Redis:Key-value的NoSQL数据库
一.Reids简介
目前市场主流数据库存储都是使用关系型数据库.每次操作关系型数据库时都是I/O操作,I/O操作是主要影响程序执行性能原因之一,连接数据库关闭数据库都是消耗性能的过程.尽量减少对数据库的操作,能够明显的提升程序运行效率.
针对上面的问题,市场上就出现了各种NoSQL(Not Only SQL,不仅仅可以使用关系型数据库)数据库,它们的宣传口号:不是什么样的场景都必须使用关系型数据库,一些特定的场景使用NoSQL数据库更好
1.常见NoSQL数据库:
memcached:键值对,内存型数据库,所有数据都在内存中
Redis和Memcached类似,还具备持久化能力
HBase:以列作为存储
MongoDB:以Document做存储
2.Redis简介
Redis是以Key-Value形式进行存储的NoSQL数据库
Redis是使用C语言进行编写的
平时操作的数据都在内从中,效率特高,读的效率110000/s,写81000/s,所以多把Redis当做缓存工具使用
Redis以slot(槽)作为存储单元.每个曹中可以存储N多个键值对.Redis中固定具有16384.理论上可以实现一个槽是一个Redis.每个向Redis存储数据的key都会进行crc16算法得出一个值后对16384取余就是这个key存放的slot位置
同时通过Redis Sentinel(哨兵)提供高可用,通过Redis Cluster(集群)提供自动分区
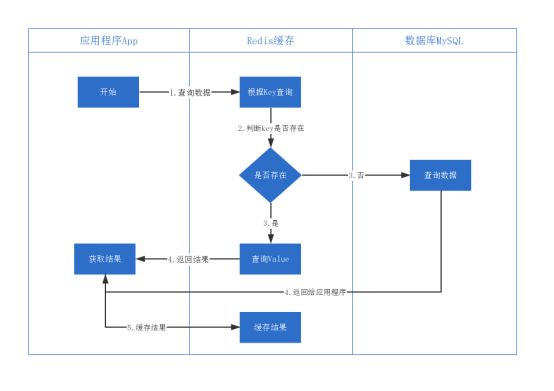
二.使用Redis作为缓存工具时流程(写代码时思路)
1.应用程序向Redis查询数据
2.判断Key是否存在
3.是否存在
1)存在
a.把结果查询出来
b.返回数据给应用程序
2).不存在
a.向MySQL查询数据
b.把数据返回给应用程序
c.把结果缓存到Redis中
三.Redis单机版安装
Redis单机版安装
四.Redis数据类型(面试问题)
Redis中数据是key-value形式.不同类型Value是由不同的命令进行操作.key为字符串类型,value常用类型:
String字符串
Hash哈希表
List列表
Set集合
Sorted Set有序集合(zSet)
Redis命令相关手册很多,下面为其中比较好用的两个
https://www.redis.net.cn/order/
http://doc.redisfans.com/
Redis中命令有很多,抽取出部分进行讲解
1.Key操作
1.1exists
判断key是否存在
语法:exists key名称
返回值:存在返回数字,不存在返回0
1.2expire
设置key的过期时间,单位秒
语法:expire key秒数
返回值:成功返回1,失败返回0
1.3ttl
查看key的剩余过期时间
语法:ttl key
返回值:返回剩余时间,如果不过期返回-1
1.4persist
删除key的有效时长
语法:persist key
返回值:返回删除有效时长的key的个数
1.5del
根据key删除键值对
语法:del key
返回值:被删除key的数量
1.6keys
根据表达式,显示redis中的key
语法:keys表达式 [如:keys*]
返回值:redis中的key列表
2.字符串值(String)
2.1set
设置指定key的值.如果key不存在是新增效果,如果key存在是修改效果.键值对是永久存在的
语法:set key value
返回值:成功OK
2.2get
获取指定key的值
语法:get key
返回值:key的值.不存在返回null
2.3setnx
当且仅当key不存在时才新增.恒新增,无修改功能.
