1、Cookie 和 Session的区别?
Session技术:存到服务器端借助cookie存储JSESSIONID
session生命周期
创建:第一次指定request.getSession();
销毁:服务器关闭、session失效/过期、手动session.invalidate();
session作用范围:默认一会话中
Cookie技术:存到客户端,cookie以响应头的形式发送给客户端,cookie信息以请求头的方式发送到服务器端的,Cookie中不能存储中文。
2、get 和 post请求的区别?
GET产生一个TCP数据包;POST产生两个TCP数据包。
对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200;
而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200。并不是所有浏览器都会在POST中发送两次包,Firefox就只发送一次。
3、WEB容器主要有哪些功能? 并请列出一些常见的WEB容器名字。
作用:通信支持、servlet生命周期管理、多线程支持、声明式实现安全、jsp支持
Tomcat、JBoss、WebLogic、WebSphere
4、请简述 Servlet 的生命周期及其相关的方法?
servlet的生命周期:
a)实例化,由web容器实例化servlet实例
b)初始化,容器调用init()方法
c)服务,客户端请求servlet时,容器调用service()方法
d)销毁,结束服务调用destroy()方法
e)垃圾回收
init方法:在一个Servlet的生命周期中,init方法只会被执行一次,init方法负责简单的创建或者加载一些数据,这些数据将用于该Servlet的整个生命周期中。
service方法:service方法用来处理客户端的请求,并生成格式化数据返回给客户端。 每一次请求服务器都会开启一个新的线程并执行一次service方法,service根据客户端的请求类型,调用doGet、doPost等方法。
destroy方法:该方法在整个生命周期中,也是只会被调用一次,在Servlet对象被销毁是调用,在servlet中,我们可以做一些资源的释放等操作,执行destory方法之后的servlet对象,会等待jvm虚拟机的垃圾回收机制择时回收。
doGet、doPost方法:实际的业务处理流程,service根据客户端的请求类型来自动匹配需要执行哪个方法。
5、简单讲讲 Tomcat 结构,以及其类加载器流程?
模块组成结构:Tomcat的核心组件就Connector和Container,一个Connector+一个Container(Engine)构成一个Service,Service就是对外提供服务的组件,有了Service组件Tomcat就能对外提供服务了,但光有服务还不行,还需要有环境让你提供服务才行,所以最外层的Server就是为Service提供了生存的土壤。
Connector是一个连接器,主要负责接受请求并把请求交给Container,Container就是一个容器,主要包含具有处理请求的组件。Service主要是为了关联Container与Connect,只有两个结合起来才能处理一个请求。Server负责管理Service集合,具体工作包括:对外提供一个接口访问Service,对内维护Service集合,包括管理Service生命周期等。
类加载器流程:Tomcat启动时,会创建以下4种类加载器:
1)Bootstrap引导类加载器:加载JVM启动所需的类,以及标准扩展类(位于jar/lib/ext上)
2)System系统类加载器:加载Tomcat启动时的类,比如bootstrap.jar通常在catalina.bat或catalina.sh中指定。指定位置位于CATALINA_HOME/bin下。
3)Common通用类加载器:加载tomcat使用以及应用通用的一些类,位于CATALINA_HOME/lib下,比如servlet-api.jar
4)webapp应用类加载器:每个应用在创建后,都会创建一个唯一的类加载器。该类加载器会加载位于WEB-INF/lib下的jar文件中的class和WEB-INF/classes下的class文件。
6、CDN实现原理
CDN全称是内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络“边缘”,使用户可以就近取得所需的内容,提高用户访问网站的响应速度。CDN=更智能的镜像+缓存+流量导流。
CDN的关键技术:双重认证技术、负载均衡、内容分发
CDN可简单的分为核心层和接入层。
1)核心层
核心层作为CDN网络层次结构中的顶端,核心节点是整个CDN网络运行、管理和维护的核心,所有的用户内容请求都会由核心节点进入CDN网络,并由CDN网络根据用户和网络的实际情况,为用户指定一个合理的CDN接入层节点进行服务。完成如下的主要功能:
a)负责所有用户的内容请求根据用户的信息做出准确的用户就近性判断,并根据判断的结果,将用户的请求分发到指定的分节点。
b)负责CDN的内容分发管理把需要服务的内容通过合适的格式和方式,分发到所有骨干CDN节点。
2)接入层
接入层作为CDN网络的边缘层,强调对用户的分布式服务,主要完成的功能包括:
●流媒体平台的缓存节点,提供分区高速内容缓存;
●广播业务分布点,提供两级应用广播服务;
●部分应用前端分布节点;
●通过分布的服务机制,提高服务能力,实现对客户服务的需求。
7、Maven和ANT有什么区别?
