树与二叉树
树
有许多逻辑关系并不是简单的线性关系,在实际场景中,常常存在着一对多,甚至是多对多的情况。其中树和图就是典型的非线性数据结构,我们首先讲一讲树的知识。
什么是树呢?在现实生活中有很多体现树的逻辑的例子。例如你家的“家谱”,就是一个“树”。再如企业里的职级关系,也是一个“树”。

除人与人之间的关系之外,许多抽象的东西也可以成为一个“树”,如一本书的目录。

以上这些例子有什么共同点呢?为什么可以称它们为“树”呢?因为它们都像自然界中的树一样,从同一个“根”衍生出许多“枝干”,再从每一个“枝干”衍生出许多更小的“枝干”,最后衍生出更多的“叶子”。

树(英语:tree)是一种抽象数据类型(ADT)或是实作这种抽象数据类型的数据结构,用来模拟具有树状结构性质的数据集合。它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点:
- 每个节点有零个或多个子节点;
- 没有父节点的节点称为根节点;
- 每一个非根节点有且只有一个父节点;
- 除了根节点外,每个子节点可以分为多个不相交的子树;
下面这张图,就是一个标准的树结构。
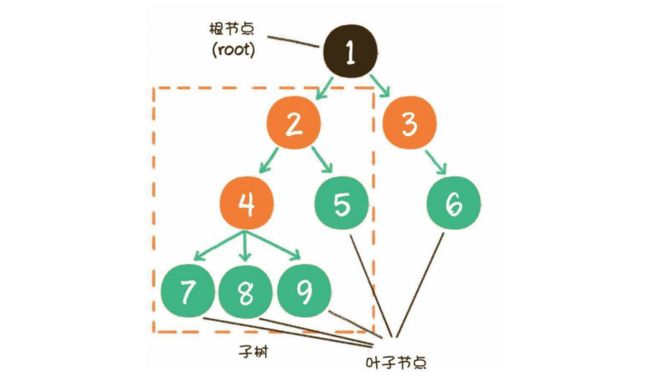
在上图中,节点1是根节点(root);节点5、6、7、8是树的末端,没有“孩子”,被称为叶子节点(leaf)。图中的虚线部分,是根节点1的其中一个子树。
同时,树的结构从根节点到叶子节点,分为不同的层级。从一个节点的角度来看,它的上下级和同级节点关系如下。

在上图中,节点4的上一级节点,是节点4的父节点(parent);从节点4衍生出来的节点,是节点4的孩子节点(child);和节点4同级,由同一个父节点衍生出来的节点,是节点4的兄弟节点(sibling)。
树的最大层级数,被称为树的高度或深度。显然,上图这个树的高度是4。
树的术语
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙;
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
树的种类
- | 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- | 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
- || 二叉树:每个节点最多含有两个子树的树称为二叉树;
- ||| 完全二又树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二又树的定义是所有叶节点都在最底层的完全二叉树;
- ||| 平衡二又树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
- ||| 排序二又树(二又查找树(英语:Binary Search Tree),也称二又搜索树、有序二叉树);
- || 霍夫曼树(用于信息编码):带权路径最短的二又树称为哈夫曼树或最优二叉树;
- || B树:一种对读写操作进行优化的自平衡的二又查找树,能够保持数据有序,拥有多余两个子树。
- || 二叉树:每个节点最多含有两个子树的树称为二叉树;
树的存储与表示
顺序存储:将数据结构存储在固定的数组中,然在遍历速度上有一定的优势,但因所占空间比较大,是非主流二叉树。二又树通常以链式存储。

链式存储:

由于对节点的个数无法掌握,常见树的存储表示都转换成二叉树进行处理,子节点个数最多为2
常见的一些树的应用场景
- xml,html等,那么编写这些东西的解析器的时候,不可避免用到树
- 路由协议就是使用了树的算法
- mysql数据库索引
- 文件系统的目录结构
- 所以很多经典的Al算法其实都是树搜索,此外机器学习中的decision tree也是树结构
二叉树
二叉树(binary tree)是树的一种特殊形式。二叉,顾名思义,这种树的每个节点最多有2个孩子节点。注意,这里是最多有2个,也可能只有1个,或者没有孩子节点。
二叉树的结构如图所示。