语法:setnx key value
返回值:不存在时返回1,存在返回0
2.4setex
设置key的存活时间,无论是否存在指定key都能新增,如果存在key覆盖旧值.同时必须指定过期时间
语法:setex key seconds value
返回值:OK
3.哈希表(Hash)
Hash类型的值中包含多组field value

3.1hset
给key中field设置值
语法:hset key field value
返回值:成功1,失败0
3.2hget
获取key中某个field的值
语法:hget key field
返回值:返回field的内容
3.3hmset
给key中多个field设置值
语法:hmset key field value field value
返回值:成功OK
3.4hmget
一次获取key中多个field的值
语法:hmget key field field
返回值:value列表
3.5hkeys
获取key中所有的field名称
语法:hkeys key
返回值:field名称列表
3.6hvals
获取key中所有field的值
语法:hvals key
返回值:value列表
3.7hgetall
获取所有field和value
语法:hgetall key
返回值:field和value交替显示列表
3.8hdel
删除key中任意个field
语法:hdel key field field
返回值:成功删除field的数量,当key对应的所有field全部删除,自动删除key
4.列表(List)
4.1Rpush
向列表末尾中插入一个或多个值
语法:rpush key value value
返回值:列表长度
4.2lrange
返回列表中指定区域内的值.可以使用-1代表列表末尾
语法:lrange list 0 -1
返回值:查询到的值
4.3lpush
将一个或多个值插入到列表前面
语法:lpush key value value
返回值:列表长度
4.4llen
获取列表长度
语法:llen key
返回值:列表长度
4.5lren
删除雷彪中元素.count为正数表示从左往右的数量.负数从右往左删除的数量.
语法:lren key count value
返回值:删除数量
5.集合(Set)
set和java中集合一样
5.1sadd
向集合中添加内容.不允许重复
语法:sadd key value value value
返回值:成功新增元素个数
5.2scard
返回集合元素数量
语法:scard key
返回值:集合长度
5.3smembers
查看集合中元素内容
语法:smembers key
返回值:集合中元素
5.4srem
删除集合中的元素
语法:srem key member [member...]
返回值;删除的有效数据个数
6.有序集合(Sorted Set)
有序集合中每个value都有一个分数(score),根据分数进行排序
6.1zadd
向有序集合中添加数据
语法:zadd key score value score value
返回值:长度
6.2zrange
返回区间内容,withscores表示带有分数
语法:zrange key区间[withscores]
返回值:值列表
6.3zrem
删除元素
语法:zrem key memeber[member...]
返回:删除的元素个数
6.4zcard查看zset集合长度
语法:zcard key
返回:集合长度
五.Redis持久化策略(面试问题)
Redis不仅仅是一个内存型数据库,还具备持久化能力
Redis每次启动时都会从硬盘存储文件中把数据读取到内存中.运行过程中操作的数量都是内存的数据
一共包含两种持久化策略:RDB 和AOF
1.RDB(RedisDataBase)
rdb模式是默认模式,可以在指定的时间间隔内生成数据快照(snapshot),默认保存到dump.rdb文件中.当redis重启后会自动加载dump.rdb文件中内容到内存中.
用户可以使用SAVE(同步)或BGSAVE(异步)手动保存数据
可以设置服务器配置的save选项,让服务器每个一段时间自动执行一次BGSAVE命令,可以通过save选项设置多个保存条件,单只要其中任意一个条件被满足,服务器就会执行BGSAVE命令
例如:
save900 1
save300 10
save60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行.计时单位是必须要执行的时间,save900 1,每900秒检测一次.在并发量越高的项目中Redis的时间参数设置的值要越小
服务器在900秒之内,对数据库进行了至少1次修改
服务器在300秒之内,对数据库进行了至少10次修改
服务器在60秒之内,对数据库进行了至少10000次修改
1.1优点
rdb文件是一个紧凑文件,直接使用rdb文件就可以还原数据
数据保存会由一个子进程进行保存,不影响父进程做其他事情
恢复数据的效率要高于aof
总结:性能要高于AOF
1.2缺点
每次保存点之间导致redis不可意料的关闭,可能会丢失数据
由于每次保存数据都需要fork()子进程,在数据量比较大时可能会比较耗费性能
2.AOF(AppendOnly File)
AOF默认是关闭的appendonly no,需要在配置文件redis.conf中开启AOF.Redis支持AOF和RDB同时生效,如果同时存在,AOF优先级高于RDB(Redis重新启动时会使用AOF进行数据恢复)
AOF原理:监听执行的命令,如果发现执行了修改数据的操作,同时直接同步到数据库文件中,同时会把命令记录到日志中.即使突然出现问题,由于日志文件中已经记录命令,下一次启动时也可以按照日志进行恢复数据,由于内存数据和硬盘数据实时同步,即使出现意外情况也需要担心
2.1优点
相对RDB数据更加安全
2.2缺点
相同数据集AOF要大于RDB
相对RDB可能会慢一些
2.3开启办法
修改redis.conf中
appendonlu yes 开启aof
appendfilename设置aof数据文件,名称随意.