Ant仅仅是软件构建工具,而Maven的定位是软件项目管理和理解工具。Maven除了具备Ant的功能外,有以下主要的功能:
使用Project Object Model来对软件项目管理;
内置了更多的隐式规则,使得构建文件更加简单;
内置依赖管理和Repository来实现依赖的管理和统一存储;
内置了软件构建的生命周期;
8、什么是restful,讲讲你理解的restful?
REST:资源(Resources)的表现层状态转化。可以用一个URI(统一资源标识符)指向它,每种资源对应一个特定的URI。
什么是RESTful架构:
1)每一个URI代表一种资源;
2)客户端和服务器之间,传递这种资源的某种表现层;
3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
9、Web Server、Web Container 与 Application Server 的区别是什么?
1)Webserver又名http server:主要处理静态网页http,css,代表作apache,nginx,IIs。速度快。
2)Web container(容器)能处理servlet,asp,php,cgi,但也可以处理静态网页,就是不专业,比如Tomcat。
3)Application server包括Web container,还包括JMS、JPA、Transactions、Concurrency,ejb容器等技术,比如weblogic和webSphere,Sun Application server。tomcat+Spring+hibernate才能达到Applcaition server的功能。Application server能处理http,但不专业。
10、微服务(MicroServices)与巨石型应用(Monolithic Applications)之间的区别在哪里?
巨石型应用:将所有功能都部署在一个web容器中运行的系统。
优点:应用不那么复杂。
缺点:对于大规模的复杂应用,巨石型应用会显得特别笨重:要修改一个地方就要将整个应用全部部署;编译时间过长;回归测试周期过长;开发效率降低等。另外,巨石应用不利于更新技术框架,除非你愿意将系统全部重写。
微服务:将系统划分为不同的服务,服务划分有两个原则要遵循:
(1)每个服务应该尽可能符合单一职责原则—Single Responsible Principle,即每个服务只做一件事,并把这件事做好;
(2)参考Unix命令行工具的设计,Unix提供了大量的简单易用的工具,例如grep、cat和find。每个工具都小而美。
优点:
每个服务足够内聚,足够小,代码容易理解、开发效率提高
服务之间可以独立部署,微服务架构让持续部署成为可能;
每个服务可以各自进行x扩展和z扩展,而且,每个服务可以根据自己的需要部署到合适的硬件服务器上;
容易扩大开发团队,可以针对每个服务(service)组件开发团队;
提高容错性(fault isolation),一个服务的内存泄露并不会让整个系统瘫痪;
系统不会被长期限制在某个技术栈上。
缺点:
开发人员要处理分布式系统的复杂性;开发人员要设计服务之间的通信机制,对于需要多个后端服务的user case,要在没有分布式事务的情况下实现代码非常困难;涉及多个服务直接的自动化测试也具备相当的挑战性;
服务管理的复杂性,在生产环境中要管理多个不同的服务的实例,这意味着开发团队需要全局统筹(PS:现在docker的出现适合解决这个问题)
11、描述 Cookie 和 Session 的作用,区别和各自的应用范围,Session工作原理?
Session:用于保存每个用户的专用信息,每个客户端用户访问时,服务器都为每个用户分配一个唯一的会话ID(Session ID) , 它的生存期是用户持续请求时间再加上一段时间(一般是20分钟左右),Session中的信息保存在Web服务器内容中,保存的数据量可大可小。当 Session超时或被关闭时将自动释放保存的数据信息,由于用户停止使用应用程序后它仍然在内存中保持一段时间,因此使用Session对象保存用户数据的方法效率很低,对于小量的数据使用Session对象保存还是一个不错的选择。
Cookie:用于保存客户浏览器请求服务器页面的请求信息,程序员也可以用它存放非敏感性的用户信息,信息保存的时间可以根据需要设置,如果没有设置Cookie失效日期,它们仅保存到关闭浏览器程序为止。如果将Cookie对象的Expires属性设置为Minvalue,则表示Cookie永远不会过期,Cookie存储的数据量很受限制,大多数浏览器支持最大容量为4K,因此不要用来保存数据集及其他大量数据。由于并非所有的浏览器都支持Cookie,并且数据信息是以明文文本的形式保存在客户端的计算机中,因此最好不要保存敏感的,未加密的数据,否则会影响网站的安全性。
