概述
IndexFile由几个部分构成:
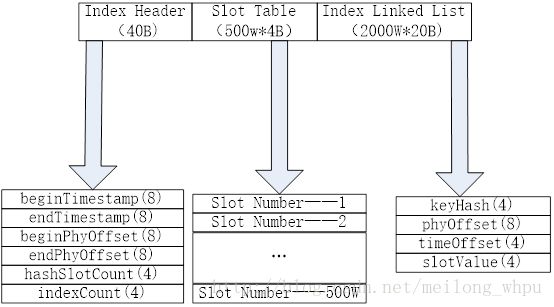
IndexHeader 文件头(40字节)
SlotTable 槽表(4字节500w记录)
Index Linked List 索引链表(20字节2000w记录)
如下图所示(参照refer)

因此一个IndexFile共计40 + 4500w+ 202000w个字节
每个部分占用空间分布如下
下面针对IndexHeader以及IndexFile两个类,对各个部分进行讲解
IndexHeader:文件头
索引文件头信息40个字节的数据组成,如下所示

各字段意义如下
beginTimestamp 8位long类型,索引文件构建第一个索引的消息落在broker的时间
endTimestamp 8位long类型,索引文件构建最后一个索引消息落broker时间
beginPhyOffset 8位long类型,索引文件构建第一个索引的消息commitLog偏移量
endPhyOffset 8位long类型,索引文件构建最后一个索引消息commitLog偏移量
hashSlotCount 4位int类型,构建索引占用的槽位数(这个值貌似没有具体作用)
indexCount 4位int类型,索引文件中构建的索引个数
源码如下
public class IndexHeader {
public static final int INDEX_HEADER_SIZE = 40;//索引文件头的大小
private static int beginTimestampIndex = 0;
private static int endTimestampIndex = 8;
private static int beginPhyoffsetIndex = 16;
private static int endPhyoffsetIndex = 24;
private static int hashSlotcountIndex = 32;
private static int indexCountIndex = 36;
private final ByteBuffer byteBuffer;
private AtomicLong beginTimestamp = new AtomicLong(0);//开始时间
private AtomicLong endTimestamp = new AtomicLong(0);//结束时间
private AtomicLong beginPhyOffset = new AtomicLong(0);//开始物理偏移
private AtomicLong endPhyOffset = new AtomicLong(0);//结束物理偏移
private AtomicInteger hashSlotCount = new AtomicInteger(0);
private AtomicInteger indexCount = new AtomicInteger(1);
public IndexHeader(final ByteBuffer byteBuffer) {
this.byteBuffer = byteBuffer;
}
//读取byteBuffer的内容到内存中
public void load() {
this.beginTimestamp.set(byteBuffer.getLong(beginTimestampIndex));
this.endTimestamp.set(byteBuffer.getLong(endTimestampIndex));
this.beginPhyOffset.set(byteBuffer.getLong(beginPhyoffsetIndex));
this.endPhyOffset.set(byteBuffer.getLong(endPhyoffsetIndex));
this.hashSlotCount.set(byteBuffer.getInt(hashSlotcountIndex));
this.indexCount.set(byteBuffer.getInt(indexCountIndex));
if (this.indexCount.get() <= 0) {
this.indexCount.set(1);
}
}
/**
* 更新header的各个记录
*/
public void updateByteBuffer() {
this.byteBuffer.putLong(beginTimestampIndex, this.beginTimestamp.get());
this.byteBuffer.putLong(endTimestampIndex, this.endTimestamp.get());
this.byteBuffer.putLong(beginPhyoffsetIndex, this.beginPhyOffset.get());
this.byteBuffer.putLong(endPhyoffsetIndex, this.endPhyOffset.get());
this.byteBuffer.putInt(hashSlotcountIndex, this.hashSlotCount.get());
this.byteBuffer.putInt(indexCountIndex, this.indexCount.get());
}
public long getBeginTimestamp() {
return beginTimestamp.get();
}
public void setBeginTimestamp(long beginTimestamp) {
this.beginTimestamp.set(beginTimestamp);
this.byteBuffer.putLong(beginTimestampIndex, beginTimestamp);
}
public long getEndTimestamp() {
return endTimestamp.get();
}
public void setEndTimestamp(long endTimestamp) {
this.endTimestamp.set(endTimestamp);
this.byteBuffer.putLong(endTimestampIndex, endTimestamp);
}
public long getBeginPhyOffset() {
return beginPhyOffset.get();
}
public void setBeginPhyOffset(long beginPhyOffset) {
this.beginPhyOffset.set(beginPhyOffset);
this.byteBuffer.putLong(beginPhyoffsetIndex, beginPhyOffset);
}
public long getEndPhyOffset() {
return endPhyOffset.get();
}
public void setEndPhyOffset(long endPhyOffset) {
this.endPhyOffset.set(endPhyOffset);
this.byteBuffer.putLong(endPhyoffsetIndex, endPhyOffset);