# 默认no
appendonly yes
# aof 文件名
appendfilename "appendonly.aof"
六.Redis主从复制
Redis支持集群功能.为了保证单一节点可用性,redis支持主从复制功能.每个节点有N个复制品(replica),其中一个复制品是主(master),另外N-1一个复制品从(Slave),也就是说Redis支持一主多从
一个主可有多个从,而一个从又可以看成主,它还可以有多个从.

1.主从优点
增加单一节点的健壮性,从而提升整个集群的稳定性(Redis中当超过1/2节点不可用时,整个集群不可用)
从节点可以对主节点数据备份,提升容灾能力
读写分离.在redis主从中,主节点一般用作写(具备读的能力),从节点只能读,利用这个特性实现读写分离,写用主,读用从.
2.一主多从搭建
在已经搭建的单机版redis基础上进行操作
并且关闭redis单机版
2.1新建目录
# mkdir /usr/local/replica
2.2复制目录
把之前安装的redis单机版中bin目录复制三份,分别叫做:master,slave1,slave2
# cp -r /usr/local/redis/bin /usr/local/replica/master
# cp -r /usr/local/redis/bin /usr/local/replica/slave1
# cp -r /usr/local/redis/bin /usr/local/replica/slave2
2.3修改从的配置文件
修改2个从的redis.conf,指定主节点ip和端口.并修改自身端口号防止和其他redis冲突
# vim /usr/local/replica/slave1/redis.conf
指定主节点ip和端口
replicaof 192.168.232.132 6379
修改自己端口
port 6380
# vim /usr/local/replica/slave2/redis.conf
指定主节点ip和端口
replicaof 192.168.232.132 6379
修改自己端口
port 6381
2.4启动三个redis实例
注意:一定要关闭单机的redis,否则端口冲突.master的端口是6379,单机版redis端口也是6379
# cd /usr/local/replica
# vim startup.sh
在文件中添加下面内容,一点要先点击键盘i键盘,启用编辑状态后在粘贴.退出编辑状态下输入gg=G进行排版
cd /usr/local/replica/master/
./redis-server redis.conf
cd /usr/local/replica/slave1
./redis-server redis.conf
授权
# chmod a+x startup.sh
# ./startup.sh
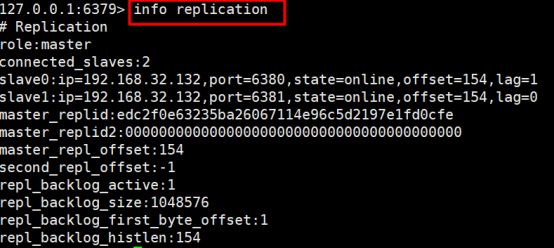
2.5查看启动状态
# ps aux | grep redis

2.6测试
# cd /usr/local/replica/master/
# ./redis-cli -p 端口号
在客户端命令模式下,添加一条数据:
进入slave查看数据是否同步
# cd /usr/local/replica/slave1
必须带有-p,否则默认进入6379端口,相当于连接的是master
# ./redis-cli -p 6380
七.哨兵(Sentinel)
在redis主从模型是只有主(Master)具备写的能力,而从(Slave)只能读.如果主宕机,整个节点不具备写能力.但是如果这时让一个从变成主,整个节点就可以继续工作.即使之前的主恢复过来也当做这个结点的从即可
Redis的哨兵就是帮助监控整个节点的,当主节点宕机等情况下,帮助重新选取主
Redis中哨兵支持单哨兵和多哨兵.单哨兵是只要这个哨兵发现master宕机了,就直接选取另一个master.而多哨兵是根据我们设定,达到一定数量哨兵认为master宕机后才会进行重新选取主.我们以丢多哨兵演示
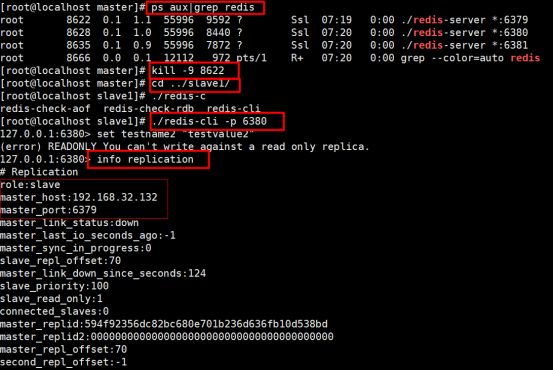
1.没有哨兵下主从效果
只要杀掉主,整个节点无法在写数据,从身份不会变化,主的信息还是以前的信息
2.搭建多哨兵
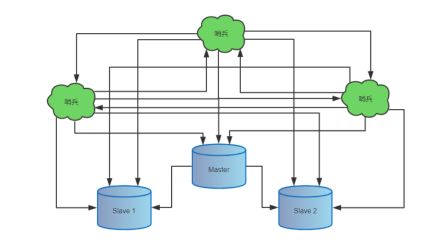
前提:安装了单机的redis
2.1新建目录
# mkdir /usr/local/sentinel
2.2复制redis
# cp -r /usr/local/redis/bin/* /usr/local/sentinel
2.3复制配置文件
从redis解压目录中复制sentinel配置文件
# cd /usr/local/tmp/redis-5.0.5/
# cp sentinel.conf /usr/local/sentinel/
2.4修改配置文件
# cd /usr/local/sentinel
# vim sentinel.conf
sentinel monitor命令
mymaster主的名称
192.168.232.132主的ip
6379主的端口号
2.多少个哨兵发现主宕机时重新选择
port 26379
daemonize yes
logfile "/usr/local/sentinel/26379.log"
sentinel monitor mymaster 192.168.232.132 6379 2
复制sentinel.conf,命名为sentinel-26380.conf