session工作原理
(1)当有Session启动时,服务器生成一个唯一值,称为Session ID。
(2)然后服务器开辟一块内存,对应于该Session ID。
(3)服务器再将该Session ID写入浏览器的cookie。
(4)服务器内有一进程,监视所有Session的活动状况,如果有Session超时或是主动关闭,服务器就释放该内存块。
(5)当浏览器连入IIS时并请求的ASP内用到Session时,IIS就读浏览器Cookie中的Session ID。
(6)然后服务检查该Session ID所对应的内存是否有效。
(7)如果有效,就读出内存中的值。
(8)如果无效,就建立新的Session。
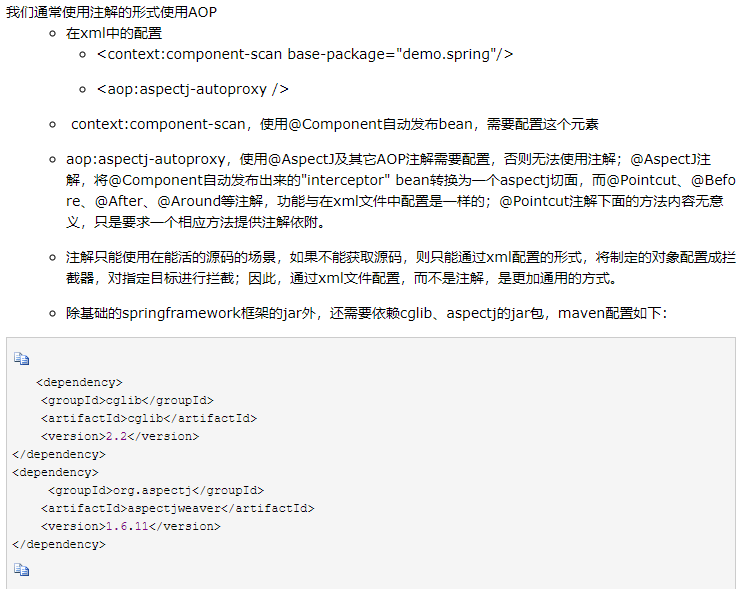
12、什么是基于注解的切面实现?
AOP :在程序运行时,动态的将代码切入到类的指定方法、指定位置上的编程思想就是面向切面编程。AOP基本上是通过代理机制实现的。
总结:Spring实现AOP,动态代理技术的两种实现是jdk动态代理、cglib代理,根据被通知的方法是否为接口方法,来选择使用哪种代理生成策略。
jdk动态代理:原理是实现接口的实例,拦截定于接口中的目标方法,性能更优,是spring生成代理的优先选择。
cglib代理:原理是使用cglib库中的字节码动态生成技术,生成被代理类的子类实例,可以拦截代理类中的任一public方法的调用,无论目标方法是否定义与接口中,更通用,但性能相对jdk代理差一些。
13、IOC的优缺点是什么?
优点:所有的对象都必须创建,我们可以从Ioc容器中直接获得一个对象然后直接使用,无需事先创建它们。
缺点:生成一个对象的步骤变复杂了,对象生成是使用反射机制,在效率上有损耗。
14、解释一下什么叫AOP(面向切面编程)?
Spring的AOP代理离不开Spring的IOC容器,代理的生成、管理及其依赖关系都是由IOC容器负责,默认使用JDK动态代理,在需要代理类而不是代理接口的时候,Spring会自动切换为使用CGLIB代理。
1)Aspect(切面):通常是一个类,里面可以定义切入点和通知
2)JointPoint(连接点):程序执行过程中明确的点,一般是方法的调用
3)Advice(通知):AOP在特定的切入点上执行的增强处理,before、after、afterReturning、
afterThrowing、around
4)Pointcut(切入点):就是带有通知的连接点,在程序中主要体现为切入点表达式
5)AOP代理:AOP框架创建的对象,代理就是目标对象的加强。Spring中的AOP代理可以使JDK动态代理,也可以是CGLIB代理,前者基于接口,后者基于子类。
15、什么是 Web Service(Web服务)?
WebService是一种跨编程语言和跨操作系统平台的远程调用技术。采用HTTP协议传输数据,采用XML格式封装数据。
XML+XSD,SOAP和WSDL就是构成WebService平台的三大技术。
16、JSWDL开发包的介绍。JAXP、JAXM、SOAP、UDDI、WSDL解释。
Web ServiceWeb Service是基于网络的、分布式的模块化组件,它执行特定的任务,遵守具体的技术规范,这些规范使得Web Service能与其他兼容的组件进行互操作。
JAXP(Java API for XML Parsing) 定义了在Java中使用DOM, SAX, XSLT的通用的接口。
JAXM(Java API for XML Messaging) 是为SOAP通信提供访问方法和传输机制的API。
SOAP即简单对象访问协议(Simple Object Access Protocol),它是用于交换XML编码信息的轻量级协议。
UDDI是一套基于Web的、分布式的、为Web Service提供的、信息注册中心的实现标准规范,同时也包含一组使企业能将自身提供的Web Service注册,以使别的企业能够发现的访问协议的实现标准。
WSDL是一种XML格式,用于将网络服务描述为一组端点,这些端点对包含面向文档信息或面向过程信息的消息进行操作。这种格式首先对操作和消息进行抽象描述,然后将其绑定到具体的网络协议和消息格式上以定义端点。相关的具体端点即组合成为抽象端点(服务)。
17、RPC 通信和RMI区别?
