Python爬虫学习笔记_DAY_20_Python爬虫之xpath的使用方法介绍【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I.xpath的安装
II.xpath的基本语法
I.xpath的安装
在第一部分安装的介绍之前,先介绍一下什么是xpath,以及为什么我们要学习xpath:
XPath是一门在XML文档中查找信息的语言。XPath可用来在XML文档中对元素和属性进行遍历。
通俗的说,xpath可以用来精确的定位和切割某个标签,标签指的是我们的html文件的源码中的标签,例如、
那么这个和我们的爬虫有什么关系呢?在之前的笔记中,我们大体上只获得过页面的源代码,这很大程度是不够的,我们需要的是精确的信息,这些信息就需要从混乱的源码中提取出来,而xpath就提供了这样的一种方法。总结,我们用xpath来精确提取html源码中的信息。
下面我们进行xpath的安装:
1️⃣ 在python的解释器所在的文件目录中Script文件夹内安装lxml库:
lxml库包含了我们需要的xpath,因此我们需要先安装lxml库,这个库要怎么安装呢,这里提供了详细的步骤:
首先,我们打开pycharm,选中File - - - > setting:
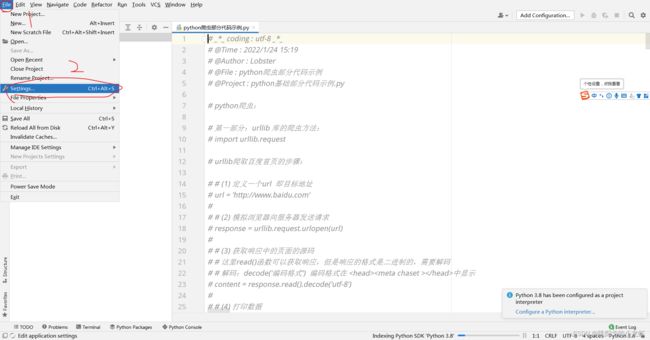
打开后,选择Project - - - > Python Interpreter:
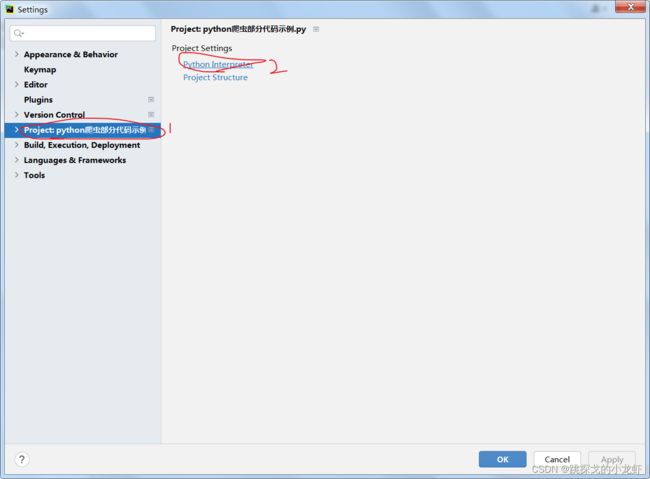
之后能够看到python interpreter 的路径,我们可以选择进入这个路径,也可以稍后手打路径,我这边推荐我们先进入这个路径对应的文件,也即我们进入Python38文件夹。

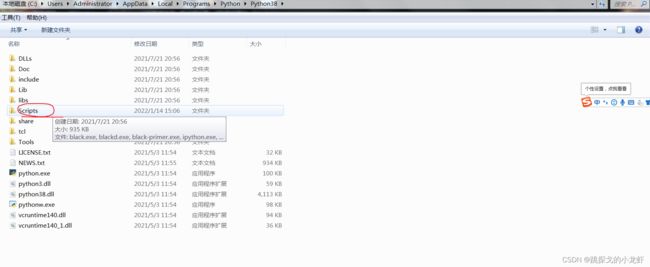
之后我们打开终端(Win + R,而后输入cmd),并输入指令:cd
之后我们不必手打后面的路径,而是可以把Scripts文件拖动到cd的光标后(cd后面要留一个空格!) :
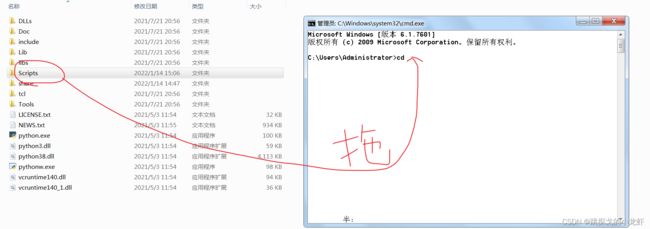
拖动后,路径会被自动输入,我们回车确认即可。而后我们通过终端进入了Scripts文件夹,之后我们输入这句指令安装lxml库:
pip install lxml -i https://pypi.douban,com/simple安装后,我们就可以在pycharm中导入lxml库中的xpath了,导入xpath的代码是这样的:
from lxml import etree2️⃣ 接下来我们安装浏览器插件:xpath插件:
针对谷歌浏览器的朋友,打开自己的扩展程序:
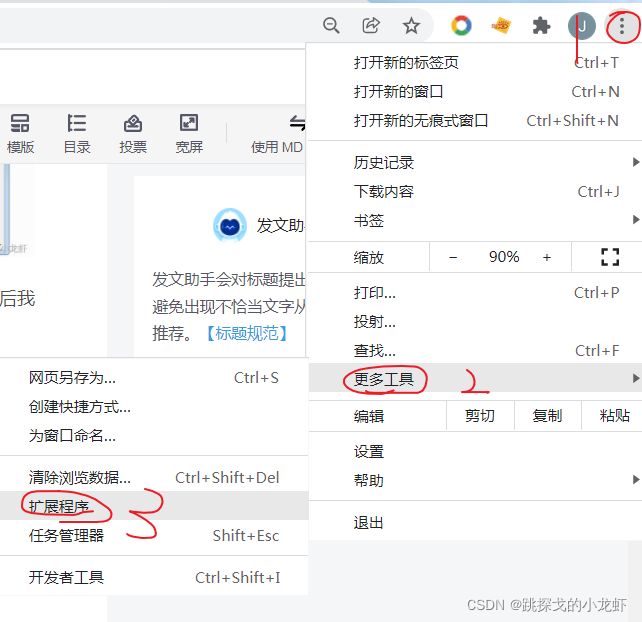
而后保持扩展程序被打开的状态,我们下载xpath的zip文件(提取码:dxzj):
点击链接下载xpath
下载后,不要解压zip,而是把这个zip文件拖入我们刚才打开的扩展程序页面,之后xpath插件就会被自动安装在浏览器上了:
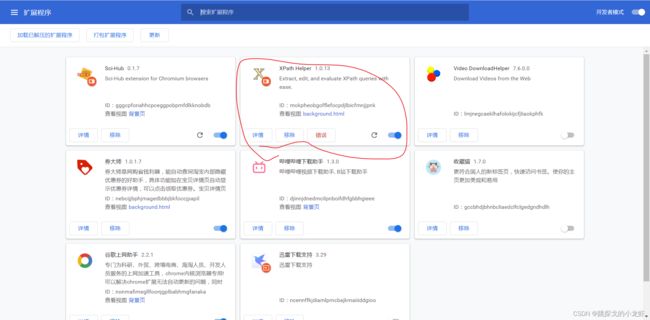
II.xpath的基本语法
xpath的基本语法,都展示在了下面的示例代码中,这些语法与正则表达式很类似:
# 解析:xpath的基础使用
from lxml import etree
