docker swarm是docker官方提供的一套容器编排系统。它的架构如下:

1. swarm节点
swarm是一系列节点的集合,而节点可以是一台裸机或者一台虚拟机。一个节点能扮演一个或者两个角色,manager或者worker。
1.1 manager节点
Docker Swarm集群需要至少一个manager节点,节点之间使用Raft consensus protocol进行协同工作。
通常,第一个启用docker swarm的节点将成为leader,后来加入的都是follower。当前的leader如果挂掉,剩余的节点将重新选举出一个新的leader。
每一个manager都有一个完整的当前集群状态的副本,可以保证manager的高可用。
1.2 worker节点
worker节点是运行实际应用服务的容器所在的地方。理论上,一个manager节点也能同时成为worker节点,但在生产环境中,我们不建议这样做。
worker节点之间,通过control plane进行通信,这种通信使用gossip协议,并且是异步的。
2. stacks, services, and tasks
集群中经常谈到的stacks, services, tasks,他们之间的关系。
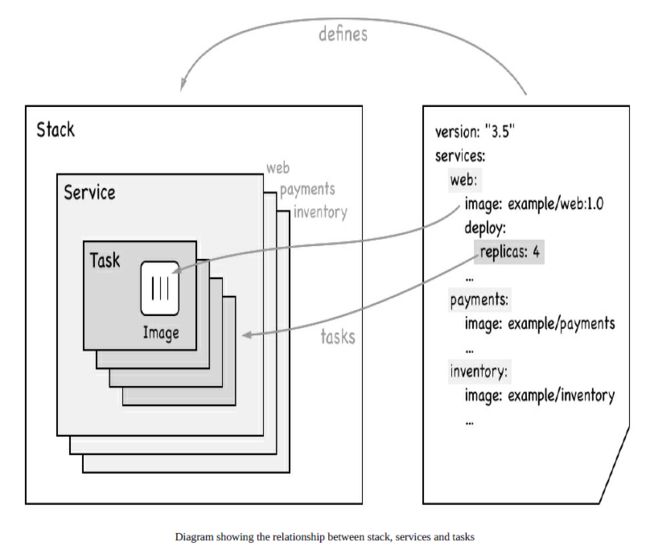
下面简单解释一下这三者的含义:
2.1 services
swarm service是一个抽象的概念,它只是一个对运行在swarm集群上的应用服务,所期望状态的描述。它就像一个描述了下面物品的清单列表一样:
- 服务名称
- 使用哪个镜像来创建容器
- 要运行多少个副本
- 服务的容器要连接到哪个网络上
- 应该映射哪些端口
2.2 task
在Docker Swarm中,task是一个部署的最小单元,task与容器是一对一的关系。
2.3 stack
stack是描述一系列相关services的集合。我们通过在一个YAML文件中来定义一个stack。
3. 多主机网络
在前面的章节中,我们学习过单主机网络,那个时候所有的容器都运行在一个docker host上,他们之间的通信一般使用本地的bridge网络即可。
在Swarm集群中,我们使用前面也简单提到过的overlay network driver来让位于不同主机间的容器进行通信。网络模式如下图:
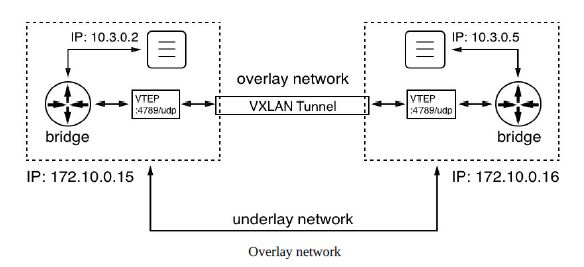
当然你也可以使用第三方提供的其他网络驱动,但对于swarm,还是推荐它自己的overlay network。
4. 实战
4.1 创建一个单一节点的swarm
创建一个docker swarm非常简单,现在假设我们只有一台服务器(裸机或者虚拟机都行)。运行命令docker swarm init,就可以创建一个swarm集群,并让它成为manager leader:
[root@node2 ~]# docker swarm init
Swarm initialized: current node (pvj7k2urt8g5k1ucsao2rpiwu) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-2121w9nkk2qsyrgg477bz2jq26iojd5u1agdfa2b0bi8wxi3rk-00octanaf09agpe9v77nsm670 10.10.10.73:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
上面也告诉了你,如何添加一个新的manager或者worker。
查看swarm node信息:
[root@node2 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
pvj7k2urt8g5k1ucsao2rpiwu * node2.xxx.com Ready Active Leader 18.06.1-ce
[root@node2 ~]# docker node inspect pvj7k2urt8g5k1ucsao2rpiwu
4.2 使用virtualbox来创建一个swarm集群
上一章Docker Machine,我们讲到过,可以使用docker machine结合virtualbox来创建多台docker虚拟机。下面我们进行实践:
之前,我们使用docker-machine create --driver virtualbox default已经创建了一台虚拟机。
[root@node2 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
default * virtualbox Running tcp://192.168.99.100:2376 v18.06.1-ce
通过上面方式创建的虚拟机,默认都将分配1G的内存。后面创建多台虚拟机时,请确保你的实验机器有足够的内存。
1、创建5台虚拟机
[root@node2 ~]# for NODE in `seq 1 5`; do docker-machine create --driver virtualbox "node-${NODE}"; done
整个过程需要一段时间,请耐心等待。创建完成后可以通过docker-machine ls查看。