1)方法调用方式不同:
RMI中是通过在客户端的Stub对象作为远程接口进行远程方法的调用。每个远程方法都具有方法签名。如果一个方法在服务器上执行,但是没有相匹配的签名被添加到这个远程接口(stub)上,那么这个新方法就不能被RMI客户方所调用。
RPC中是通过网络服务协议向远程主机发送请求,请求包含了一个参数集和一个文本值,通常形成“classname.methodname(参数集)”的形式。RPC远程主机就去搜索与之相匹配的类和方法,找到后就执行方法并把结果编码,通过网络协议发回。
2)适用语言范围不同:
RMI只用于Java;
RPC是网络服务协议,与操作系统和语言无关。
3)调用结果的返回形式不同:
Java是面向对象的,所以RMI的调用结果可以是对象类型或者基本数据类型;
RMI的结果统一由外部数据表示 (External Data Representation, XDR) 语言表示,这种语言抽象了字节序类和数据类型结构之间的差异。
18、什么是 N 层架构?
分层架构的一个重要原则是:每层只能与位于其下方的层发生耦合
19、什么是CORBA?用途是什么?
CORBA(Common Object Request Broker Architecture:公共对象请求代理体系结构,通用对象请求代理体系结构)是由OMG组织制订的一种标准的面向对象应用程序体系规范。
用途:
1)存取来自现行桌面应用程序的分布信息和资源;
2)使现有业务数据和系统成为可供利用的网络资源;
3)为某一特定业务用的定制的功能和能力来增强现行桌面工具和应用程序;
4)改变和发展基于网络的系统以反映新的拓扑结构或新资源;
20、什么是懒加载(Lazy Loading)?
“懒加载模式”又叫“懒汉模式”是指当第一次使用到这个属性时才给这个属性对应的成员变量进行初始化,如果程序还没运行到这个地方就不进行相应的创建和初始化有利于节省资源提高性能。与之对应的还用一种模式叫做“饿汉模式”就是程序一启动就初始化相应的成员变量,不管当时有没有用到先创建并初始化了再说,所以这种模式相对来说不需要程序员考虑那么详细,会耗费一点资源。
21、什么是尾递归,为什么需要尾递归?
尾递归是指所有递归形式的调用,一定是发生在函数的末尾。形式上只要最后一个return语句是单纯函数就可以。
尾递归的好处:
尾递归和一般的递归不同在对内存的占用,普通递归创建stack累积而后计算收缩,尾递归只会占用恒量的内存(和迭代一样)。
JVM本身是不支持尾递归优化的,需要编译器支持,而Java编译器不支持,但是Scala支持。
22、什么是控制反转(Inversion of Control)与依赖注入(Dependency Injection)?
IoC (Inversion of Control),把对象的操控调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”就是对组件对象控制权的转移,从程序代码本身转移到了外部容器。
IoC主要实现方式有两种:
1)依赖查找(Dependency Lookup):容器提供回调接口和上下文环境给组件。
2)依赖注入(Dependency Injection):组件不做定位查询,只提供普通的Java方法让容器去决定依赖关系。后者是时下最流行的IoC类型,其又有接口注入(Interface Injection),设值注入(Setter Injection)和构造函数注入(Constructor Injection)三种方式。
23、XML文档定义有几种形式?它们之间有何本质区别?解析XML有哪几种方式?DOM和SAX解析器有什么不同?
两种形式:dtd、schema
区别:schema本身是xml的,可以被XML解析器解析(这也是从DTD上发展schema的根本目的);
有DOM、SAX、STAX等方式
DOM:处理大型文件时性能下降的非常厉害。这是由DOM的树结构造成的,这种结构占用的内存较多,而且DOM必须在解析文件前把整个文档装入内存,适合对XML的随机访问。
SAX:不限于DOM,SAX是事件驱动型的XML解析方式。它顺序读取XML文件,不需要一次全部装载整个文件。当遇到像文件开头,文档结束,或者标签开头与标签结束时,它会触发一个事件,用户通过在其回调事件中写入处理代码来处理XML文件,适合对XML的顺序访问。
STAX:Streaming API for XML (StAX)
24、Java解析XML的方式
XML解析方式分为四种:DOM、SAX、JDOM、DOM4J。
25、用jdom解析xml文件时如何解决中文问题?
