爬虫中requests模块(一)
一、requests模块介绍
1.requests模块的作用
发送http请求,获取响应数据。
2.安装
pip/pip3 install requests
3.发送get请求
- 导入requests模块
- 调用get方法,对目标url发送请求。
例:
# 调用requests模块
import requests
# 输入网址
url = 'http://www.baidu.com'
# 结果存入response
response = requests.get(url)
# 打印源码的str类型数据
print(response.text)
结果:
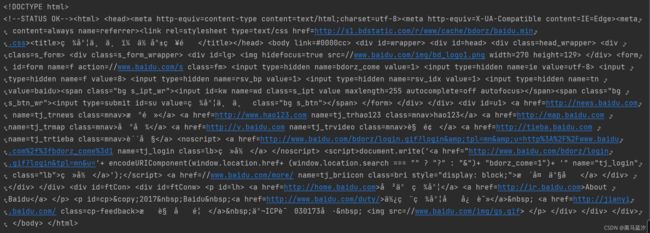
4.乱码的解决
我们可以发现上图运行结果中有一些乱码,有两种解决方案:
- encodeing设定编码格式
- 进行decode(decode默认格式utf8)解码(代码简洁,推荐)
1.可以在程序中用encoding来设定编码格式
例:
# 调用requests模块
import requests
# 输入网址
url = 'http://www.baidu.com'
# 结果存入response
response = requests.get(url)
response.encoding = 'utf8'
# 打印源码的str类型数据
print(response.text)
2.运用content.decode来解码(推荐)
例:
# 调用requests模块
import requests
# 输入网址
url = 'http://www.baidu.com'
# 结果存入response
response = requests.get(url)
# 打印源码的str类型数据
print(response.content.decode())
结果:
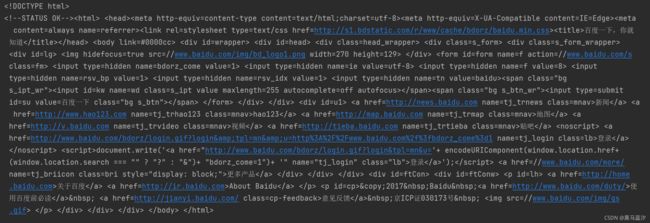
- response.text是requests模块按照chardet模块推测出的编码字符集进行解码的结果
- 网络传输的字符串都是bytes类型的,所以response.text = response.content.decode(推测出的编码字符集)
- 我们可以在网页源码中搜索charset,尝试参考该编码字符集,注意存在不准确的情况
response.text 和 response.content的区别
- response.text
- 类型:str
- 解码类型:requests模块自动根据http头部对响应的编码作出有根据的推测,推测的文本编码
- response.content
- 类型:bytes(字节)
- 编码类型:没有指定(可用decode来指定)
5.response响应对象的其他常用属性或方法
直接上例子:
# 调用requests模块
import requests
# 输入网址
url = 'http://www.baidu.com'
# # 结果存入response
response = requests.get(url)
# 响应的url
print(response.url)
# 响应的状态码 200代表一切正常
print(response.status_code)
# 响应的请求头
print(response.request.headers)
# 响应的响应头
print(response.headers)
# 响应中携带的cookies
print(response.cookies)结果:

6.request发送带header的请求
1.比较浏览器上的百度首页的网页源码和代码中的百度首页的源码,有什么不同?
查看网页源码的方法:
右键->查看网页源代码
2.比较对应url的响应内容和代码中的百度首页的源码,有什么不同?
查看对应url的响应内容方法:
右键-检查->点击Net work->刷新页面->查看Name一栏下和浏览器地址栏相同的url的response
3.代码中百度首页的源码非常少,为什么?
需要我们带上请求头信息
如下为‘三剑客’