[root@node2 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
default * virtualbox Running tcp://192.168.99.100:2376 v18.06.1-ce
node-1 - virtualbox Running tcp://192.168.99.101:2376 v18.06.1-ce
node-2 - virtualbox Running tcp://192.168.99.102:2376 v18.06.1-ce
node-3 - virtualbox Running tcp://192.168.99.103:2376 v18.06.1-ce
node-4 - virtualbox Running tcp://192.168.99.104:2376 v18.06.1-ce
node-5 - virtualbox Running tcp://192.168.99.105:2376 v18.06.1-ce
2、创建swarm集群
按照下面的脚本创建swarm集群,当然你也可以用命令手动逐个创建:
#!/bin/bash
# 这个脚本用于在创建了5个docker虚拟机之后,创建swarm集群。
# 集群内配置如下:node-1为manager leader,node-2和node-3为manager follower
# node-4和node-5为worker
export IP=$(docker-machine ip node-1)
#ssh登录到node-1,让他成为swarm leader
docker-machine ssh node-1 docker swarm init --advertise-addr $IP
#获取leader的token,方便后面其他主机加入
export JOIN_TOKEN=$(docker-machine ssh node-1 docker swarm join-token worker -q)
for NODE in `seq 2 5`
do
docker-machine ssh node-${NODE} docker swarm join --token ${JOIN_TOKEN} ${IP}:2377
done
#将node-2和node-3主机提权为manager
docker-machine ssh node-1 docker node promote node-2 node-3
完成后,可以在node-1上查看当前集群节点信息
[root@node2 swarm]# docker-machine ssh node-1 docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
zycyeyod3fctve54efs9oms55 * node-1 Ready Active Leader 18.06.1-ce
cwerk7kvtxybp7fgkicpgxe4y node-2 Ready Active Reachable 18.06.1-ce
l3dtf4l64z3bm5eb1sb4uuq2x node-3 Ready Active Reachable 18.06.1-ce
wg5ptfk4suctqvndjo81dqewq node-4 Ready Active 18.06.1-ce
wcog4ty7anqdixgm5n7ta8bxb node-5 Ready Active 18.06.1-ce
3、在集群上部署一个单service的stack
现在我们可以使用这5台虚拟机组成的集群,来实践一个案例了。
前面我们提到过,一个stack才是所有相关services的集合,组成一个完整的应用服务。可以通过yaml文本来定义一个stack:
version: "3.5"
services:
whoami:
image: training/whoami:latest
networks:
- test-net
ports:
- 81:8000
deploy:
replicas: 6
update_config:
parallelism: 2
delay: 10s
labels:
app: sample-app
enviroment: prod-south
networks:
test-net:
driver: overlay
解读:
- 服务的名称叫
whoami。 - 使用的镜像为
training/whoami:latest。 - 使用了一个自定的网络
test-net。 - 将主机端口81映射至容器内的8000端口。
- 运行6个副本(也就是task,也对应6个容器)
- 升级策略:每2个task为一组进行升级,且当前组升级成功后,延迟10秒才开始升级下一组。
- 定义了两个标签。
实际上,还有很多其他的设置,我们这里没有列出来,它们都有自己的默认值。
请注意,services里面各个service的名字在swarm中必须唯一。
现在,我们使用这个配置文件来部署我们的一个集群服务吧:
# 为了更直观的查看过程,我们可以登录到manager leader上进行部署
[root@node2 swarm]# docker-machine ssh node-1