XMLOutputter docWriter = new XMLOutputter();
docWriter.setFormat(Format.getCompactFormat().setEncoding("GB2312"));
26、描述动态代理的几种实现方式,分别说出相应的优缺点?
动态代理有Java Proxy,CGLib,JAVAssist等方式。
jdk动态代理是由Java内部的反射机制来实现的,cglib动态代理底层则是借助asm来实现的。总的来说,反射机制在生成类的过程中比较高效,而asm在生成类之后的相关执行过程中比较高效(可以通过将asm生成的类进行缓存,这样解决asm生成类过程低效问题)。注意:jdk动态代理的应用前提,目标类必须是基于统一的接口。
27、解释什么是MESI协议(缓存一致性)?
m:modified
e:exlusive
s:shared
i:invalid
四种状态的转换略过,现在讨论为什么有这个协议,i++在多线程上不是安全的。
两个cpu A B同时执行i++操作,假设i初始值为0
A读入i,缓存行状态为E
B读入i,发现A有,那么设置为s,A里面也设置为S
A cpu处理,i值+1等于1,但只是在寄存器中,没写入缓存,此时状态还是S
B cpu处理,i值+1等于1,同上还是S
A写入缓存,i值为1,缓存行状态为M,此时B的缓存行状态为I(无效)
B cpu写入的时候,发现缓存行无效,需要从内存读取,此时发现A的缓存行中有且为M状态,那么要求A刷新入内存,此时内存的i为1,A的缓存行为E,B读入自己的缓存(还是从A那里获取?),此时AB的缓存行都为S,i值都为1
B cpu写入,注意,此时是把1,赋值给1,B的状态为M,A为I(以后略)
这样就看出来了,缓存一致性协议是保证不了内存一致性的。
28、谈谈reactor模型
Reactor模型和AWT事件模型很像,就是将消息放到一个队列中,通过异步线程池对其进行消费。
29、UML中有哪些常用的图
UML定义了多种图形化的符号来描述软件系统部分或全部的静态结构和动态结构,包括:用例图(use case diagram)、类图(class diagram)、时序图(sequence diagram)、协作图(collaboration diagram)、状态图(statechart diagram)、活动图(activity diagram)、构件图(component diagram)、部署图(deployment diagram)等。
有三种图最为重要,分别是:
用例图(用来捕获需求,描述系统的功能,通过该图可以迅速的了解系统的功能模块及其关系)
类图(描述类以及类与类之间的关系,通过该图可以快速了解系统)
时序图(描述执行特定任务时对象之间的交互关系以及执行顺序,通过该图可以了解对象能接收的消息也就是说对象能够向外界提供的服务)。
30、什么是 N+1 难题
1+n是执行一次查询获取n条主数据后,由于关联引起的执行n次查询从数据;它带来了性能问题;一般来说,通过懒加载可以部分缓解1+n带来的性能问题。
31、介绍一下了解的 Java 领域的 Web Service 框架
开发Web Service的几个框架,分别为Axis,Axis2,Xfire,CXF以及JWS。
XFire:
XFire是一个高性能的WebService框架,优点是开发方便,与现有的Web整合很好,并且开发也很方便。但是对Java之外的语言,没有提供相关的代码工具。
1、支持一系列Web Service的新标准--JSR181、WSDL2.0 、JAXB2、WS-Security等;
2、使用Stax解释XML,性能有了质的提高。XFire采用Woodstox 作Stax实现;
3、容易上手,可以方便快速地从pojo发布服务;
4、Spring的结合;
5、灵活的Binding机制,包括默认的Aegis,xmlbeans,jaxb2,castor。
XFire与Axis1性能的比较
1、XFire比Axis1.3快2-6倍
2、XFire的响应时间是Axis1.3的1/2到1/5
Axis2:
Axis2是Apache下的一个重量级WebService框架,准确说它是一个Web Services / SOAP / WSDL的引擎,是WebService框架的集大成者,它不但能制作和发布WebService,而且可以生成Java和其他语言版WebService客户端和服务端代码。这是它的优势所在。但是,这也不可避免的导致了Axis2的复杂性,打包部署发布都比较麻烦,不能很好的与现有应用整合为一体。但是如果你要开发Java之外别的语言客户端,Axis2提供的丰富工具将是你不二的选择。