# cp sentinel.conf sentinel-26380.conf
# vim sentinel-26380.conf
port 26380
daemonize yes
logfile "/usr/local/sentinel/26380.log"
sentinel monitor mymaster 192.168.232.132 6379 2
复制sentinel.conf,命名为sentinel-26381.conf
# cp sentinel.conf sentinel-26381.conf
# vim sentinel-26381.conf
port 26381
daemonize yes
logfile "/usr/local/sentinel/26381.log"
sentinel monitor mymaster 192.168.232.132 6379 2
2.5启动主从
如果已经启动状态,忽略下面命令.如果启动部分,全部kill后重新启动
使用kill杀死全部redis
# ps aux | grep redis
# kill -9 进程号
启动redis主从
# cd /usr/local/replica
# ./startup.sh
2.6启动三个哨兵
# cd /usr/local/sentinel
# ./redis-sentinel sentinel.conf
# ./redis-sentinel sentinel-26380.conf
# ./redis-sentinel sentinel-26381.conf
2.7查看日志
# cat 26379.log
2.8测试宕机
查看redis进程号
# ps aux | grep redis
杀死主进程号
# kill -9 进程号
查看日志,短暂延迟后发现,出现新的主.观察日志中新增内容
# tail -f 26379.log
进入到6381(可能是6380)的客户端,查看主从信息
# cd /usr/local/replica
# ./redis-cli -p 6381

八.集群(Cluster)
1.集群原理
a)集群搭建完成后有集群节点平分(不能平分时,前几个节点多一个槽)16384个槽
b)客户端可以访问集群中任意节点.所以在写代码时都是需要把集群中所有节点都配置上
c)当向集群中新增或查询一个键值对时,会对Key进行Crc16算法得出一个小于16384的值,判断值在那个节点上,然后就操作哪个节点
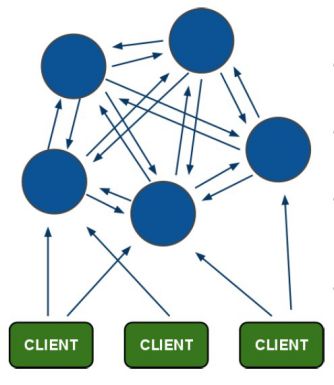
前提:已经安装好redis单机版
当集群中超过或等于1/2节点不可用时,整个集群不可用.为了搭建稳定集群,都采用奇数节点
演示时:创建3个节点,每个节点搭建一主一从
1.复制redis
在/usr/local下新建redis-cluster
# mkdir /usr/local/redis-cluster
把单机redis复制到redis-cluster中
# cd /usr/local/redis
# cp -r bin /usr/local/redis-cluster/redis1
2.修改redis.conf
# cd /usr/local/redis-cluster/redis1
# vim redis.conf
需要修改如下
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timeout 15000
# appendonly yes如果开启aof默认,需要修改为yes.如果使用rdb,此处不需要修改
daemonize yes
protected-mode no
pidfile /var/run/redis_7001.pid
3.复制redis
把redis1复制5份
# 传递/usr/local/redis-cluster
执行之前一定要先删除dump.rdb,清空Redis中数据
# rm -f redis1/dump.rdb
# cp -r redis1 redis2
# cp -r redis1 redis3
# cp -r redis1 redis4
# cp -r redis1 redis5
# cp -r redis1 redis6
新复制的5个redis的配置文件redis.conf都需要修改三处
# vim redis2/redis.conf
# vim redis3/redis.conf
# vim redis4/redis.conf
# vim redis5/redis.conf
# vim redis6/redis.conf
例如redis2/redis.conf中需要把所有7001都换成7002
可以使用:%/7001/7002/g进行全局修改
port 7002
cluster-config-file node-7002.conf
pidfile /var/run/redis_7002.pid
4.启动6个redis
# vim startup.sh
先启用编辑状态,在粘贴下面内容
cd redis1
./redis-server redis.conf
cd ..
cd redis2
./redis-server redis.conf
cd ..
cd redis3
./redis-server redis.conf
cd ..
cd redis4
./redis-server redis.conf
cd ..
cd redis5
./redis-server redis.conf
cd ..