# xpath解析
# 1. 本地文件:etree.parse
# 2. 解析服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()
# xpath解析本地文件
tree = etree.parse('new.html')
# 查找ul下面的li
li_list = tree.xpath('//body//li')
# 判断列表的长度:length
print(li_list)
print(len(li_list))
# 查找带有id属性的li标签
li_list = tree.xpath('//ul/li[@id]')
print(li_list)
print(len(li_list))
# 获取标签的内容:text()
li_list = tree.xpath('//ul/li[@id]/text()')
print(li_list)
print(len(li_list))
# 获取指定id的标签,属性值id要加引号
li_list = tree.xpath('//ul/li[@id = "l1"]/text()')
print(li_list)
# 查找指定id的标签的class属性值
li_list = tree.xpath('//ul/li[@id = "l1"]/@class')
print(li_list)
# 模糊查询:
(1) id中含有l的li标签
li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
print(li_list)
# (2) id的值以l开头的li标签
li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
print(li_list)
# 逻辑运算:
# (1) 查询id为l1和class为c1的标签:
li_list = tree.xpath('//ul/li[@id = "l1" and @ class = "c1"]/text()')
print(li_list)
# (2) 查询id为l1或l2的标签:
li_list = tree.xpath('//ul/li[@id = "l1"]/text() | //ul/li[@id = "l2"]/text()')
print(li_list)
# xpath解析服务器响应文件:从百度主页html文件中提取百度主页的标题:百度一下 四个字
# (1) 获取源码
import urllib.request
url = "https://www.baidu.com/"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# print(content)
# (2) xpath解析服务器响应的文件
from lxml import etree
# 解析服务器响应的文件的核心操作:
tree = etree.HTML(content)
# 注意xpath的返回数据类型是列表,我们可以用索引值:
result = tree.xpath('//input[@id = "su"]/@value')[0]
print(result)最后强调一下,xpath既可以处理本地html文件,也可以处理服务器的响应html文件,这是它的一个特性,这个特性在后面其他的提取技术(jsonpath)中可能不具备!