Axis2的开发方式类似一个小型的应用服务器,Axis2的开发包要以WAR的形式部署到Servlet容器中,比如Tomcat,通过这些容器可以对工作中的Web Service进行很好的监控和管理。Axis2的Web administrion模块可以让我们动态的配置Axis2。一个新的服务可以上载,激活,使之失效,修改web服务的参数。管理UI也可以管理一个或者多个处于运行状态的服务。这种界面化管理方式的一个弊端是所有在运行时修改的参数没有办法保存,因为在重启动之后,你所做的修改就会全部失效。Axis2允许自己作为独立的应用来发布Web Service,并提供了大量的功能和一个很好的模型,这个模型可以通过它本身的架构(modular architecture)不断添加新的功能。
CXF:
CXF是Apache下一个重磅的SOA简易框架,它实现了ESB(企业服务总线),来自于XFire项目,CXF不但是一个优秀的Web Services / SOAP / WSDL 引擎,也是一个不错的ESB总线,为SOA的实施提供了一种选择方案,当然他不是最好的,它仅仅实现了SOA架构的一部分。
CXF更注重开发人员的工效(ergonomics)和嵌入能力(embeddability)。大多数都可以通过配置API来完成,替代了比较繁琐的XML配置文件, Spring的集成性经常的被提及,CXF支持Spring2.0和CXF's API和Spring的配置文件可以非常好的对应。CXF强调代码优先的设计方式(code-first design),使用了简单的API使得从现有的应用开发服务变得方便。
JWS:
JWS是Java语言对WebService服务的一种实现,用来开发和发布服务。而从服务本身的角度来看JWS服务是没有语言界限的。
如何抉择:
1、如果应用程序需要多语言的支持,Axis2是首选;
2、如果应用程序是遵循Spring哲学路线的话,Apache CXF是一种更好的选择,特别对嵌入式的 Web Services来说;
3、如果应用程序没有新的特性需要的话,就仍是用原来项目所用的框架,比如 Axis1,XFire
32、Nginx、lighttpd、Apache三大主流 Web服务器的区别?
(1) lighttpd
Lighttpd有非常低的内存开销,cpu占用率低,效能好,以及丰富的模块等特点。支持FastCGI, CGI, Auth, 输出压缩(output compress), URL重写, Alias等重要功能。Lighttpd使用fastcgi方式运行php,它会使用很少的PHP进程响应很大的并发量。
Fastcgi的优点在于:
从稳定性上看, fastcgi是以独立的进程池运行来cgi,单独一个进程死掉,系统可以很轻易的丢弃,然后重新分配新的进程来运行逻辑.
从安全性上看, fastcgi和宿主的server完全独立, fastcgi怎么down也不会把server搞垮,
从性能上看, fastcgi把动态逻辑的处理从server中分离出来, 大负荷的IO处理留给宿主server
从扩展性上讲, fastcgi是一个中立的技术标准, 完全可以支持任何语言写的处理程序
(2)apache
1) 几乎可以运行在所有的计算机平台上
2) 支持最新的http/1.1协议
3) 简单而且强有力的基于文件的配置(httpd.conf)
4) 支持通用网关接口(cgi)
5) 支持虚拟主机
6) 支持http认证
7) 集成perl
8) 集成的代理服务器
9) 可以通过web浏览器监视服务器的状态, 可以自定义日志
10) 支持服务器端包含命令(ssi)
11) 支持安全socket层(ssl)
12) 具有用户会话过程的跟踪能力
13) 支持fastcgi
14) 支持java servlets
(3)nginx
是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP 代理服务器。
Nginx以事件驱动的方式编写,所以有非常好的性能,同时也是一个非常高效的反向代理、负载平衡。其拥有匹配Lighttpd的性能,同时还没有Lighttpd的内存泄漏问题。但是Nginx并不支持cgi方式运行,原因是可以减少因此带来的一些程序上的漏洞。所以必须使用FastCGI方式来执行PHP程序。
nginx做为HTTP服务器,有以下几项基本特性:
处理静态文件,索引文件以及自动索引;打开文件描述符缓冲.
无缓存的反向代理加速,简单的负载均衡和容错.
FastCGI,简单的负载均衡和容错.