二叉树节点的两个孩子节点,一个被称为左孩子(left child),一个被称为右孩子(right child)。这两个孩子节点的顺序是固定的,就像人的左手就是左手,右手就是右手,不能够颠倒或混淆。
此外,二叉树还有两种特殊形式,一个叫作满二叉树,另一个叫作完全二叉树。
一个二叉树的所有非叶子节点都存在左右孩子,并且所有叶子节点都在同一层级上,那么这个树就是满二叉树。

简单点说,满二叉树的每一个分支都是满的。
什么又是完全二叉树呢?完全二叉树的定义很有意思。
对一个有n个节点的二叉树,按层级顺序编号,则所有节点的编号为从1到n。如果这个树所有节点和同样深度的满二叉树的编号为从1到n的节点位置相同,则这个二叉树为完全二叉树。

在上图中,二叉树编号从1到12的12个节点,和前面满二叉树编号从1到12的节点位置完全对应。因此这个树是完全二叉树。
完全二叉树的条件没有满二叉树那么苛刻:满二叉树要求所有分支都是满的;而完全二叉树只需保证最后一个节点之前的节点都齐全即可。
二叉树可以用哪些物理存储结构来表达呢?
- 链式存储结构

链式存储是二叉树最直观的存储方式。
上一次讲过链表,链表是一对一的存储方式,每一个链表节点拥有data变量和一个指向下一节点的next指针。
而二叉树稍微复杂一些,一个节点最多可以指向左右两个孩子节点,所以二叉树的每一个节点包含3部分。
- 存储数据的data变量
- 指向左孩子的left指针
- 指向右孩子的right指针
- 数组

使用数组存储时,会按照层级顺序把二叉树的节点放到数组中对应的位置上。如果某一个节点的左孩子或右孩子空缺,则数组的相应位置也空出来。
为什么这样设计呢?因为这样可以更方便地在数组中定位二叉树的孩子节点和父节点。
假设一个父节点的下标是parent,那么它的左孩子节点下标就是2×parent +1;右孩子节点下标就是2×parent + 2。
反过来,假设一个左孩子节点的下标是leftChild,那么它的父节点下标就是(leftChild-1)/ 2。
假如节点4在数组中的下标是3,节点4是节点2的左孩子,节点2的下标可以直接通过计算得出。
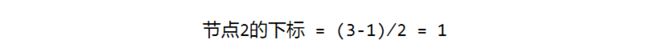
显然,对于一个稀疏的二叉树来说,用数组表示法是非常浪费空间的。
什么样的二叉树最适合用数组表示呢?我们后面即将学到的二叉堆,一种特殊的完全二叉树,就是用数组来存储的。
用队列实现二叉树
class Node(object):
def __init__(self,item):
self.elem = item
self.left_child = None
self.right_child = None
class Tree(object):
def __init__(self):
self.root = None
def add(self,item):
node = Node(item)
if self.root is None:
self.root = node
return
queue = [self.root]
while queue :
cur_node =queue.pop(0)
if cur_node.left_child is None:
cur_node.left_child = node
return
else:
queue.append(cur_node.left_child)
if cur_node.right_child is None:
cur_node.right_child = node
return
else:
queue.append(cur_node.right_child)
二叉树的遍历
在计算机程序中,遍历本身是一个线性操作。所以遍历同样具有线性结构的数组或链表,是一件轻而易举的事情。


