【Transformer】DPT: Vision Transformer for Dense Prediction
文章目录
-
- 一、背景和动机
- 二、方法
-
- 2.1 Transformer encoder
- 2.2 Convolutional decoder
- 2.3 处理不同输入大小
- 三、效果
-
- 3.1 单目深度估计
- 3.2 语义分割

论文链接: https://arxiv.org/pdf/2103.13413.pdf
代码链接: https://github.com/intel-isl/DPT
一、背景和动机
现有的密集预测模型大都是基于卷积神经网络的模型,基本上都把网络分为两部分:
- encoder:也就是 backbone
- decoder:也就是 head
关于密集预测的研究,很多都集中在对解码头的改进中,backbone的结构没有大的突破,如果 encoder 中丢了很多信息,那么 decoder 再好也无法将其恢复。
卷积网络会通过下采样的方式来增大感受野并提取多尺度的图像特征,但是下采样会丢失掉图像的一些信息,decoder 也难以恢复。这些信息对分类等粗粒度的任务可能没那么重要,但对密集预测任务比较重要。
当然也有一些方法对这种信息丢失的问题做了改进,如使用高分辨率的输入,使用膨胀卷积来增大感受野,在 encoder 和 decoder 之间使用跳连等。但这些方法或者需要很多的卷积堆叠,或者需要很大的计算量。
所以,本文中,作者提出了一种 dense prediction transformer(DPT),是一种基于 transformer 的 encoder-decoder 结构的密集预测结构。本文中,作者基于深度预测和语义分割来进行实验对比。
二、方法
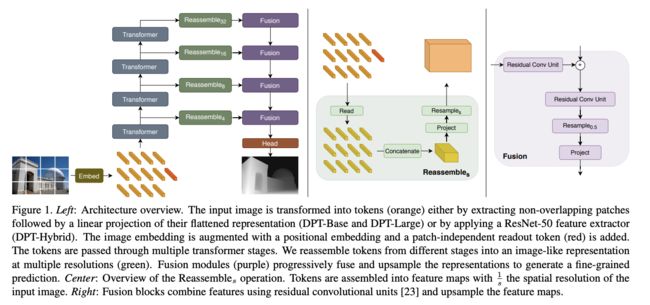
DPT 的总体结构如图1左侧所示,作者使用 ViT 作为 backbone。
2.1 Transformer encoder
作者使用 ViT 作为 encoder 结构,把原图切分为不重叠的 token,然后使用 MHSA 获得这些经过编码的 token 之间的 attention。
transformer 处理后,token 的数量是不变的,且它们之间的 attention 是一对一的,每个 token 都可以获得和其他 token 的关系,能够获得全局感受野下的特征,空间分辨率也不会改变。
作者使用三种 ViT 变体进行实验:
- base:每个 patch 被拉平为 768 维
- large:每个 patch 被拉平为 1024 维,
- hybrid:将 ResNet50 的输出特征作为输入
- patch size p = 16 p=16 p=16
由于patch embedding 会将每个patch拉平至比其像素维度大的维度,这就表示 embedding 过程能够学习到一下有益于任务的特征。
2.2 Convolutional decoder
Decoder 过程是为了把这一系列的 token 转换成不同分辨率的 image-like 特征表达,然后将这些特征聚合起来进行最终的密集预测。
作者提出了一个 three-stage Reassemble operation 来从 transformer encoder 的任意层恢复 image-like 的特征表达:
![]()
- s s s:是恢复的特征表达相对于原始输入图像的比率
- D ^ \hat{D} D^:输出特征维度
主要过程:
① 首先,将 token 从 N p + 1 N_p+1 Np+1 映射为 N p N_p Np
该操作是为了处理 readout token(类似于 ViT 中的 cls token)
![]()
该 token 是为了分类而用的,能够提取全局信息,作者验证了三种不同的处理方式:
- 直接忽略该 readout token
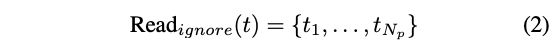
- 将 readout token 加在其他token上
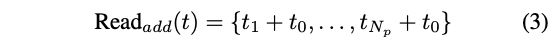
- 将 readout token 直接 concat 到其他 token 上,然后再将其影射到 D 维
结果如表 7 所示:

② 之后,根据初始 patch 的position,将其分别放到对应的位置上,得到 image-like 的特征表达
③ 最后,使用 1x1的卷积改变通道,后面接一个 3x3 的卷积进行 resize
![]()
如何提取多尺度:
作者从 4 个不同的 stage 提取得到了 4 种不同分辨率的特征图。浅层的 stage 映射到大分辨率的特征图。
- ViT Large:从 {5, 12, 18, 24} stage 来提取 token
- ViT Base:从 {3, 6, 9 ,12} stage 来提取 token
- ViT Hybrid:从 {9, 12} stage 来提取 token
- D ^ = 256 \hat{D}=256 D^=256
如何聚合多尺度的特征:
作者使用 RefineNet-based 特征融合block(图1右侧),然后在每个 fusion stage 逐渐进行2倍上采样,最终的分辨率为原始分辨率的 1/2,不同任务的 head 是不同的,如图 1 所示。
2.3 处理不同输入大小
类似于全卷积网络,DPT 能够接受不同大小的输入。
假设图像大小除以 p,embedding 过程会产生 N p N_p Np 个 tokens, N p N_p Np 会根据图像大小的不同而变化。transformer 可以处理不同尺寸的输入序列,但position是与图像大小有关的,作者参照 ViT 的方法,即使用插值的方法,将 position embedding 线性影射到需要的大小。
三、效果
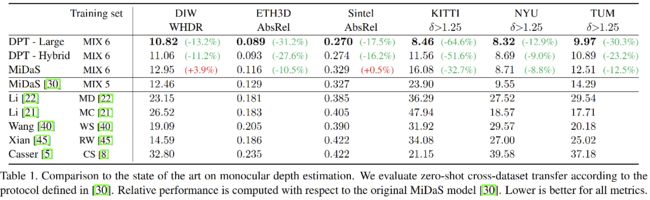
3.1 单目深度估计

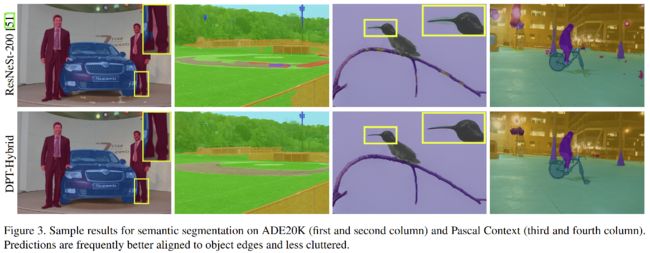
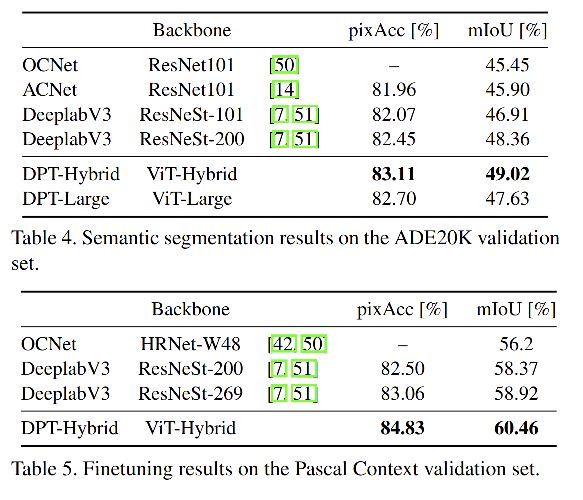
3.2 语义分割