模块化的结构。包括gzipping, byte ranges, chunked responses,以及SSI-filter等filter。如果由FastCGI或其它代理服务器处理单页中存在的多个SSI,则这项处理可以并行运行,而不需要相互等待。
Nginx专为性能优化而开发,性能是其最重要的考量,实现上非常注重效率。它支持内核Poll模型,能经受高负载的考验,有报告表明能支持高达50,000个并发连接数。
Nginx具有很高的稳定性。其它HTTP服务器,当遇到访问的峰值,或者有人恶意发起慢速连接时,也很可能会导致服务器物理内存耗尽频繁交换,失去响应,只能重启服务器。例如当前apache一旦上到200个以上进程,web响应速度就明显非常缓慢了。而Nginx采取了分阶段资源分配技术,使得它的CPU与内存占用率非常低。nginx官方表示保持10,000个没有活动的连接,它只占2.5M内存,所以类似DOS这样的攻击对nginx来说基本上是毫无用处的。就稳定性而言,nginx比lighthttpd更胜一筹。
Nginx支持热部署。它的启动特别容易, 并且几乎可以做到7*24不间断运行,即使运行数个月也不需要重新启动。你还能够在不间断服务的情况下,对软件版本进行进行升级。
(二)3种WEB服务器的比较:
Apache 后台服务器(主要处理php及一些功能请求 如:中文url)
Nginx 前端服务器(利用它占用系统资源少得优势来处理静态页面大量请求)
Lighttpd 图片服务器
33、HTTP连接池实现原理
http连接池就是一个池子,里面装满了连接,有两个特征:
1)连接池里面保存着可以马上通信的连接,免除了重新建立连接的麻烦
2)连接如果长期不用,就会挂断。
三个步骤:
1)查看有没有过期的连接,有则干掉
2)查看空闲的连接是不是过多,按时间顺序干掉一部分,先把老的干掉
3)如果没有东西要清理,清理线程则休息一下。当有连接进入的时候,就继续干活。
34、HTTPS和HTTP的区别
1)https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2)http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3)http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4)http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
35、HTTPS 的加密方式是什么,讲讲整个加密解密流程
HTTPS其实是有两部分组成:HTTP + SSL / TLS,也就是在HTTP上又加了一层处理加密信息的模块。服务端和客户端的信息传输都会通过TLS进行加密,所以传输的数据都是加密后的数据。
1)客户端发起HTTPS请求
2)服务端的配置
采用HTTPS协议的服务器必须要有一套数字证书,可以自己制作,也可以向组织申请。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用受信任的公司申请的证书则不会弹出提示页面。这套证书其实就是一对公钥和私钥。
3)传送证书
这个证书其实就是公钥,只是包含了很多信息,如证书的颁发机构,过期时间等等。
4)客户端解析证书
这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随机值。然后用证书对该随机值进行加密。
5)传送加密信息
这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
6)服务段解密信息
服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。所谓对称加密就是,将信息和私钥通过某种算法混合在一起,这样除非知道私钥,不然无法获取内容,而正好客户端和服务端都知道这个私钥,所以只要加密算法够彪悍,私钥够复杂,数据就够安全。
7)传输加密后的信息
这部分信息是服务端用私钥加密后的信息,可以在客户端被还原。
8)客户端解密信息
客户端用之前生成的私钥解密服务端传过来的信息,于是获取了解密后的内容。整个过程第三方即使监听到了数据,也束手无策。
36、什么是领域模型(domain model)?贫血模型(anaemic domain model) 和充血模型(rich domain model)有什么区别?
领域模型:是领域内的概念类或现实世界中对象的可视化表示,又称为概念模型或分析对象模型,它专注于分析问题领域本身,发掘重要的业务领域概念,并建立业务领域概念之间的关系。
贫血模型:是指使用的领域对象中只有setter和getter方法(POJO),所有的业务逻辑都不包含在领域对象中而是放在业务逻辑层。有人将贫血模型进一步划分成失血模型(领域对象完全没有业务逻辑)和贫血模型(领域对象有少量的业务逻辑)。
充血模型:将大多数业务逻辑和持久化放在领域对象中,业务逻辑只是完成对业务逻辑的封装、事务和权限等处理。
37、什么是领域驱动开发(Domain Driven Development)
将问题抽象为一个领域解决方案。并针对此领域(即抽象)进行开发的方式。
解决两个问题:变化、复杂度。
38、反射机制提供了什么功能?
1)在运行时判断任意一个对象所属的类;
2)在运行时构造任意一个类的对象;
3)在运行时判断任意一个类所具有的成员变量和方法;
4)在运行时调用任意一个对象的方法;
5)生成动态代理;
39、反射是如何实现的?
1)通过Class.forName()方法加载字符串,就可以得到该字符串做代表的Class对象。
2)通过类名调用class属性得到该类的Class对象。
3)调用实例的getClass()方法。
4)如果是基本类型的包装类,则可以通过调用包装类的Type属性来获得该包装类的Class对象。
40、哪里用到反射机制?
Tomcat服务器
41、反射中 Class.forName 和 ClassLoader 区别?
Class.forName(className)方法,内部实际调用的方法是Class.forName(className,true,classloader);
第2个boolean参数,表示类是否需要初始化,Class.forName(className)默认是需要初始化。
一旦初始化,就会触发目标对象的static块代码执行,static参数也也会被再次初始化。
ClassLoader.loadClass(className)方法,内部实际调用的方法是 ClassLoader.loadClass(className,false);
第2个boolean参数,表示目标对象是否进行链接,false表示不进行链接,意味着不进行包括初始化等一些列步骤,那么静态块和静态对象就不会得到执行。
42、反射创建类实例的三种方式是什么?