请求头中有很多字段,其中User-Agent字段必不可少。
6.1 携带请求头发送请求
requests.get(url, headers = headers)- headers参数接收字典形式的请求头
- 请求头字段名作为key,字段对应的值作为value
例:
从浏览器中复制User-Agent,构造headers字典
# 调用requests模块
import requests
# 输入网址
url = 'http://www.baidu.com'
headers = {
'User-Agent': '改为你的user-agent'
}
# # 结果存入response
response = requests.get(url, headers=headers)
print(response.content.decode())得到的结果太长,我就不放截图了。
七、发送带参数的请求
在百度上搜索 python,其网址为:python_百度搜索
问号后面都是参数,但有些参数删掉之后并不影响搜索结果,可以试着删除一些看看结果。(看结果不要管上面的广告是否变化)
删完之后的网址:
python_百度搜索
1.可以直接url中带参数:
import requests
# 输入网址
url = 'https://www.baidu.com/s?wd=python'
headers = {
'User-Agent': '改为你的user-agent'
}
# # 结果存入response
response = requests.get(url, headers=headers)
print(response.url)结果:

2.使用params来发送带参数的请求:
# 调用requests模块
import requests
# 输入网址,s后的问号可有可无
url = 'https://www.baidu.com/s'
headers = {
'User-Agent': '改为你的user-agent'
}
wd = {'wd': 'python'}
# 结果存入response
response = requests.get(url, headers=headers, params=wd)
# 输出网址
print(response.url)结果:

和我们想要的网址一致,点击进入可发现正是我们想要的搜索内容。
八、在headers中设置cookies参数
cookies作用:保持登录
在无痕模式或隐身窗口中(不携带任何cookies)输入github的登录网址,会发现没有登陆成功:

登录成功的标题没有·GitHub

1.没有设置cookies参数
import requests
# 输入网址
url = 'https://github.com/aoospdk'
headers = {
'User-Agent': '改为你的user-agent'
}
# 结果存入response
response = requests.get(url, headers=headers)
with open('without_cookies.html', 'wb')as f:
f.write(response.content)找到title,标题有·Github证明登录失败

2.设置cookies参数(登录成功的网页中去抓包,找到cookies并复制下来)
import requests
# 输入网址
url = 'https://github.com/aoospdk'
headers = {
'User-Agent': '改为你的user-agent',
'cookie': '_octo=GH1.1.2093039896.1632825211; _device_id=4b08554b091dc8104150649d5556cb4f; tz=Asia%2FShanghai; has_recent_activity=1; user_session=7xaXCI0LLHOB4ALbkL5BqHtMKcI-7RUYq40R-GrVS-8BtxB8; __Host-user_session_same_site=7xaXCI0LLHOB4ALbkL5BqHtMKcI-7RUYq40R-GrVS-8BtxB8; tz=Asia%2FShanghai; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; logged_in=yes; dotcom_user=aoospdk; _gh_sess=pGu%2FC43piiBg6Q6wX7IY9zw16Ch5RdGnyDc55uXRGVvm%2Fej%2BXRc%2FVa7jOM6Ao7Wn%2F%2FMwqmJWngf%2Fde%2BtsRkRxvX%2FLMnPmrDaTnaeSNE2vQ0fsqulkxVj4a9vP%2BHt6gaA1LuXt6CALjKg1eG51cnVF869mzmfZiNQWqlLT4Mno1P%2FHxQL57eZ0CizrdLAH9pfWNKAmJQTrySweEVzDfK2UW54Rdu7kcBiM9ZyMF4QBXWfalU78jKMTJ1hwyE1VWdRtlg%2F8EEwWgtVc7Ss66I7NW2R%2FKPz%2FeatSISkfX9WszQmQPldQDpZvG1b5GDXqMJIMvVW66OOqQL%2B3PjmXiH45SiwjTAhhS5x%2BTocvqOsPxvsduQiaV3MjqRpsOZ1RkvyFe3CzGVU%2BPM7RVMTgF7FUKPhEuuzRjs0%2B1LL02kZmXaiXIbLCKRuWCNqgSVKn0LBYQJ62hkIT7ImXPo6yE0%2FgYdlIYVupcTQcsNDTiUk4biyGf9Mpb9cY%2FNC0YYpkVpogflf%2F051Rbx1EctXBt3Ju4mcT4%2B4xvZmPLxQN0mwlwCdDKuoEBz2%2BV24OKFvHDOGkTszoFTaieyKloGsE8Mpn0uBs2xtQpa22RwyV6VpHmYCpvSrcAqkvsFhUAxgf%2FVwOR0JAZ2v5ybZZV4vzNvcxxbZicX6DemOFDqHerSyXEJvxQKaSM5K20uNq3KMORiyjnnK3Owtl%2FtHBKKuGpdsV4HMxhyFSEeyLLL5OW2zLO3ydmVsaubU3py4utR%2BqT%2Fi8ogjMf6qcwqlNp1cazR3XIsqxQVz3nAkE0QeEqGfgLEbgM2x4LM7bNB6nBUelGrPzfyl8Wxi3vGXK%2FSzTFHIfyUwldlCmWUC7dz2hIilvK52HDts7wCRuK21aRXst76NN32syLvikdUiK1zRvD8R3yTf3GA%3D--GnXtAIIcxpJ1oeY1--G%2BSl6Zdk5OrtimK5PwGGwQ%3D%3D'
}
# # 结果存入response
response = requests.get(url, headers=headers)
with open('with_cookies.html', 'wb')as f:
f.write(response.content)找到title,标题没有·Github证明登录成功