反观二叉树,是典型的非线性数据结构,遍历时需要把非线性关联的节点转化成一个线性的序列,以不同的方式来遍历,遍历出的序列顺序也不同。

那么,二叉树都有哪些遍历方式呢?
从节点之间位置关系的角度来看,二叉树的遍历分为4种。
-
前序遍历
-
中序遍历
-
后序遍历
-
层序遍历
从更宏观的角度来看,二叉树的遍历归结为两大类。
- 深度优先遍历(前序遍历、中序遍历、后序遍历)。
- 广度优先遍历(层序遍历)。
广度优先遍历
层序遍历,顾名思义,就是二叉树按照从根节点到叶子节点的层次关系,一层一层横向遍历各个节点。

上图就是一个二叉树的层序遍历,每个节点左侧的序号代表该节点的输出顺序。
可是,二叉树同一层次的节点之间是没有直接关联的,如何实现这种层序遍历呢?这里同样需要借助一个数据结构来辅助工作,这个数据结构就是队列。
详细遍历步骤如下。
- 根节点1进入队列。

- 节点1出队,输出节点1,并得到节点1的左孩子节点2、右孩子节点3。让节点2和节点3入队。

- 节点2出队,输出节点2,并得到节点2的左孩子节点4、右孩子节点5。让节点4和节点5入队。

- 节点3出队,输出节点3,并得到节点3的右孩子节点6。让节点6入队。

- 节点3出队,输出节点3,并得到节点3的右孩子节点6。让节点6入队。

- 节点5出队,输出节点5,由于节点5同样没有孩子节点,所以没有新节点入队。
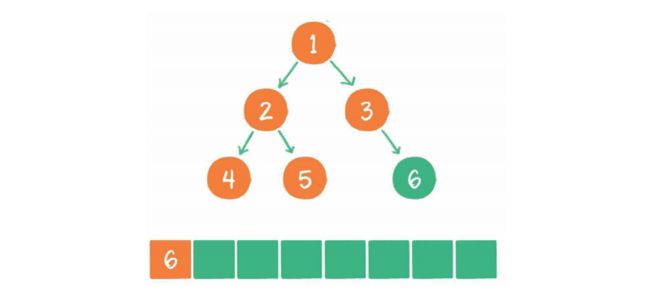
- 节点6出队,输出节点6,节点6没有孩子节点,没有新节点入队。

到此为止,所有的节点都遍历输出完毕。
def breadth_travel(self):
"""利用队列实现二叉树的层次遍历"""
if self.root is None:
return
queue = [self.root]
while queue:
cur_node = queue.pop(0)
print(cur_node.elem)
if cur_node.left_child is not None:
queue.append(cur_node.left_child)
if cur_node.right_child is not None:
queue.append(cur_node.right_child)
深度优先遍历
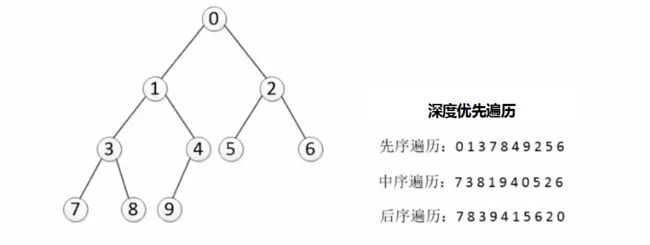
- 二叉树的前序遍历,输出顺序是根节点、左子树、右子树
- 二叉树的中序遍历,输出顺序是左子树、根节点、右子树
- 二叉树的后序遍历,输出顺序是左子树、右子树、根节点
def preorder(self,node):
"""先序遍历"""
if node is None:
return
print(node.elem,end=' ')
self.preorder(node.left_child)
self.preorder(node.right_child)
def inorder(self,node):
"""中序遍历"""
if node is None:
return
self.inorder(node.left_child)
print(node.elem, end=' ')
self.inorder(node.right_child)
def postorder(self,node):
"""后序遍历"""
if node is None:
return
self.postorder(node.left_child)
self.postorder(node.right_child)
print(node.elem, end=' ')
由遍历结果反推一棵树
-
确定根,确定左子树,确定右子树(根据前序或后序联合中序推导得出)
-
在左子树中递归
-
在右子树中递归
-
打印当前根