# 在manager leader上创建上面的yaml文件
docker@node-1:~$ vi stack.yaml
docker@node-1:~$ docker stack deploy -c stack.yaml samle-stack
# 创建过程需要一定的时间,请耐心等待
docker@node-1:~$ docker stack ls
NAME SERVICES ORCHESTRATOR
samle-stack 1 Swarm
docker@node-1:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
mjx5rdvluyeb samle-stack_whoami replicated 6/6 training/whoami:latest *:81->8000/tcp
在docker stack deploy执行完成后,我使用docker service ls命令,刚开始在REPLICAS那一栏始终都是看到3/6,代表只启动了3个task,但是实际应该启动6个。过一段时候之后,我再次查看发现就是6个都启动了。我当时猜测,有些node可能是拉取镜像的时候超时了,导致没有完全启动,下面命令的输出也印证了我的猜测。node1、2、5都自动创建了一个新的task。
docker@node-1:~$ docker service ps samle-stack_whoami
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
35gp71dh9sgl samle-stack_whoami.1 training/whoami:latest node-4 Running Running 36 minutes ago
b79jr4suvuc2 samle-stack_whoami.2 training/whoami:latest node-5 Running Running 29 minutes ago
noferwnjjr5s \_ samle-stack_whoami.2 training/whoami:latest node-5 Shutdown Rejected 29 minutes ago "No such image: training/whoam…"
wd59fklp6ayg samle-stack_whoami.3 training/whoami:latest node-1 Running Running 29 minutes ago
z0gxnngq5ipt \_ samle-stack_whoami.3 training/whoami:latest node-1 Shutdown Rejected 29 minutes ago "No such image: training/whoam…"
zcf9x5c61a6f samle-stack_whoami.4 training/whoami:latest node-2 Running Running 29 minutes ago
lb3plbt9b3c2 \_ samle-stack_whoami.4 training/whoami:latest node-2 Shutdown Rejected 29 minutes ago "No such image: training/whoam…"
xfxk4ngiggf3 samle-stack_whoami.5 training/whoami:latest node-3 Running Running 36 minutes ago
m647fsycr4rx samle-stack_whoami.6 training/whoami:latest node-4 Running Running 36 minutes ago
查看node-1节点上运行的容器
docker@node-1:~$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
39c616331871 training/whoami:latest "/app/http" 33 minutes ago Up 33 minutes 8000/tcp samle-stack_whoami.3.wd59fklp6aygpua8289gt978l
查看服务的详细信息
docker@node-1:~$ docker service inspect samle-stack_whoami
查看services的日志:
docker@node-1:~$ docker service logs samle-stack_whoami
samle-stack_whoami.4.zcf9x5c61a6f@node-2 | Listening on :8000
samle-stack_whoami.6.m647fsycr4rx@node-4 | Listening on :8000
samle-stack_whoami.1.35gp71dh9sgl@node-4 | Listening on :8000
samle-stack_whoami.2.b79jr4suvuc2@node-5 | Listening on :8000
samle-stack_whoami.5.xfxk4ngiggf3@node-3 | Listening on :8000