cd redis6
./redis-server redis.conf
cd ..
# chmod a+x startup.sh
# ./startup.sh
5.查看启动状态
ps aux | grep redis

6.建立集群
在redis3de1时候需要借助ruby脚本实现集群.在redis5中可以使用自带的redis-cli实现集群功能,比redis3的时候更加方便了
建议配置静态ip,ip改变集群失效
# cd redis1
# ./redis-cli --cluster create 192.168.232.132:7001 192.168.232.132:7002 192.168.232.132:7003 192.168.232.132:7004 192.168.232.132:7005 192.168.232.132:7006 --cluster-replicas 1
执行完命令后,询问是否按照当前配置创建集群,输入yes而不是y

7.测试
集群测试时,千万不要忘记最后一个-c参数
# ./redis-cli -p 7001 -c
# set age 18
8.编写关闭脚本
# cd /usr/local/redis-cluster
# vim stop.sh
# chmod a+x stop.sh
./redis1/redis-cli -p 7001 shutdown
./redis2/redis-cli -p 7002 shutdown
./redis3/redis-cli -p 7003 shutdown
./redis4/redis-cli -p 7004 shutdown
./redis5/redis-cli -p 7005 shutdown
./redis6/redis-cli -p 7006 shutdown
九.Jedis
Redis给Java语言提供了客户端API,称之为Jedis
JedisAPI和Redis命令几乎是一样的
例如:Redis对String值新增时set命令,Jedis中也是set方法.所以本课程中没有重点把所有方法进行演示,重要演示Jedis如何使用
JedisAPI特别简单,基本上都是创建对象调用方法即可.由于Jedis不具备把对象转换为字符串的能力,所以每次都需要借助Hson转换工具进行转换,这个功能在Spring Data Redis中已经具备,推荐使用Spring Data Redis
1.添加依赖
2.单机版
public void testStandalone(){
Jedis jedis = new Jedis("192.168.232.132",6379);
jedis.set("name","root-standalone");
String value = jedis.get("name");
System.out.println(value);
}
3.带有连接池
public void testPool(){
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(5);
jedisPoolConfig.setMinIdle(3);
JedisPool jedisPool = new
JedisPool(jedisPoolConfig,"192.168.232.132",6379);
Jedis jedis = jedisPool.getResource();
jedis.set("name","root-pool");
String value = jedis.get("name");
System.out.println(value);
}
4.集群
public void testCluster(){
Set
set.add(new HostAndPort("192.168.232.132",7001));
set.add(new HostAndPort("192.168.232.132",7002));
set.add(new HostAndPort("192.168.232.132",7003));
set.add(new HostAndPort("192.168.232.132",7004));
set.add(new HostAndPort("192.168.232.132",7005));
set.add(new HostAndPort("192.168.232.132",7006));
JedisCluster jedisCluster = new JedisCluster(set);
jedisCluster.set("name","root");
String value = jedisCluster.get("name");
System.out.println(value);
}
十.使用SpringBoot整合SpringDataRedis操作redis
1.SpringDataRedis简介
Spring Data Redis好处很方便操作对象类型(基于POJO模型)
把Redis不同值得类型放到一个opsForXXX方法中
opsForValue:String值(最常用),如果存储Java对象或Java中时就需要使用序列化器,进行序列化
opsForList:列表List
opsForHash:哈希表Hash
opsForZSet:有序集合Sorted Set
opsForSet:集合
2.Spring Data Redis序列化器介绍
经常需要向Redis中保存Java中Object或List等类型,这个时候就需要通过序列化器把Java中对象转换为字符串进行存储
