root/temp/ojdbc6.jar \\
--driver-class-path /root/temp/ojdbc6.jar
读取Oracle 数据库中的数据
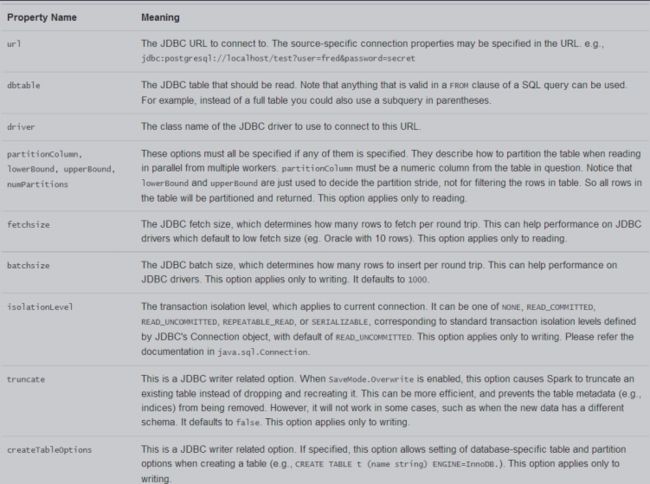
(*)方式一:
val oracleDF = spark.read.format("jdbc").
option("url","jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com").
option("dbtable","scott.emp").
option("user","scott").
option("password","tiger").
load
(*)方式二:
导入需要的类:
import java.util.Properties
定义属性:
val oracleprops = new Properties()
oracleprops.setProperty("user","scott")
oracleprops.setProperty("password","tiger")
读取数据:
val oracleEmpDF =
spark.read.jdbc("jdbc:oracle:thin:@192.168.88.101:1521/orcl.example.com",
"scott.emp",oracleprops)
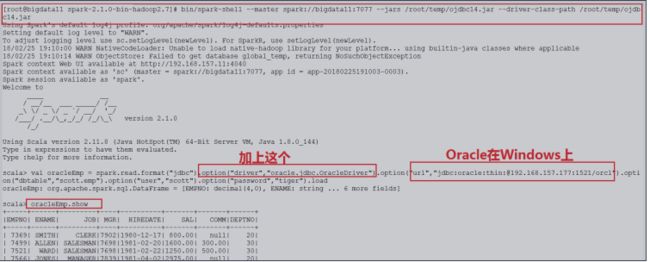
注意:下面是读取Oracle 10g(Windows上)的步骤
5、使用Hive Table
首先,搭建好Hive的环境(需要Hadoop)
配置Spark SQL支持Hive
只需要将以下文件拷贝到$SPARK_HOME/conf的目录下,即可
$HIVE_HOME/conf/hive-site.xml
$HADOOP_CONF_DIR/core-site.xml
$HADOOP_CONF_DIR/hdfs-site.xml
使用Spark Shell操作Hive
启动Spark Shell的时候,需要使用--jars指定mysql的驱动程序
创建表
spark.sql("create table src (key INT, value STRING) row format delimited
fields terminated by ','")
导入数据
spark.sql("load data local path '/root/temp/data.txt' into table src")
查询数据
spark.sql("select * from src").show
使用spark-sql操作Hive
启动spark-sql的时候,需要使用--jars指定mysql的驱动程序
操作Hive
show tables;
select * from 表;