samle-stack_whoami.3.wd59fklp6ayg@node-1 | Listening on :8000
下面我们来看看集群的高可用,和状态一致性(意思是集群始终会保持你所期待的样子),通过上面的输出,我们可以看到在node-4上是运行了2个容器的,我们手动的删除一个容器看看:
docker@node-4:~$ docker container rm -f samle-stack_whoami.6.m647fsycr4rxk2epx542bx8n6
samle-stack_whoami.6.m647fsycr4rxk2epx542bx8n6
我们删除的是编号为6的容器,samle-stack_whoami.6
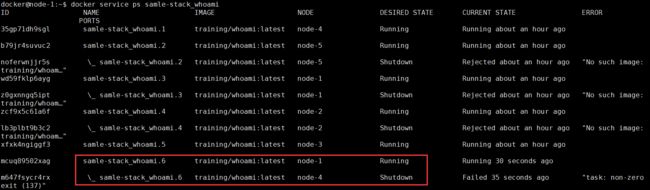
以上命令显示,在node-1上重新启用了一个新的容器,名称为:samle-stack_whoami.6。
除了像上面这样,可能某个容器出现问题。但有些时候,也有可能出现某个节点故障,我们可以用如下命令模拟节点故障:
docker-machine stop node-2
相应的node-2上的task就都会自动转移到其他主机上。
删除一个stack或者service可以使用如下命令:
docker stack rm ,将会删除整个stack以及service,还有主机上的task。
docker service rm,会删除service,还有主机上的task。
4、在集群上部署一个多service的stack
上面的示例在services中只有一个service,下面我们演示一个多service的。
stack配置文件为:
version: "3.5"
services:
web:
image: fundamentalsofdocker/ch08-web:1.0
networks:
- pets-net
ports:
- 3000:3000
deploy:
replicas: 3
db:
image: fundamentalsofdocker/ch08-db:1.0
networks:
- pets-net
volumes:
- pets-data:/var/lib/postgresql/data
volumes:
pets-data:
networks:
pets-net:
driver: overlay
实际在node-1上运行:
docker@node-1:~$ docker stack deploy -c pet_stack.yaml pets_web
Creating network pets_web_pets-net
Creating service pets_web_web
Creating service pets_web_db
docker@node-1:~$ docker stack ls
NAME SERVICES ORCHESTRATOR
pets_web 2 Swarm
docker@node-1:~$ docker stack ps pets_web
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
t4sl5hmq4xbr pets_web_db.1 fundamentalsofdocker/ch08-db:1.0 node-4 Running Running 7 minutes ago
arqpt9p3bqws pets_web_web.1 fundamentalsofdocker/ch08-web:1.0 node-2 Running Running 7 minutes ago
k05n7x67kmig \_ pets_web_web.1 fundamentalsofdocker/ch08-web:1.0 node-2 Shutdown Rejected 7 minutes ago "No such image: fundamentalsof…"
sivxrv71npj1 pets_web_web.2 fundamentalsofdocker/ch08-web:1.0 node-3 Running Running 13 minutes ago
bw2h8z3yd3p0 pets_web_web.3 fundamentalsofdocker/ch08-web:1.0 node-1 Running Running 13 minutes ago
和上一小节区别不大,下面我们验证一下web服务是否可用。
docker@node-1:~$ curl http://localhost:3000/pet

4.3 swarm的路由网络
对于上面最后一步的验证过程,我们可以看到3个web的task分别运行在node1、2、3上,但为什么能够在node-1节点上通过localhost来访问web服务,并且得到从node-2上的容器返回的结果呢?这一切都归功于swarm routing mesh,它的工作原理如下图:
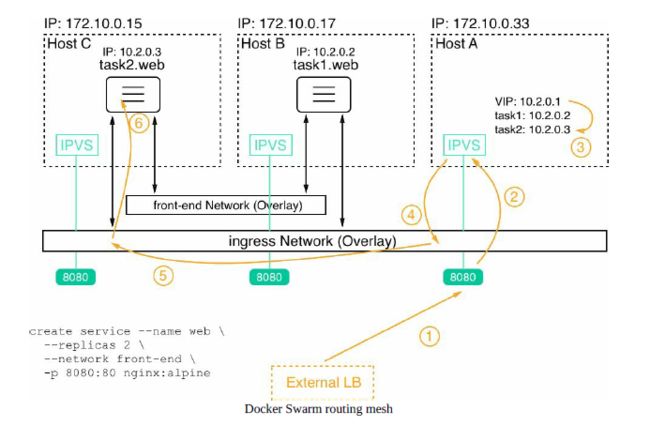
对于每一个service,docker swarm都会自动的给它分配一个virtual IP,对外暴露的也是这个VIP,当有数据请求达到VIP时,它会进行负载均衡,将请求分配到某一个实际正在运行task的节点上。