2.1JdkSerializationRedisSerializer
是RedisTemplate类默认的序列化方式.JdkSerializationRedisSerializer使用JDK自带的序列化方式.要求被序列化的对象必须实现java.io.Serializable接口,而且存储的内容为二进制数据,这对开发者是不友好的.会出现虽然不影响使用,但是直接使用Redis客户端查询Redis中数据时前面出现乱码问题
2.2OxmSerializer
以字符串格式的xml存储.解析起来也比较复杂,效率也比较低.已经很少有人在使用该序列化器.
2.3StringRedisSerializer
只能对String类型序列化操作.常用在key的序列化上
2.4GenericToStringSerializer
需要调用者给传递一个对象到字符串互转的Converter(转换器),使得比较麻烦
2.5Jackson2JsonRedisSerializer
该序列化器可以将对象自动转换为Json的形式存储,效率高且对调用者友好
优点:
速度快,序列化后的字符串短小精悍,不需要实现Serializable接口
缺点:
此类的构造函数中有一个类型参数,必须提供要序列化对象的类型信息(.class对象).如果存储List等带有泛型的类型,次序列化器是无法识别泛型的,会直接把泛型固定设置为LinkedHashMap
例如:存储时List
2.6GenericJackson2JsonRedisSerializer
与JacksonJsonRedisSerializer功能相似.底层依然使用Jackson工具包.相比Jackson2JsonRedisSerializer多了_class列,列里面存储类(新增时类型)的全限定路径,从Redis取出时根据_class类型进行转换,解决了泛型问题
该序列化器不需要指定对象类型信息(.class对象)使用Object最为默认类型.目前都使用这个序列化器
3.代码步骤
基于SpringTest单元测试演示
3.1添加依赖
3.2配置配置文件
spring.redis.host=localhost默认值
spring.redis.port=6379端口号默认值
如果连接Redis集群,不需要配置host,配置spring.redis.cluster.nodes,取值为redis集群所在ip:port,ip:port.由于word排版问题nodes后面取值没有和nodes在一行
spring:
redis:
host: 192.168.232.132
# cluster:
# nodes: 192.168.232.132:7001,192.168.232.132:7002,192.168.232.132:7003,192.168.232.132:7004,192.168.232.132:7005,192.168.232.132:7006
3.3编写配置类
@Configuration
public class RedisConfig{
@Bean
public RedisTemplate
RedisTemplate
redisTemplate.setConnectionFactory(factory);
redisTempalte.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}
}
3.4编写代码
3.4.1编写对象新增
@Autowired
private RedisTemplate
@Test
public void testString(){
People peo = new People(1,"张三");
redisTemplate.opsForValue().set("peo1",peo);
}
3.4.2.编写对象获取
@Test
public void testGetString(){
People peo = (People)redisTemplate.opsForValue().get("peo1");
System.out.println(peo);
}
3.4.3编写List
@Test
public void testList(){
List
list.add(new People(1,"张三"));
list.add(new People(2,"李四"));
redisTemplate.opsForValue().set("list2",list);
}
3.4.4编写List取值
@Test
public void testGetList(){
List
System.out.println(list2);
}
3.4.5判断Key是否存在
上面讲解Redis作为缓存工具时,需要判断key是否存在,通过hasKey进行判断
@Test
public void hasKey(){
Boolean result = redisTemplate.hasKey("name");
System.out.println(result);
}
3.4.6 根据key删除数据
如果key-value正常被删除,返回true,如果key不存在返回false
@Test
public void del(){
Boolean result = redisTemplate.delete("name");
System.out.println(result);
}
十一.高并发下Redis可能存在的问题及解决方案
1.缓存穿透(面试问题)
在实际开发中,添加缓存工具的目的,减少对数据库的访问次数,增加访问效率.
