爬虫入门学习笔记 Day 4
目录
- 一、lxml模块中的etree.tostring函数的使用
- 二、selenium自动化测试框架
-
- 1.selenium简介
-
- (1)工作原理
- (2)安装selenium以及chromedriver
- (3)账务标签对象click点击以及send_key输入
- 2.selenium提取数据
-
- (1)driver对象的常用属性和方法
- (2)示例代码
-
- 示例代码1:如何使用page_source、current_url、title
- 示例代码2:如何使用forward()、back()
- 示例代码3:如何截图
- (3)元素定位
- 三、补充知识点
一、lxml模块中的etree.tostring函数的使用
1.etree.tostring ()方法用来将_Element对象转换成字符串。
2.代码(用回day3学习笔记里面的lxml的标签):
from lxml import etree
text = '''
'''
#将html源码创建成element对象
html = etree.HTML(text)
#etree.HTML()能自动补全html缺失的标签
print(etree.tostring(html))
3.输出结果(etree.HTML()会自动补全html的语法):
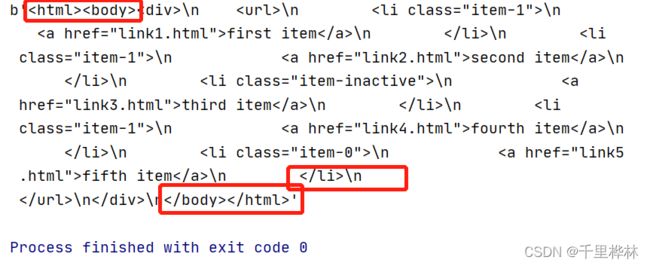
二、selenium自动化测试框架
能大幅度降低爬难度,但是也会大幅度降低爬取速度。
1.selenium简介
(1)工作原理
代码——调用webdriver——操作浏览器
不同的浏览器使用不同的driver。
(2)安装selenium以及chromedriver
安装selenium模块:
在pycharm的terminal输入:
pip install selenium
下载符合版本的webdriver:
1.获取浏览器版本:
设置——帮助——关于Google Chrome
2.根据浏览器版本下载驱动:(下载完后要解压)
下载的网址
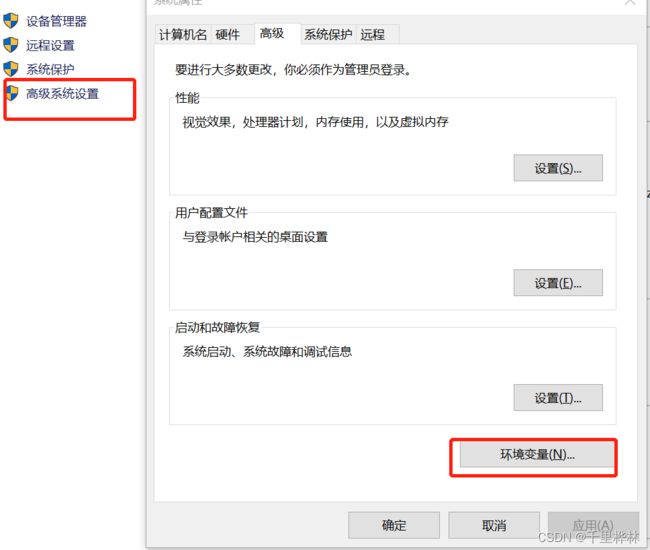
3.配置环境:(windows)
我的电脑——属性——高级系统设置——环境变量——path(将下载的驱动exe文件路径添加进去)
![]()
(3)账务标签对象click点击以及send_key输入
简单使用:
import time
from selenium import webdriver
#通过指定chromedriver的路径来实例化driver对象,chromedriver放在当前目录。
# driver = webdriver.Chrome(executable_path='./chromdriver')
#chromedriver已经添加环境变量
driver = webdriver.Chrome()
#控制浏览器访问url
driver.get("https://www.baidu.com/")
time.sleep(3)
#在百度搜索框中搜索‘python’
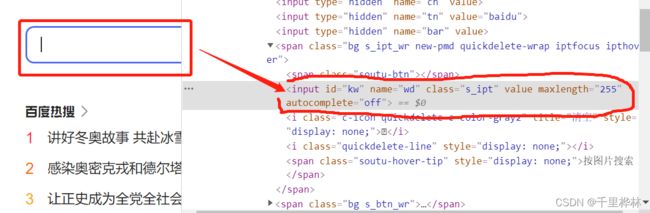
driver.find_element_by_id('kw').send_keys('python')
#点击‘百度搜索’
driver.find_element_by_id('su').click()
time.sleep(6)
#退出浏览器
driver.quit()
executable参数指定的是下载好的chromedriver文件的路径(如果已经配置好了环境就不要写参数了)
driver.find_element_by_id(‘kw’).send_keys(‘python’):定位id属性是‘kw’的标签,并向其中输入字符串‘python’
click()触发点击事件。
2.selenium提取数据
(1)driver对象的常用属性和方法
driver.page_source 当前标签页浏览器渲染之后的网页源代码
driver.current_url 当前标签页的url
driver.close() 关闭当前标签页,如果只有一个标签页则关闭整个浏览器
driver.quit() 关闭浏览器
driver.forward() 页面前进
driver.back() 页面后退
driver.screen_shot(img_name) 页面截图
(2)示例代码
示例代码1:如何使用page_source、current_url、title
from selenium import webdriver
url = 'http://www.baidu.com'
#创建一个浏览对象
driver = webdriver.Chrome()
#访问指定的url地址
driver.get(url)
#显示源码
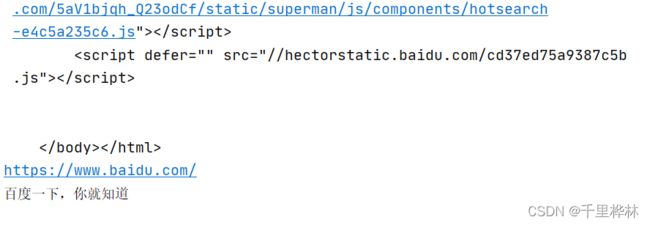
print(driver.page_source)
print(driver.current_url)
print(driver.title)
运行:会自动打开百度,然后再run窗口可以看到源码和url还要百度的标题。
示例代码2:如何使用forward()、back()