九、cookies参数的使用
注意:一般cookies是有过期时间的,一旦过期需重新获取。
1.直接分割构建cookies字典:
import requests
# 输入网址
url = 'https://github.com/aoospdk'
headers = {
'User-Agent': '改为你的user-agent'
}
tmp = '_octo=GH1.1.2093039896.1632825211; _device_id=4b08554b091dc8104150649d5556cb4f; tz=Asia%2FShanghai; has_recent_activity=1; user_session=7xaXCI0LLHOB4ALbkL5BqHtMKcI-7RUYq40R-GrVS-8BtxB8; __Host-user_session_same_site=7xaXCI0LLHOB4ALbkL5BqHtMKcI-7RUYq40R-GrVS-8BtxB8; tz=Asia%2FShanghai; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; logged_in=yes; dotcom_user=aoospdk; _gh_sess=pGu%2FC43piiBg6Q6wX7IY9zw16Ch5RdGnyDc55uXRGVvm%2Fej%2BXRc%2FVa7jOM6Ao7Wn%2F%2FMwqmJWngf%2Fde%2BtsRkRxvX%2FLMnPmrDaTnaeSNE2vQ0fsqulkxVj4a9vP%2BHt6gaA1LuXt6CALjKg1eG51cnVF869mzmfZiNQWqlLT4Mno1P%2FHxQL57eZ0CizrdLAH9pfWNKAmJQTrySweEVzDfK2UW54Rdu7kcBiM9ZyMF4QBXWfalU78jKMTJ1hwyE1VWdRtlg%2F8EEwWgtVc7Ss66I7NW2R%2FKPz%2FeatSISkfX9WszQmQPldQDpZvG1b5GDXqMJIMvVW66OOqQL%2B3PjmXiH45SiwjTAhhS5x%2BTocvqOsPxvsduQiaV3MjqRpsOZ1RkvyFe3CzGVU%2BPM7RVMTgF7FUKPhEuuzRjs0%2B1LL02kZmXaiXIbLCKRuWCNqgSVKn0LBYQJ62hkIT7ImXPo6yE0%2FgYdlIYVupcTQcsNDTiUk4biyGf9Mpb9cY%2FNC0YYpkVpogflf%2F051Rbx1EctXBt3Ju4mcT4%2B4xvZmPLxQN0mwlwCdDKuoEBz2%2BV24OKFvHDOGkTszoFTaieyKloGsE8Mpn0uBs2xtQpa22RwyV6VpHmYCpvSrcAqkvsFhUAxgf%2FVwOR0JAZ2v5ybZZV4vzNvcxxbZicX6DemOFDqHerSyXEJvxQKaSM5K20uNq3KMORiyjnnK3Owtl%2FtHBKKuGpdsV4HMxhyFSEeyLLL5OW2zLO3ydmVsaubU3py4utR%2BqT%2Fi8ogjMf6qcwqlNp1cazR3XIsqxQVz3nAkE0QeEqGfgLEbgM2x4LM7bNB6nBUelGrPzfyl8Wxi3vGXK%2FSzTFHIfyUwldlCmWUC7dz2hIilvK52HDts7wCRuK21aRXst76NN32syLvikdUiK1zRvD8R3yTf3GA%3D--GnXtAIIcxpJ1oeY1--G%2BSl6Zdk5OrtimK5PwGGwQ%3D%3D'
cookies_list = tmp.split('; ')
cookies = {}
for cookie in cookies_list:
cookies[cookie.split('=')[0]] = cookie.split('=')[-1]
# # 结果存入response
response = requests.get(url, headers=headers, cookies=cookies)
with open('with_cookies2.html', 'wb')as f:
f.write(response.content)结果:

2.应用字典推导式(简洁)
import requests
# 输入网址
url = 'https://github.com/aoospdk'
headers = {
'User-Agent': '改为你的user-agent'
}
tmp = '_octo=GH1.1.2093039896.1632825211; _device_id=4b08554b091dc8104150649d5556cb4f; tz=Asia%2FShanghai; has_recent_activity=1; user_session=7xaXCI0LLHOB4ALbkL5BqHtMKcI-7RUYq40R-GrVS-8BtxB8; __Host-user_session_same_site=7xaXCI0LLHOB4ALbkL5BqHtMKcI-7RUYq40R-GrVS-8BtxB8; tz=Asia%2FShanghai; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; logged_in=yes; dotcom_user=aoospdk; _gh_sess=pGu%2FC43piiBg6Q6wX7IY9zw16Ch5RdGnyDc55uXRGVvm%2Fej%2BXRc%2FVa7jOM6Ao7Wn%2F%2FMwqmJWngf%2Fde%2BtsRkRxvX%2FLMnPmrDaTnaeSNE2vQ0fsqulkxVj4a9vP%2BHt6gaA1LuXt6CALjKg1eG51cnVF869mzmfZiNQWqlLT4Mno1P%2FHxQL57eZ0CizrdLAH9pfWNKAmJQTrySweEVzDfK2UW54Rdu7kcBiM9ZyMF4QBXWfalU78jKMTJ1hwyE1VWdRtlg%2F8EEwWgtVc7Ss66I7NW2R%2FKPz%2FeatSISkfX9WszQmQPldQDpZvG1b5GDXqMJIMvVW66OOqQL%2B3PjmXiH45SiwjTAhhS5x%2BTocvqOsPxvsduQiaV3MjqRpsOZ1RkvyFe3CzGVU%2BPM7RVMTgF7FUKPhEuuzRjs0%2B1LL02kZmXaiXIbLCKRuWCNqgSVKn0LBYQJ62hkIT7ImXPo6yE0%2FgYdlIYVupcTQcsNDTiUk4biyGf9Mpb9cY%2FNC0YYpkVpogflf%2F051Rbx1EctXBt3Ju4mcT4%2B4xvZmPLxQN0mwlwCdDKuoEBz2%2BV24OKFvHDOGkTszoFTaieyKloGsE8Mpn0uBs2xtQpa22RwyV6VpHmYCpvSrcAqkvsFhUAxgf%2FVwOR0JAZ2v5ybZZV4vzNvcxxbZicX6DemOFDqHerSyXEJvxQKaSM5K20uNq3KMORiyjnnK3Owtl%2FtHBKKuGpdsV4HMxhyFSEeyLLL5OW2zLO3ydmVsaubU3py4utR%2BqT%2Fi8ogjMf6qcwqlNp1cazR3XIsqxQVz3nAkE0QeEqGfgLEbgM2x4LM7bNB6nBUelGrPzfyl8Wxi3vGXK%2FSzTFHIfyUwldlCmWUC7dz2hIilvK52HDts7wCRuK21aRXst76NN32syLvikdUiK1zRvD8R3yTf3GA%3D--GnXtAIIcxpJ1oeY1--G%2BSl6Zdk5OrtimK5PwGGwQ%3D%3D'
cookies_list = tmp.split('; ')
cookies = {cookie.split('=')[0]: cookie.split('=')[-1]for cookie in cookies_list}
# # 结果存入response
response = requests.get(url, headers=headers, cookies=cookies)
with open('with_cookies3.html', 'wb')as f:
f.write(response.content)结果:
十、cookiejar对象的处理
使用requests获取的response对象,具有cookies属性,该属性值是一个cookiejar类型,包含了对方服务器设置在本地的cookie,我们如何将其转换为cookies字典?
-
转换方法
cookies_dict = requests.utils.dict_from_cookiejar(response.cookies) -
其中response.cookies返回的就是cookieJar类型的对象
-
requests.utils.dict_from_cookiejar函数返回cookies字典
例:
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
# cookiejar对象
print(response.cookies)
# 转换为cookies字典
dict_cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(dict_cookies)
# 转换为cookiejar对象
jar_cookies = requests.utils.cookiejar_from_dict(dict_cookies)
print(jar_cookies)
结果:

十一、超时参数timeout的使用
在爬虫中,一个请求很久没有结果,就会让整个项目的效率变得非常低,这个时候我们就需要对请求进行强制要求,让他必须在特定的时间内返回结果否则就报错。
1.超时参数timeout的使用方法
response = requests.get(url, timeout=3)
2.timeout=3表示:发送请求后,3秒内返回响应,否则就抛出异常
例:
import requests
url = 'http://twitter.com'
response = requests.get(url, timeout=3)
结果:
3s后抛出异常。
十二、代理proxies的使用
12.1 代理过程
1.代理IP是一个IP,指向的是一个代理服务器
2.代理服务器能够帮我们向目标服务器转发请求
12.2 正向代理和反向代理的区别
-
从发送请求的一方的角度,来区分正向或反向代理
-
为浏览器或客户端(发送请求的一方)转发请求的,叫做正向代理
-
浏览器知道最终处理请求的服务器的真实ip地址,例如VPN
-
-
不为浏览器或客户端(发送请求的一方)转发请求、而是为最终处理请求的服务器转发请求的,叫做反向代理
-
浏览器不知道服务器的真实地址,例如nginx
-
12.3 代理IP(代理服务器)的分类
-
根据代理ip的匿名程度,代理IP可以分为下面三类:
-
透明代理(Transparent Proxy):透明代理虽然可以直接“隐藏”你的IP地址,但是还是可以查到你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP HTTP_VIA = Proxy IP HTTP_X_FORWARDED_FOR = Your IP
-
匿名代理(Anonymous Proxy):使用匿名代理,别人只能知道你用了代理,无法知道你是谁。目标服务器接收到的请求头如下:
REMOTE_ADDR = proxy IP HTTP_VIA = proxy IP HTTP_X_FORWARDED_FOR = proxy IP
-
高匿代理(Elite proxy或High Anonymity Proxy):高匿代理让别人根本无法发现你是在用代理,所以是最好的选择。毫无疑问使用高匿代理效果最好。目标服务器接收到的请求头如下:
REMOTE_ADDR = Proxy IP HTTP_VIA = not determined HTTP_X_FORWARDED_FOR = not determined
-
-
根据网站所使用的协议不同,需要使用相应协议的代理服务。从代理服务请求使用的协议可以分为:
-
http代理:目标url为http协议
-
https代理:目标url为https协议
-
socks隧道代理(例如socks5代理)等:
-
socks 代理只是简单地传递数据包,不关心是何种应用协议(FTP、HTTP和HTTPS等)。
-
socks 代理比http、https代理耗时少。
-
socks 代理可以转发http和https的请求
-
-
12.4 proxies代理参数的使用
为了让服务器以为不是同一个客户端在请求;为了防止频繁向一个域名发送请求被封IP,所以我们需要使用代理IP。
-
用法:
response = requests.get(url, proxies=proxies)
-
proxies的形式:字典
-
例如:
proxies = { "http": "http://12.34.56.79:9527", "https": "https://12.34.56.79:9527", } -
注意:如果proxies字典中包含有多个键值对,发送请求时将按照url地址的协议来选择使用相应的代理ip
一下是一些免费代理ip部分截图:

例:
import requests
url = 'http://www.baidu.com'
proxies = {
'http': 'http://180.122.173.198:41421'
}
response = requests.get(url, proxies=proxies)
print(response.text)十三、verify与CA证书
使用浏览器上网的时候,有时能够遇到“您的连接不是私密连接”的提示:
原因:该网站的CA证书没有经过【受信任的根证书颁发机构】的认证
用代码向不安全的链接发送请求的效果:
代码:
import requests
url = "https://sam.huat.edu.cn:8443/selfservice/"
response = requests.get(url)
结果:(SSLError)
![]()
13.1 解决方案
使用verify=False参数,此时requests模块发送请求将不做CA证书的验证:verify参数能够忽略CA证书的认证。
代码:
import requests
url = "https://sam.huat.edu.cn:8443/selfservice/"
response = requests.get(url, verify=False)
print(response.content)结果:(会出现警告,但并不会报错)