肯定会出现Redis中不存在的缓存数据.例如:访问id=-1的数据.可能出现绕过redis依然频繁访问数据库的情况,称为缓存穿透,多出现在查询为null的情况不被缓存时.
解决办法:
如果查询出来为null数据,把null数据依然放入到redis缓存中,同时设置这个key的有效时间比正常有效时间更短一些
if(list==null){
//key value有效时间 时间单位
redisTemplate.opsForValue().set(navKey,null,10,TimeUnit.MINUTES);
}else{
redisTemplate.opsForValue().set(navKey,result,7,TimeUnit.DAYS);
}
2.缓存击穿(面试问题)
实际开发中,考虑redis所在服务器中内存压力,都会设置key的有效时间.一定会出现键值对过期的情况.如果正好key过期了,此时出现大量并发访问,这些访问都会去访问数据库,这种情况称为缓存击穿
解决办法:
永久数据.
加锁.防止出现数据库的并发访问
2.1ReentrantLock(重入锁)
JDK对于并发访问处理的内容都放入了java.util.concurrent中
java.util.concurrent
ReentrantLock性能和synchronized没有区别的,但是API使用起来更加方便
@SpringBootTest
public class MyTest{
@Test
public void test(){
new Thread(){
@Override
public void run(){
test2("第一个线程11111");
}
}.start();
new Thread(){
@Override
public void run(){
test2("第二个线程22222");
}
}.start();
try{
Thread.sleep(20000);
}catch(InterruptedException e){
e.printStackTrace();
}
}
ReentrantLock lock = new ReentrantLock();
public void test2(String who){
lock.lock();
if(lock.isLocked()){
System.out.println("开始执行:"+who);
try{
Thread.sleep(5000);
}catch(InterruptedException e){
e.printStackTrace();
}
System.out.println("执行完:"+who);
lock.unlock();
}
}
}
2.2解决缓存击穿实例代码
只有在第一次访问时和key过期时才会访问数据库.对于性能来说没有过大影响,因为平时都是直接访问redis
private ReentrantLock lock = new ReentrantLock();
@Override
public Item selectById(Integer id){
String key = "item:"+id;
if(redisTemplate.hasKey(key)){
return (Item)redisTemplate.opsForValue().get(key);
}
lock.lock();
if(lock.isLocked()){
Item item = itemDubboService.selectById(id);
//由于设置了有效时间,就可能出现缓存击穿问题
redisTemplate.opsForValue().set(key,item,7,TimeUnit.DAYS);
lock.unlock();
return item;
}
//如果加锁失败,为了保护数据库,直接返回null
return null;
}
3.缓存雪奔(面试问题)
在一段时间内容,出现大量缓存数据失效,这段时间内容数据库的访问评率骤增,这种情况称为缓存雪奔
解决办法:
永久生效
自动以算法.例如:随机有效时间.让所有key尽量避开同一时间段
int seconds = random.nextInt(10000);
redisTemplate.opsForValue().set(key,item,100+seconds,TimeUnit.SECONDS);