本文基于 incubator-livy 0.4.0-incubating
关于Apache Livy(下文简称 livy)是什么以及有什么用,请移步:Livy:基于Apache Spark的REST服务
一、实现思路
在知道 livy 的作用及特点后,我们尝试着分析一个用户的任务是怎么通过 livy 运行起来的。
第一步:要将任务从用户的手里发送给 livy server,任务可以是代码片段(Scala、Python,R)的形式或可执行程序的形式(Jar)。这需要对最原始的任务按照 livy 的接口进行简单的封装,然后通过 http 的方式发送给 livy server
第二步:livy server 端要能够接收用户的请求,并且要能根据这是一个对 session 的,还是对 batch 或 job 的一个什么样的请求(创建、查状态、拿结果还是停止)进行相应的路由,去调用某个类的某个方法
第三步:livy 是一个有权限控制的系统(当然可以不开启),每个用户的每个请求是否有权限执行,都需要进行鉴权
第四步:对于用户发送的任务请求,livy 要有能力将其转换为一个 Spark App 并启动起来
第五步:除了要能执行用户指定的任务,运行中的 Spark App 还要提供获取运行状态、获取运行结果、共享 SparkContext 以及被正常停止等能力
第六步:一个 livy server 管理着众多 sessions、batches,需要维护大量相关信息并且在 livy server 重启后需要能够恢复对 sessions、batches 的管理,这就需要有能存取这些状态数据的模块
二、模块概述
从上文的 livy 大致的实现思路中,我们可以依次归纳出以下几个模块(顺序与上文步骤一一对应):
- Client
- router
- 权限管理
- 生成 Spark App
- 交互式 Driver
- 状态数据存储
其中每个模块(不同模块用不同颜色区分)及涉及的主要类,如下:
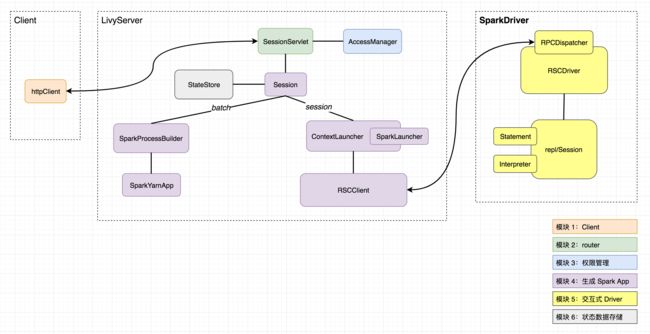
2.1、Client
Client 并不算 livy 的模块,也很简单,在此略过
2.2、router
我们知道,livy server 提供的 api 是 rest api,Client 发送的请求也是针对各个资源(uri)的增删改查。router 的核心职责是管理好要把对什么资源的什么操作指派给哪个类的哪个函数来处理,该模块核心类是 SessionServlet,继承于 ScalatraServlet,有两个子类:InteractiveSessionServlet 及 BatchSessionServlet,分别用来路由对 session 及 batch 相关的请求。
2.3、权限管理
权限由 AccessManager 类管理,维护了几种不同级别的 user:
- superUser
- modifyUser
- viewUser
- allowedUser
以及不用级别的 acl(访问控制列表):
- viewAcls:
superUsers ++ modifyUsers ++ viewUsers,对应查看权限 - modifyAcls:
superUsers ++ modifyUsers,对应修改权限(包括 kill 权限) - superAcls:
superUsers,有所有权限 - allowedAcls:
superUsers ++ modifyUsers ++ viewUsers ++ allowedUsers,表示 acl 的全集
在目前的实现中,livy 的权限管理尚不支持插件化且只有 AccessManager 一种实现,若要定义自己的权限管理,需要直接修改源码
2.4、生成 Spark App
对于 session 和 batch 的任务,生成 Spark App 的逻辑及最终生成的 Spark App 都是不同的。先来说说相对简单的生成 batch 的 Spark App 涉及的主要类:
-
SparkProcessBuilder:用于从 livyConf 中提取出运行一个 Spark App 所需的一切,包括 mainClass、executableFile、deployMode、conf、master、queue、env 及 driver 和 executors 的资源配置等等;并最终生成一条启动 Spark App 的spark-submit命令 -
SparkYarnApp:用来运行SparkProcessBuilder生成的启动命令,并监控管理启动运行起来的 Spark App,包括获取状态、日志、诊断信息、kill 等(目前 livy 只支持 local 和 yarn 两种模式,local 暂不进行介绍)
接下来是生成 session 的 Spark App 涉及的主要类:
-
ContextLauncher:用于启动一个新的 Spark App(通过 SparkLauncher)以及获取如何连接到其 driver 的信息(地址、clientId 及秘钥) -
RSCClient:与 Spark Driver 建立连接,向其发送创建、查看状态结果日志、修改statement、job 等请求并获取响应
2.5、交互式 Driver
需要注意的是,该模块仅对于 session 任务有,batch 并没有。
该模块中,最核心的类是 RSCDriver,其继承与 RpcDispatcher,RpcDispatcher 接收来自 RSCClient 发送的 rpc 请求,根据请求的类型调用 RSCDriver 相应的方法去处理请求中包含的具体信息,对于最核心的执行代码片段(statement)请求,调用 repl/Session 去处理,repl/Session 最终会根据不同的 session kind 调用不同的 Interpreter 进行真正的代码执行,目前共有 Spark、Scala、Python、R 对应的 Interpreter
2.6、状态数据存储
核心类是 StateStore,状态数据的存储都是以 key-value 形式,目前有基于文件系统和 Zookeeper 的实现。另外,SessionStore 继承了该类提供高阶 Api 来进行 sessions 的存储和恢复
总结
上述的整体思路和模块概述让我们大致了解了 livy 是怎么玩的,接下来会针对各个模块进行更深入的展开,to be continued~