}
public AtomicInteger getHashSlotCount() {
return hashSlotCount;
}
public void incHashSlotCount() {
int value = this.hashSlotCount.incrementAndGet();
this.byteBuffer.putInt(hashSlotcountIndex, value);
}
public int getIndexCount() {
return indexCount.get();
}
//对应的索引文件记录的索引个数+1
public void incIndexCount() {
int value = this.indexCount.incrementAndGet();
this.byteBuffer.putInt(indexCountIndex, value);
}
}
注意load,updateByteBuffer,incHashSlotCount,incIndexCount函数即可
***注意indexCount默认是1,不是0,下面讲IndexFile会用###
IndexFile
这个类里面包含了SlotTable 以及 Index Linked List两个部分,先针对这两个部分进行讲解
逻辑意义
SlotTable
默认有500w个槽(可以理解为hash到这500w个槽中),每个槽占4个字节,也就是一个int值,这个int值范围是[1,2000w],2000w是默认的索引文件数量。
每个槽中记录的值的是什么:这一个slot存放的最新的索引,下标是几(从1开始,到默认的2000w)
比如说第5个槽,之前放了第20个记录,slotTable中第5个槽记录的值就是20
之后第22条记录也hash到了第5个槽,那么slotTable第5个槽记录的值就变成22
Index Linked List
索引链表,默认2000w条记录,每一条记录占位20字节
20字节构成如下:
keyHash: 4位,int值,key的hash值
phyOffset:8位,long值,索引消息commitLog偏移量
timeDiff: 4位,int值,索引存储的时间与IndexHeader的beginTimestamp时间差(这是为了节省空间)
slotValue:4位,int值,索引对应slot的上一条索引的下标(据此完成一条向老记录的链表)
源码讲解
属性
private static final Logger log = LoggerFactory.getLogger(LoggerName.STORE_LOGGER_NAME);
private static int hashSlotSize = 4;//每一个槽信息含4字节,即该slot对应的count数
private static int indexSize = 20;//每一个索引信息占据20字节
private static int invalidIndex = 0;//第0个索引信息是invalid的
private final int hashSlotNum;//hash槽的个数,默认5million
private final int indexNum;//最多记录的索引条数,默认2千万
private final MappedFile mappedFile;
private final FileChannel fileChannel;//没有用到
private final MappedByteBuffer mappedByteBuffer;
private final IndexHeader indexHeader;//索引头
这里注意invalidIndex是0表示无效索引下标,前面讲IndexHeader#indexCount是1,这个用于判断特定位置存放索引下标时,是否有效
方法
get,destroy相关函数省略
构造函数
/**
* 创建一个IndexFile
* @param fileName 文件名
* @param hashSlotNum hash槽的个数,默认5million
* @param indexNum 最多记录的索引条数,默认2千万
* @param endPhyOffset 开始物理偏移
* @param endTimestamp 开始的时间戳
* @throws IOException
*/
public IndexFile(final String fileName, final int hashSlotNum, final int indexNum,
final long endPhyOffset, final long endTimestamp) throws IOException {
int fileTotalSize =
IndexHeader.INDEX_HEADER_SIZE + (hashSlotNum * hashSlotSize) + (indexNum * indexSize);
this.mappedFile = new MappedFile(fileName, fileTotalSize);
this.fileChannel = this.mappedFile.getFileChannel();
this.mappedByteBuffer = this.mappedFile.getMappedByteBuffer();
this.hashSlotNum = hashSlotNum;
this.indexNum = indexNum;
ByteBuffer byteBuffer = this.mappedByteBuffer.slice();
this.indexHeader = new IndexHeader(byteBuffer);
if (endPhyOffset > 0) {//设置物理偏移
this.indexHeader.setBeginPhyOffset(endPhyOffset);
this.indexHeader.setEndPhyOffset(endPhyOffset);
}
if (endTimestamp > 0) {//设置时间
this.indexHeader.setBeginTimestamp(endTimestamp);
this.indexHeader.setEndTimestamp(endTimestamp);
}
}
因为是新创建,所以开始结束时间,开始结束物理偏移一起设置了
后续更新时,会更新结束的物理偏移,时间
load
加载IndexHeader,读取取byteBuffer的内容到内存中
public void load() {
this.indexHeader.load();
}
flush
将内存中的数据更新ByteBuffer,持久化IndexHeader
public void flush() {
long beginTime = System.currentTimeMillis();
if (this.mappedFile.hold()) {//引用+1
this.indexHeader.updateByteBuffer();
this.mappedByteBuffer.force();//刷到磁盘
this.mappedFile.release();//释放引用