import time
from selenium import webdriver
url = 'http://www.baidu.com'
driver = webdriver.Chrome()
driver.get(url) #第一步打开百度页面
time.sleep(2)
driver.get('http://www.douban.com') #第二步打开豆瓣页面
time.sleep(2)
driver.back() #后退回百度页面
time.sleep(2)
driver.forward() #前进回到豆瓣
time.sleep(2)
driver.close() #关闭页面
示例代码3:如何截图
(截图的作用:有的时候可以用于通过验证码,先将验证码截图下来再提取出来,如果直接下载验证码的图片,图片的内容会变动)
import time
from selenium import webdriver
url = 'http://www.baidu.com'
driver = webdriver.Chrome()
driver.get(url) #第一步打开百度页面
#截图
driver.save_screenshot('baidu.png')
driver.quit()
(3)元素定位
driver对象定位标签元素获取标签对象的方法:
find_element_by_id (返回一个元素)
find_element(s)_by_class_name (根据类名获取元素列表)
find element(s)_by_name (根据标签的nane属性值返回包含标签对象元素的列表)
find element(s)_by_xpath (返回一个包含元素的列表)
find_element(s)_by_link_text (根据连接文本获取元素列表)
find_element(s)_by_partial_link_text (根据链接包含的文本获取元素列表) find_element(s)_by_tag_name (根据标签名获取元素列表)
find_element(s)_by_css (根据css选择器来获取元素列表)
element多了个s就返回列表,没有s就返回匹配到的第一个标签对象。
find_element匹配不到就抛出异常,加了s匹配不到就返回空列表。
代码:(根据百度的搜索框的属性来写代码)
import time
from selenium import webdriver
url = 'http://www.baidu.com'
driver = webdriver.Chrome()
driver.get(url) #第一步打开百度页面
#下面的代码可以一个个分别解开注释,运行一下
#通过xpath进行元素定位
# driver.find_element_by_xpath('//*[@id="kw"]').send_keys('python3')
#通过css选择器进行元素定位
# driver.find_element_by_css_selector('#kw').send_keys('python3')
#通过name属性值进行元素定位
# driver.find_element_by_name('wd').send_keys('python3')
#通过class属性值进行元素定位
# driver.find_element_by_class_name('s_ipt').send_keys('python3')
# driver.find_element_by_id('su').click()
#通过链接文本进行元素定位
# driver.find_element_by_link_text()
#通过部分的链接进行元素定位
# driver.find_element_by_partial_link_text('hao123').click()
# 目标元素再当前html中是唯一标签的时候或者是众多定位出来的标签中的第一个的时候才能使用
# print(driver.find_element_by_tag_name('title'))
使用elements的例子:提取58房产的标题
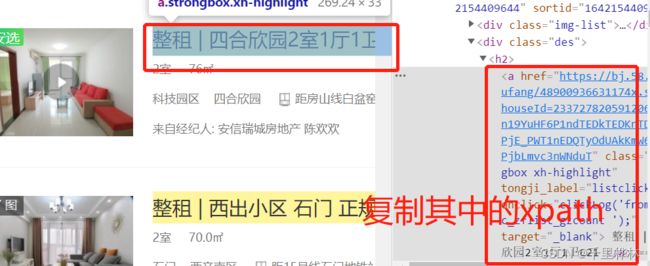
注意:因为每一块是用
- 标签分组的,所以要将li的索引删掉才可以选中所有的标题。
-
代码:
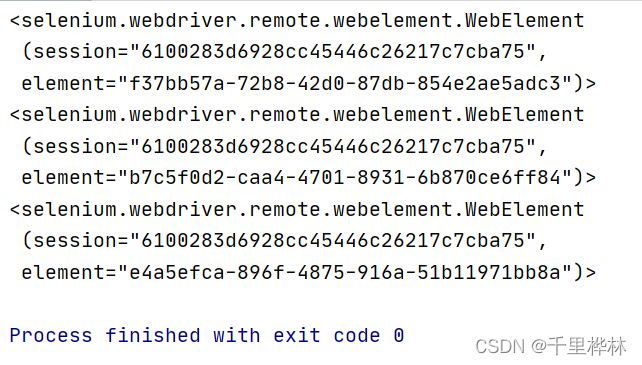
import time from selenium import webdriver url = 'https://bj.58.com/chuzu/?PGTID=0d200001-0000-1fd0-27cd-e5f5a55e18c9&ClickID=1' driver = webdriver.Chrome() driver.get(url) #取出标题 el_list = driver.find_elements_by_xpath('/html/body/div[6]/div[2]/ul/li/div[2]/h2/a') for el in el_list: print(el)运行:
三、补充知识点
1.有头浏览器和无头浏览器的使用场景
开发——有头
部署——无头