Python爬虫学习笔记-第二十一课(Scrapy基础下)
Scrapy基础下
- 1. CrawlSpider入门
-
- 1.1 CrawlSpider预备知识点
- 1.2 创建CrawlSpider项目
- 1.3 案例练习——古诗文
- 3. 案例练习——小程序社区
-
- 3.1 思路分析
- 3.2 示例代码
- 4. Scrapy爬取图片
-
- 4.1 思路分析
- 4.2 示例代码
- 5. 使用Scrapy内置的下载文件
-
- 5.1 预备知识点
- 5.2 示例代码
1. CrawlSpider入门
1.1 CrawlSpider预备知识点
CrawlSpider的特点:
- 从response中提取所有的标签对应的url地址;
- 自动的构造resquests请求,发送给引擎。
LinkExtractors链接提取器:
使用LinkExtractors可以不用程序员自己提取想要的url,然后发送请求。这些⼯作都可以交给LinkExtractors,它会在所有爬取的页面中找到满⾜规则的url,实现自动的爬取。
class LxmlLinkExtractor(FilteringLinkExtractor):
def __init__(
self,
allow=(),
deny=(),
allow_domains=(),
deny_domains=(),
restrict_xpaths=(),
tags=('a', 'area'),
attrs=('href',),
canonicalize=False,
unique=True,
process_value=None,
deny_extensions=None,
restrict_css=(),
strip=True,
restrict_text=None,
)
主要参数讲解:
- allow:允许的url。所有满足这个正则表达式的url都会被提取;
- deny:禁⽌的url。所有满足这个正则表达式的url都不会被提取;
- allow_domains:允许的域名。只有在这个里面指定的域名的url才会被提取;
- deny_domains:禁止的域名。所有在这个里面指定的域名的url都不会被提取。
- restrict_xpaths:严格的xpath。和allow共同过滤链接。
Rule规则类
Rule是定义提取url地址的规则类。
class Rule:
def __init__(
self,
link_extractor=None,
callback=None,
cb_kwargs=None,
follow=None,
process_links=None,
process_request=None,
errback=None,
):
主要参数讲解:
- link_extractor:⼀个LinkExtractor对象,用于定义爬取规则;
- callback:满足这个规则的url,应该要执行的对应回调函数。因为CrawlSpider使用了parse作为回调函数,因此不要覆盖parse名字来定义自己的回调函数;
- follow:指定根据该规则从response中提取的链接是否需要跟进。
- process_links:从link_extractor中获取到链接后会传递给这个函数,用来过滤不需要爬取的链接。
1.2 创建CrawlSpider项目
创建scrapy项目的步骤是一样的。然后,尝试创建爬虫程序,命令格式如下:
# scrapy genspider -t crawl 爬虫的名字 域名
>>> scrapy genspider -t crawl cgsw gushiwen.org
运行结果:

对比普通的scrapy程序,CrawlSpider的框架中多了几项import,继承的父类也有所不同,代码着重写rules和回调函数。
1.3 案例练习——古诗文
代码需求:仍旧是爬取诗歌标题、作者、朝代、内容以及详情页的译文及注释。
网站链接:https://www.gushiwen.org/default_1.aspx
思路分析:
此处思路分析可参考笔者之前写的博客:https://blog.csdn.net/tzr0725/article/details/113360262
诗歌内容页
https://www.gushiwen.org/default_1.aspx 第一页
https://www.gushiwen.cn/default_2.aspx 第二页
诗歌详情页
https://so.gushiwen.cn/shiwenv_8979f027e5bf.aspx 第一页里面第一首诗词的详情页url
https://so.gushiwen.cn/shiwenv_506bcfd3e9ed.aspx 第一页里面第二首诗词的详情页url
整体思路与常规写法大体一致,先获取内容页的响应,解析数据,详情页的数据就交给callback函数处理。
需要注意的是:书写LinkExtractor里的参数时,对于内容页,它不需要callback函数,但是需要翻页,所以要将follow设为True;对于详情页,它需要callback函数(调用的是parse_item)处理译文数据,但是它不需要翻页,所以follow设为False。
代码书写:
最好检查settings.py文件中的配置,比如log级别、是否打开管道等等,这里笔者不再赘述。
还有,运行CrawlSpider的方法与普通scrapy程序一样,这里也略过了。