log.info("flush index file eclipse time(ms) " + (System.currentTimeMillis() - beginTime));
}
}
isWriteFull
是否写满了,就是已经写的索引数是否超过了指定的索引数(2千万)
public boolean isWriteFull() {
return this.indexHeader.getIndexCount() >= this.indexNum;
}
isTimeMatched
//[begin,end]时间与 [indexHeader.getBeginTimestamp(), this.indexHeader.getEndTimestamp()]时间有重叠
public boolean isTimeMatched(final long begin, final long end) {
boolean result = begin < this.indexHeader.getBeginTimestamp() && end > this.indexHeader.getEndTimestamp();
result = result || (begin >= this.indexHeader.getBeginTimestamp() && begin <= this.indexHeader.getEndTimestamp());
result = result || (end >= this.indexHeader.getBeginTimestamp() && end <= this.indexHeader.getEndTimestamp());
return result;
}
indexKeyHashMethod
获取key的hash值(int),转成绝对值
public int indexKeyHashMethod(final String key) {
int keyHash = key.hashCode();
int keyHashPositive = Math.abs(keyHash);
if (keyHashPositive < 0)
keyHashPositive = 0;
return keyHashPositive;
}
putKey
存放一条索引消息,更新IndexHeader,slotTable,Index Linked List三个记录
/**
* 写入索引消息
* @param key 是 topic-key值
* @param phyOffset 物理偏移
* @param storeTimestamp 时间戳
* @return
**/
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
if (this.indexHeader.getIndexCount() < this.indexNum) {//还没写满
int keyHash = indexKeyHashMethod(key);//key的hash值
int slotPos = keyHash % this.hashSlotNum;//放在哪个槽
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;//槽对应的信息在文件中的位置
FileLock fileLock = null;
try {
// fileLock = this.fileChannel.lock(absSlotPos, hashSlotSize,
// false);
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);//获取该槽记录的key在该文件的第几个字节
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()) {
slotValue = invalidIndex;
}
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();//timeDiff是相对header的beginTime的偏移
timeDiff = timeDiff / 1000;
if (this.indexHeader.getBeginTimestamp() <= 0) {
timeDiff = 0;
} else if (timeDiff > Integer.MAX_VALUE) {
timeDiff = Integer.MAX_VALUE;
} else if (timeDiff < 0) {
timeDiff = 0;
}
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;//索引该放在文件的哪个字节
/**
* 索引信息:
* 先是4字节,keyHash值
* 再4字节,是commitLog的物理偏移
* 再8字节,是时间戳
* 再4字节,槽位信息,代表该槽位上一个key在文件中的位置(即向前的链表)
*/
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);//记录同一个槽位的上一个key的位置(向前的链表)
//槽位信息,记录该槽最新key在所有索引信息中的下标
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());//IndexCount默认从1开始的,所以这里就是槽位表记录最新key的位置
if (this.indexHeader.getIndexCount() <= 1) {//第一条索引,记录开始的物理偏移,以及时间
this.indexHeader.setBeginPhyOffset(phyOffset);
this.indexHeader.setBeginTimestamp(storeTimestamp);
}
this.indexHeader.incHashSlotCount();//槽的数量+1,这个slotCount并没有实际作用,随便写
this.indexHeader.incIndexCount();//索引文件中的索引个数+1
this.indexHeader.setEndPhyOffset(phyOffset);
this.indexHeader.setEndTimestamp(storeTimestamp);
return true;
} catch (Exception e) {
log.error("putKey exception, Key: " + key + " KeyHashCode: " + key.hashCode(), e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
}
} else {
log.warn("Over index file capacity: index count = " + this.indexHeader.getIndexCount()
+ "; index max num = " + this.indexNum);
}
return false;
}
具体步骤见思考
selectPhyOffset
根据key找到slot对应的整个列表,找到keyHash一样且存储时间在给定的[begin,end]范围内的索引列表(最多maxNum条,从新到旧),返回他们的物理偏移
/**
*
* @param phyOffsets 物理偏移列表,用于返回
