Python爬虫学习笔记_DAY_17_Python爬虫之使用cookie绕过登录的介绍【Python爬虫】
p.s.高产量博主,点个关注不迷路!
目录
I.什么是cookie?
首先,作为文章的第一部分,先介绍一下什么是cookie:
Cookie 并不是它的原意“甜饼”的意思, 而是一个保存在客户机中的简单的文本文件, 这个文件与特定的 Web 文档关联在一起, 保存了该客户机访问这个Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。由于“Cookie”具有可以保存在客户机上的神奇特性, 因此它可以帮助我们实现记录用户个人信息的功能, 而这一切都不必使用复杂的CGI等程序 。
举例来说, 一个 Web 站点可能会为每一个访问者产生一个唯一的ID, 然后以 Cookie 文件的形式保存在每个用户的机器上。如果使用浏览器访问 Web, 会看到所有保存在硬盘上的 Cookie。在这个文件夹里每一个文件都是一个由“名/值”对组成的文本文件,另外还有一个文件保存有所有对应的 Web 站点的信息。在这里的每个 Cookie 文件都是一个简单而又普通的文本文件。透过文件名, 就可以看到是哪个 Web 站点在机器上放置了Cookie(当然站点信息在文件里也有保存)
这是某度对cookie的介绍,用一句话总结就是cookie是携带了用户信息的标识,由于我们的HTTP协议是没有记忆的,通过cookie就能够将用户进行点对点的识别。当你进入某个网站并登录后,关闭网站再次进入,如果不需要再次登录而是直接进入登录状态,那么这个网站就是使用了cookie技术。
II.利用cookie绕过登录
这是我们的重点:利用cookie绕过登录。
需要这么做的原因在于当使用爬虫爬取一些网页时,这些网页对应的网站会将请求重定向到登录页面,也就是这样的一个逻辑顺序:
假设我们要爬取页面A,登录页面是页面B,当我们遇到会重定向到登录页面进行反爬的网站时,会出现:请求A - - - > 返回B 的效果,但是我们需要的效果是:请求A - - - > 返回A,此时就需要cookie绕过登录的操作:
# 数据的采集时,绕过登录,进入某个页面,这是cookie登录
import urllib.request
url = 'https://xxx'
headers = {
# cookie中携带着登录信息,如果有登陆之后的cookie,那我们可以携带者cookie进入到任何页面
'cookie': 'xxx',
# referer 判断当前路径是不是由referer链接进来的 如果不是从这个链接进入,则不可访问
'referer': 'https://xxx',
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36',
}
request = urllib.request.Request(url = url,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# 保存本地
with open('xxx.html','w',encoding='utf-8')as fp:
fp.write(content)
cookie的具体值可以通过F12检查网络源代码后获取:按F12 - - - > 选择 Network - - - > Headers - - - > cookie,我以一个网站为例:
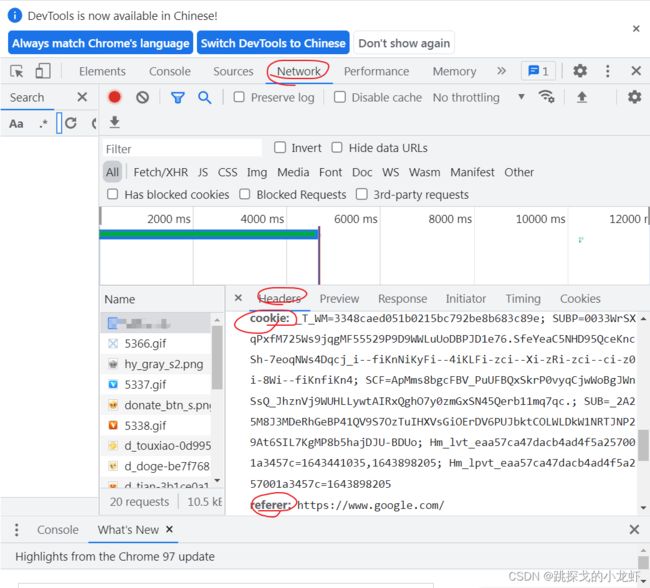
最后简单介绍一下参数referer,这个参数的含义是源url,也就是通过这个源url,我们进入了这个目标页面,因此很多的网站会通过referer这个源url参数来进行一个反爬判定,我们可以添加referer这个参数在headers里,作为对抗这一机制的方法!