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CgswSpider(CrawlSpider):
name = 'cgsw'
allowed_domains = ['gushiwen.org', 'gushiwen.cn']
start_urls = ['https://www.gushiwen.org/default_1.aspx']
# 注意传递给Rule的url,采用正则表达式
rules = (
Rule(LinkExtractor(allow=r'https://www.gushiwen.cn/default_\d+.aspx'), follow=True),
Rule(LinkExtractor(allow=r'https://so.gushiwen.cn/shiwenv_\w+.aspx'), callback='parse_item', follow=False),
)
# 回调函数爬取译文数据
def parse_item(self, response):
item = {}
origin_translation = response.xpath('//div[@class="contyishang"]//p/text()').extract()
translation = ''.join(origin_translation).strip()
item['translation'] = translation
print(item)
return item
内容页和详情页的url要用到正则表达式书写(重点),所以要求传递到rule里的url不能太复杂,否则推荐用正常的scrapy方法写。
运行结果:

3. 案例练习——小程序社区
代码需求:爬取帖子的标题、作者和发帖时间。
网站链接:http://www.wxapp-union.com/portal.php?mod=list&catid=2
3.1 思路分析
观察不同页数的url,以及当前页面中帖子的详情页url:
列表页
http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1 第一页
http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=2 第二页
......
详情页
http://www.wxapp-union.com/article-6856-1.html
http://www.wxapp-union.com/article-6855-1.html
......
确认数据是静态的,且详情页的url地址也能在页面中找到,将列表页的url传递给Rule,让其自动follow就可实现自动翻页:
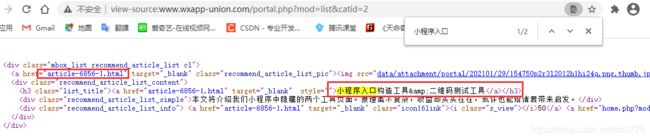
确认目标数据在网页源代码中存在,以及它们对应的标签如下图:
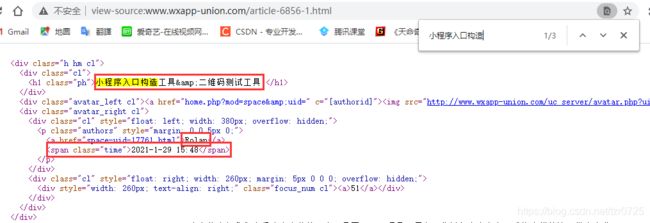
3.2 示例代码
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class SpSpider(CrawlSpider):
name = 'sp'
allowed_domains = ['wxapp-union.com']
start_urls = ['http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1']
rules = (
# 对元字符?进行单独转义
Rule(LinkExtractor(allow=r'http://www.wxapp-union.com/portal.php\?mod=list&catid=2&page=\d+'), follow=True),
Rule(LinkExtractor(allow=r'http://www.wxapp-union.com/article-\d+-1.html'), callback='parse_item'),
)
def parse_item(self, response):
item = {}
item['title'] = response.xpath('//h1[@class="ph"]/text()').extract_first() # 标题
item['author'] = response.xpath('//p[@class="authors"]/a/text()').extract_first() # 作者
item['pub_data'] = response.xpath('//p[@class="authors"]/span/text()').extract_first() # 时间
print(item)
return item
运行结果:

注意点:
- 写正则表达式时,注意符号
r不能对所有特殊字符进行转义,如果url中有元字符,需单独对其进行\转义。 - 如果发现能爬取数据,但无法翻页,可能会有以下错误:
- start_urls 有问题;
- 传递给Rule的url有问题,检查正则表达式书写是否正确;
4. Scrapy爬取图片
代码需求:爬取汽车之家网站上的图片。
网站链接:https://car.autohome.com.cn/photolist/series/48114/6299079.html#pvareaid=3454450
4.1 思路分析
还是先分析页面,确认图片的url是否在网页源码:


确认是静态数据后,先找到总的ul标签,在找它里面的li标签,最后在img标签里面的src属性,即可获得想要的图片url地址。
观察列表页url:
https://car.autohome.com.cn/photolist/series/48114/6299079.html#pvareaid=3454450
https://car.autohome.com.cn/photolist/series/18/p1/ # 这个也可以作为第一页的url
https://car.autohome.com.cn/photolist/series/18/p2/
https://car.autohome.com.cn/photolist/series/18/p3/
关于图片的名字,笔者提供一种思路,通过切割图片url的方式:
//car3.autoimg.cn/cardfs/product/g3/M05/93/A1/240x180_0_q95_c42_autohomecar__ChsEm1-OWcuAPnWJACOTrGrxzkA134.jpg
以上述url为例,假设想得到图片的名字为ChsEm1-OWcuAPnWJACOTrGrxzkA134.jpg,笔者在python交互模式简单演示:
>>> a = '//car3.autoimg.cn/cardfs/product/g3/M05/93/A1/240x180_0_q95_c42_autohomecar__ChsEm1-OWcuAPnWJACOTrGrxzkA134.jpg'
>>> b = a.split('__')
>>> b # 打印b的结果,是一个分割字符串后的列表
['//car3.autoimg.cn/cardfs/product/g3/M05/93/A1/240x180_0_q95_c42_autohomecar', 'ChsEm1-OWcuAPnWJACOTrGrxzkA134.jpg']
>>> b[-1] # 取最后一项
'ChsEm1-OWcuAPnWJACOTrGrxzkA134.jpg'
这样的命名好处在于不用担心重复(相比较于以汽车名字命名)。
完成图片命名后,继续讨论图片存放的路径,需要用到os模块,笔者在这也简单地演示一下后续用到的操作:
import os
# 把路径和文件名合成一个路径
# os.path.join('目录','文件名字')
print(os.path.join('目录','文件名字')) # 目录\文件名字
# 返回文件的路径
# os.path.dirname() 获取路径
print(__file__) # 打印当前.py脚本文件的位置
print(os.path.dirname(__file__)) # 打印当前.py脚本文件所在的路径
4.2 示例代码
items、settings里面的代码比较简单,笔者就不再展示了。
# piplines管道代码
from urllib import request
import os
class VehicleHomePipeline:
def process_item(self, item, spider):
pic_url = item['pic_url']
# 得到图片名字
pic_name = pic_url.split('__')[-1] # 得到xxx.jpg
# os.path.dirname(__file__) 结果 D:\PycharmProjects\spider\day21\vehicle_home\vehicle_home\
# 创建图片存放路径 xxx\vehicle_home\result_pic
pic_path = os.path.join(os.path.dirname(__file__), 'result_pic')
# 下载图片 xxx\vehicle_home\result_pic\xxx.jpg
request.urlretrieve(pic_url, pic_path + '/' + pic_name)
return item
# 爬虫代码
import scrapy
from day21.vehicle_home.vehicle_home.items import VehicleHomeItem
class VehPicSpider(scrapy.Spider):
name = 'veh_pic'
allowed_domains = ['car.autohome.com.cn']
base_url = 'https://car.autohome.com.cn/photolist/series/18/p{}/'
start_urls = [base_url.format(1)]
def parse(self, response):
# 获取图片标签列表
pic_lists = response.xpath('//ul[@id="imgList"]/li')
for pic in pic_lists:
pic_url = pic.xpath('./a/img/@src').extract_first()
# 上述获取的url需要进一步补全
pic_url = response.urljoin(pic_url)
item = VehicleHomeItem()
item['pic_url'] = pic_url
print(item)
yield item
# 翻页逻辑
for page in range(2, 3):
next_url = self.base_url.format(page)