* @param key 关键字
* @param maxNum phyOffsets最多保存这么多条记录就返回
* @param begin 开始时间戳
* @param end 结束时间戳
* @param lock:没有用
*/
public void selectPhyOffset(final List phyOffsets, final String key, final int maxNum,
final long begin, final long end, boolean lock) {
if (this.mappedFile.hold()) {
int keyHash = indexKeyHashMethod(key);
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
FileLock fileLock = null;
try {
if (lock) {
// fileLock = this.fileChannel.lock(absSlotPos,
// hashSlotSize, true);
}
int slotValue = this.mappedByteBuffer.getInt(absSlotPos);//获取对应槽的最新的key的下标
// if (fileLock != null) {
// fileLock.release();
// fileLock = null;
// }
if (slotValue <= invalidIndex || slotValue > this.indexHeader.getIndexCount()
|| this.indexHeader.getIndexCount() <= 1) {//key对应的槽就没有合理记录
} else {
for (int nextIndexToRead = slotValue; ; ) {//遍历链表一样的结构
if (phyOffsets.size() >= maxNum) {//最多纪录maxNum个
break;
}
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ nextIndexToRead * indexSize;//根据key的下标找到在文件中的位置
int keyHashRead = this.mappedByteBuffer.getInt(absIndexPos);
long phyOffsetRead = this.mappedByteBuffer.getLong(absIndexPos + 4);
long timeDiff = (long) this.mappedByteBuffer.getInt(absIndexPos + 4 + 8);
int prevIndexRead = this.mappedByteBuffer.getInt(absIndexPos + 4 + 8 + 4);//链表,找到该slot前一个key的下标
if (timeDiff < 0) {//不断地找更老的记录,timeDiff会越来越小,
break;
}
timeDiff *= 1000L;
long timeRead = this.indexHeader.getBeginTimestamp() + timeDiff;//根据基准时间戳以及 timeDiff,得到索引存储的时间
boolean timeMatched = (timeRead >= begin) && (timeRead <= end);//存储时间戳在[begin,end]内
if (keyHash == keyHashRead && timeMatched) {//原有hash值匹配,
phyOffsets.add(phyOffsetRead);
}
if (prevIndexRead <= invalidIndex
|| prevIndexRead > this.indexHeader.getIndexCount()
|| prevIndexRead == nextIndexToRead || timeRead < begin) {
break;
}//链表循环,已经找到了最老的索引了,可以break了
nextIndexToRead = prevIndexRead;//遍历到同slot的前一个key中
}
}
} catch (Exception e) {
log.error("selectPhyOffset exception ", e);
} finally {
if (fileLock != null) {
try {
fileLock.release();
} catch (IOException e) {
log.error("Failed to release the lock", e);
}
}
this.mappedFile.release();
}
}
}
思考
主要内容
主要理解IndexFile的三个构成部分
主要理解putKey函数以及selectPhyOffset函数
为什么说IndexHeader#hashSlotCount没用
因为incHashSlotCount和incIndexCount在IndexFile类中是一起调用的,并不是真正体现占有slot数量的
slotTable中500项,每项4字节,这4字节存储的值的意义是什么
该槽最新记录的索引的下标,从1到200w
IndexFile中的链表结构的形成
上面已经讲过,这里再讲一下,
slotTable记录该槽最新索引的下标
在每一条索引的记录中,记录slotValue代表同一个槽的上一个索引的下标。
这两点,就能根据槽的值,从最新向最老的索引进行查找
putKey步骤总结
* 先根据key找到hash值再%hashSlotNum, 得到应该放入哪个槽
* 去slotTable找到槽的位置,获取该槽最新的索引的下标,不合理就置0(invalidIndex)
* 记录时间戳与 IndexHeader begin时间的差
* 找到这个索引应该存在哪个位置,依次写下keyHash,phyOffset,timeDiff,slotValue
* slotTable对应槽位置更新值为最新的索引值
* 更新count,结束时间戳,结束物理偏移等值
代码中各种偏移
IndexFile文件中,依次是
IndexHeader 文件头(40字节)
SlotTable 槽表(4字节500w记录)
Index Linked List 索引链表(20字节2000w记录)
再去看代码,就知道各种偏移是干嘛的了
index下标是1开始的
IndexHeader#indexCount是1
所以IndexFile中的invalidIndex是0
问题
selectPhyOffset一定准确吗
代码中,判断的语句是
keyHash == keyHashRead && timeMatched
这里keyHash是String key的一个hash值
如果不同的key的hash值一样,然后后面时间戳也匹配,怎么办?
refer
http://blog.csdn.net/quhongwei_zhanqiu/article/details/39153195
http://blog.csdn.net/meilong_whpu/article/details/76921583
IndexFileTest 自带测试类