姓名:王小涵
学号:16020199013
转载自:https://www.leiphone.com/news/201811/Ldq0J77QcRJrl0g9.html
【嵌牛导读】:用 Fast.AI 库实现癌症分类
【嵌牛鼻子】: Fast.AI 库 癌症
【嵌牛提问】:用 Fast.AI 库怎么实现癌症分类?
【嵌牛正文】:
第1章 问题:无本之木
大约15%的癌症会进行转移,即癌细胞脱离最初形成的位置(原发部位或组织),通过血液或淋巴系统转移,并形成新的转移性肿瘤。癌症的有效治疗通常依赖于癌症初始位置点的确定,而测定转移性肿瘤的初始位置点是目前癌症治疗中仍未解决的问题之一。
通过肿瘤基因突变中的点突变对癌症进行分类极具难度,主要是由于数据稀少。许多肿瘤在编码区域只有少量突变,其中许多突变又相当独特。
以往的研究中,基于肿瘤点突变的癌症分类器的准确率有限,在12个肿瘤类别中的分类准确率只有64.9%,如DeepGene算法。通过对基因表达数据的利用,肿瘤分类器的准确率能够极大地提高(33个肿瘤类别可达到90%以上),但这些额外的数据通常在临床环境中并不容易获取。因此,能够仅从DNA点突变中预测肿瘤类型而不依赖于其他基因表达数据的精确计算方法具有重大意义。
第2章 解决方法 = 嵌入式 + 迁移学习 + 微调
那么解决方法是什么呢?
正如量子物理理论学家所说:“每个高深问题都有其特有的解决方式。我们应转变自己思维方式,去发现问题背后的解决方法。“
我们要面对的困难有:
数据的表达——我们无法利用现有的数据表达预训练深度神经网络,即使深度神经网络在数据集上表现出优越的性能。然而, 在癌症基因组应用领域,训练数据恰恰是稀缺的,同时数据扩充等方法并不适用于该领域。在癌症基因组图谱(TCGA)中,有9642个样本分布在29个癌症类别中。
即使在基因水平上统计,肿瘤点突变数据也是稀缺的。有一个癌症生物学的有趣观察:在同一路径基因中的癌症突变通常是相互排斥的。下图是一个“贺曼”过程(路径)在癌症中受到影响的例子。图片来自于 Douglas Hanahan的论文,路径以蓝色标出。
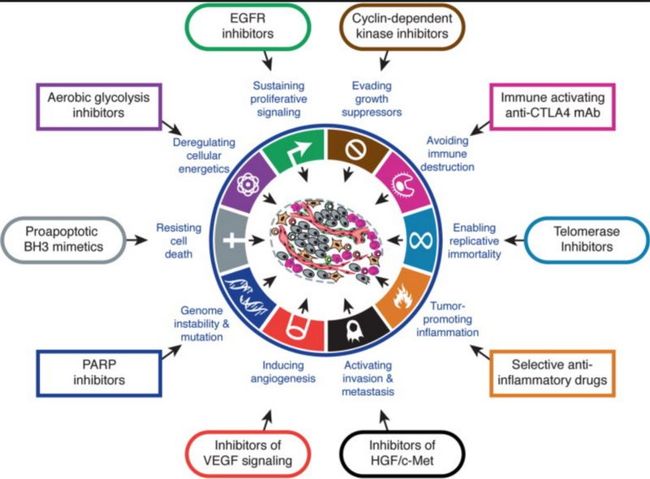
那么,为什么不用路径来编码点突变数据呢? 如何利用路径中的基因成员信息来训练我们自己的Gene2Vec编码。
这有一个基本的概括,是关于不读取基因详细信息而能够具有高效性能- 只依靠DNA点突变就能在29个肿瘤类中达到78.2%的分类准确率。
第3章 详细实现流程
3.1 数据收集及预处理
我们从基因组数据开源网站下载TCGA变异注释格式文件夹,然后再移除沉默突变,并只保留人类基因组汇编GRCh38(hg38)注释的基因。专门针对29种肿瘤类型,我们将数据集的80%用于训练,剩下的20%用于测试。
我们在每个肿瘤类型训练集中检测非沉默突变,再利用MutSigCV在非沉默突变中识别出突变显著的基因。如此,我们可以提取到极其稀疏数据集的重要特征。在考虑了已给定基因的碱基组成 、长度和背景突变率在内的协变量的情况下,MuTSigCV检测的基因突变发生率会高于随机预期。 然后,我们留下了1348个突变显著的基因。