yield scrapy.Request(next_url)
运行结果:

5. 使用Scrapy内置的下载文件
5.1 预备知识点
选择使用scrapy内置的下载文件的方法,其优点如下:
- 避免重新下载最近已经下载过的数据;
- 可以方便的指定文件存储的路径;
- 可以将下载的图片转换成通用的格式,如:png,jpg等;
- 可以方便地生成缩略图;
- 可以方便地检测图片的宽和⾼,确保它们满足最小限制;
- 异步下载,效率非常高。
下载图片的Images Pipeline
使用images pipeline下载文件步骤如下:
第一步,在items文件中定义两个属性,分别为image_urls以及images,这两个属性名字不能随意修改。
image_urls = scrapy.Field() # 图片的url
images = scrapy.Field() # 路径
第二步,编写爬虫程序,需要注意的是image_urls用来存储需要下载文件的url链接,需要给⼀个列表;
pic_url = pic.xpath('./a/img/@src').extract_first()
pic_url = response.urljoin(pic_url)
item['image_urls'] = [pic_url]
第三步,在settings中指定路径IMAGES_STORE = xxxxxxx,当图片下载完成后,scrapy会把图片下载的相关信息存储到item的images属性中,如下载路径、下载的url和图片校验码等;
import os
IMAGES_STORE = os.path.join(os.path.dirname(__file__), 'result_pic')
第四步,在settings中做配置,开启内置的图片管道,此时可以不用自带的管道。
'scrapy.pipelines.images.ImagesPipeline':1
5.2 示例代码
# 爬虫代码
import scrapy
from day21.vehicle_home.vehicle_home.items import VehicleHomeItem
class VehPicSpider(scrapy.Spider):
name = 'veh_pic'
allowed_domains = ['car.autohome.com.cn']
base_url = 'https://car.autohome.com.cn/photolist/series/18/p{}/'
start_urls = [base_url.format(1)]
def parse(self, response):
# 获取图片标签列表
pic_lists = response.xpath('//ul[@id="imgList"]/li')
for pic in pic_lists:
pic_url = pic.xpath('./a/img/@src').extract_first()
# 上述获取的url需要进一步补全
pic_url = response.urljoin(pic_url)
item = VehicleHomeItem()
item['image_urls'] = [pic_url] # 传递列表
print(item)
yield item
# 翻页逻辑
for page in range(2, 3):
next_url = self.base_url.format(page)
yield scrapy.Request(next_url)
# settings 代码,只给出关键部分
# 开启内置管道
ITEM_PIPELINES = {
# 'vehicle_home.pipelines.VehicleHomePipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 1,
}
# 指定图片存放路径
import os
IMAGES_STORE = os.path.join(os.path.dirname(__file__), 'result_pic')
# items 代码
import scrapy
class VehicleHomeItem(scrapy.Item):
image_urls = scrapy.Field() # 图片的url
images = scrapy.Field() # 图片路径
运行结果:
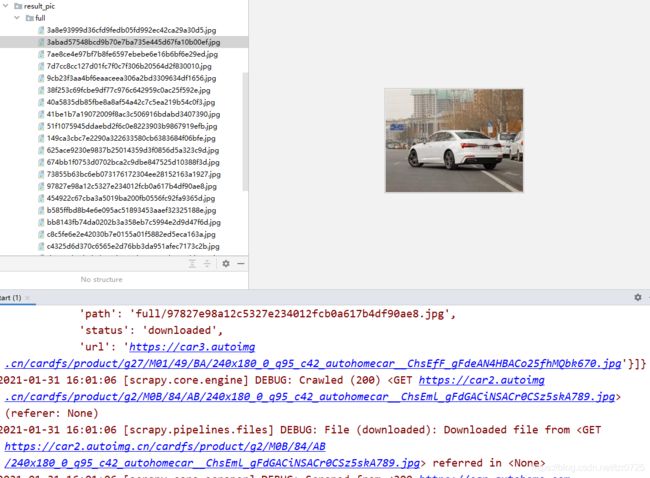
思路来源:解决问题的方式,从源码去发现解决的办法:
在settings中导入内置管道,点击ImagesPipeline查看对应的类;
from scrapy.pipelines.images import ImagesPipeline
跳转到images.py文件中找到如下方法,我们在上述程序中只给定了图片存储的路径,实际上下载完成后,图片保存的真实路径是指定的路径\full\xxx.jpg,还有图片的名字也是自动给的,这段操作就来源于以下代码:
def file_path(self, request, response=None, info=None, *, item=None):
image_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()
return f'full/{image_guid}.jpg'
内置管道源码中还有其它许多方法,有兴趣的读者可以自行研究一下。