我们训练了Gene2Vec,用来学习与生物学相关的数据嵌入,然后使用了所有已知路径的数据库MSigDb version 6.2,其中包含17,810条路径。我们本着Word2Vec的精神,将类似基因的路径映射到附近的点。我们在这里假设了出现在相同路径背景下的基因具有相同的生物学功能,同时在定义Gene2Vec时,使用了标准的Skip-Grammodel。
3.2 将突变数据转化为图像
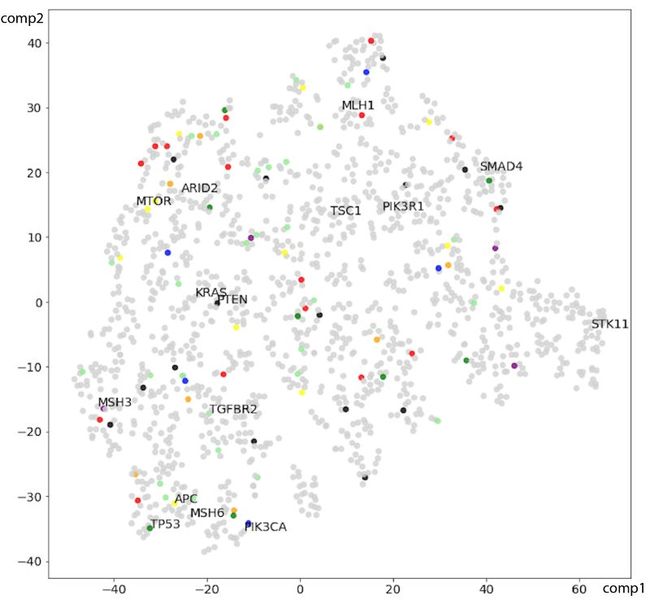
之后,我们提取已经训练了嵌入在训练集中的1348个突变显著的基因的Gene2Vec,这步会产生一个方阵,再使用光谱聚类算法( 谱聚类是一种将N个数据点在i维空间中分成若干簇的技术)在嵌入矩阵中创建视觉结构。 然后使用光谱聚集基因嵌入对训练和测试样本进行编码。左图是一个胃癌标本的嵌入例子,下图是1348个突变显著基因的基因嵌入的t分布随机邻居嵌入(t-SNE)可视化图。可以观察出参与同一癌症通路的基因在表达上彼此更相近,例如KRAS和PTEN(结直肠癌); 同样TP53、APC和MSH6 (DNA错配修复)比其他基因更相近。
3.3 迁移学习和微调——Fast.AI:
我们在ImageNet上利用ResNet34模型的预训练权重作为初始化,用我们的肿瘤图像嵌入来完成肿瘤分类的目标任务。将图像重新缩放到512x512,并进行归一化以匹配ImageNet图像的均值和标准差,批量大小设置为32,来适用于我的GTX 1070 Ti GPU。
在微调的第一阶段,除了最后一层,所有自定义的ResNet34全连接层都被冻结。利用学习率查找器,选择0.01的学习率,详细可见Leslie Smith的论文及其在Fast.AI repo中的具体实现。倾斜的三角形学习率训练周期为10个周期,第一阶段完成的准确率为73.2%。
在第二阶段,我们采用差异性微调(discriminative fine-tuning),利用学习率查找器确定学习速率为0.000001到0.001。由于不同的层应该在不同的程度上进行微调,差异性微调将深层神经网络的层划分为不同的组,并对每个组应用不同的学习率, 最早的剩余块最小,全连通层的学习率最大。在训练的第二阶段,我们使用了倾斜的三角形学习率的12个训练周期。第一阶段完成的准确率为78.3%。
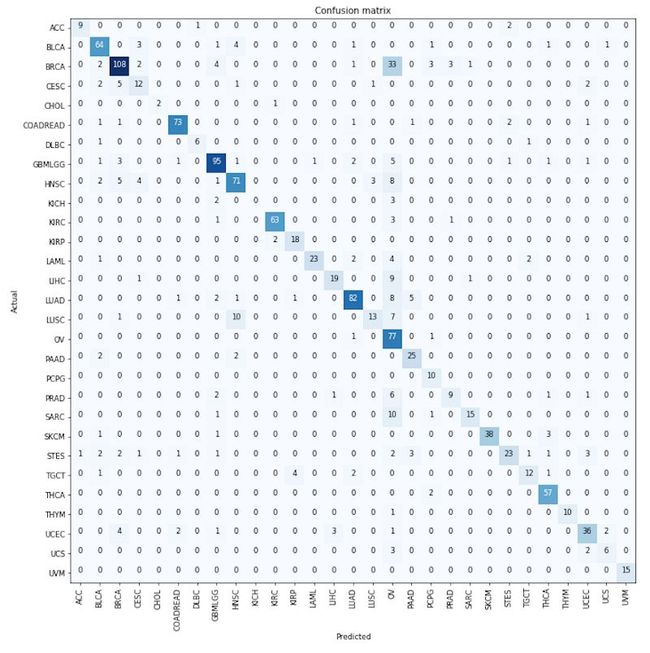
下图是我们分类器的混淆矩阵:
第4章 一些我的观察
我观察到一些错误的分类主要在同一个器官系统中,例如卵巢浆液性囊腺癌(OV)和乳腺癌(BRCA)。
我还观察到卵巢浆液性囊腺癌(OV)的错误率最高。这其实并不奇怪,因为与其他队列中大量的基因相比,在这个队列中,只有6个基因发生了显著的突变。
但我最重要的观察是Fast.AI库容许最先进的迁移学习和微调功能。要是给定了数据的正确表示形式,构建最先进的分类器就会变得非常简单: 如此,我将先前的最高水准下犯的错误减少了30%以上,同时对更多的类进行了区分。感谢Jeremy和Fast.AI。
我十分期待能从Jeremy和Rachel那学到更多的知识(:-),针对性微调(discriminating fine-tuning)我学到的知识,用来破解其他重要和有趣的问题!
如果你对上面的描述有任何疑问,请在twitter @alenushka上找到我