第一种,使用Class.forName静态方法。已明确类的全路径名。
第二种,使用.class 方法。仅适合在编译前就已经明确要操作的Class
第三种,使用类对象的 getClass() 方法,适合有对象示例的情况下
43、如何通过反射调用对象的方法?
1)通过Class.forName(“包名+方法的类名”)拿到方法的对象;
2)明确反射方法名称 ;
3)明确方法的参数类型,就可以拿到对象的方法。
如:Method method = clazz.getMethod("test",String.class,int.class);
4)用invoke()调用方法
Object obj1 = method.invoke(clazz.newInstance(),"test",23);
44、如何通过反射获取和设置对象私有字段的值?
通过类对象的getDeclaredField()方法字段对象,再通过字段对象的setAccessible(true)将其设置为可以访问,就可以通过get/set方法来获取/设置字段的值。
45、反射机制的优缺点?
优点:可以实现动态创建对象和编译,体现出很大的灵活性
缺点:对性能有影响,使用反射基本上是一种解释操作
46、什么是 paxos 算法?
在paxos算法中分为4种角色:Proposer(提议者)、Acceptor(决策者)、Client(产生议题者)、Learner(最终决策学习者)
上面4种角色中,提议者和决策者是很重要的,Proposer就像Client的使者,由Proposer使者拿着Client的议题去向Acceptor提议,让Acceptor来决策。Acceptor必须是最少大于等于3个,并且必须是奇数个,因为要形成多数派。该算法就是为了追求结果的一致性。
paxos算法中所有的行为:
1)Proposer提出议题
2)Acceptor初步接受或者Acceptor初步不接受
3)如果上一步Acceptor初步接受则Proposer再次向Acceptor确认是否最终接受
4)Acceptor最终接受或者Acceptor最终不接受
47、什么是 zab 协议?
1)ZAB协议是专门为zookeeper实现分布式协调功能而设计。zookeeper主要是根据ZAB协议实现分布式系统数据一致性。
2)zookeeper根据ZAB协议建立了主备模型完成zookeeper集群中数据的同步。这里所说的主备系统架构模型是指,在zookeeper集群中,只有一台leader负责处理外部客户端的事物请求(或写操作),然后leader服务器将客户端的写操作数据同步到所有的follower节点中。
3)ZAB的协议核心是在整个zookeeper集群中只有一个节点即Leader将客户端的写操作转化为事物(或提议proposal)。Leader节点在数据写完之后,将向所有的follower节点发送数据广播请求(或数据复制),等待所有的follower节点反馈。在ZAB协议中,只要超过半数follower节点反馈OK,Leader节点就会向所有的follower服务器发送commit消息。即将leader节点上的数据同步到follower节点之上。
4)ZAB协议中主要有两种模式,第一是消息广播模式;第二是崩溃恢复模式。
ZAB协议原理
1)ZAB协议要求每个leader都要经历三个阶段,即发现,同步,广播。
2)发现:即要求zookeeper集群必须选择出一个leader进程,同时leader会维护一个follower可用列表。将来客户端可以这follower中的节点进行通信。
3)同步:leader要负责将本身的数据与follower完成同步,做到多副本存储。这样也是体现了CAP中高可用和分区容错。follower将队列中未处理完的请求消费完成后,写入本地事物日志中。
4)广播:leader可以接受客户端新的proposal请求,将新的proposal请求广播给所有的follower。
Zookeeper设计目标
1)zookeeper作为当今最流行的分布式系统应用协调框架,采用zab协议的最大目标就是建立一个高可用可扩展的分布式数据主备系统。即在任何时刻只要leader发生宕机,都能保证分布式系统数据的可靠性和最终一致性。
2)深刻理解ZAB协议,才能更好的理解zookeeper对于分布式系统建设的重要性。以及为什么采用zookeeper就能保证分布式系统中数据最终一致性,服务的高可用性。
48、分布式事务的原理,优缺点,如何使用分布式事务?
定义:分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
CAP定理
WEB服务无法同时满足以下3个属性:
一致性(Consistency) : 客户端知道一系列的操作都会同时发生(生效)
可用性(Availability) : 每个操作都必须以可预期的响应结束
分区容错性(Partition tolerance) : 即使出现单个组件无法可用,操作依然可以完成
BASE理论
Basically Available(基本可用)
Soft state(软状态)
Eventually consistent(最终一致性)
BASE理论是对CAP中的一致性和可用性进行一个权衡的结果,核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
解决方案:
一、两阶段提交(2PC)
两阶段提交就是使用XA协议的原理,XA是一个两阶段提交协议,该协议分为以下两个阶段:
第一阶段:事务协调器要求每个涉及到事务的数据库预提交(precommit)此操作,并反映是否可以提交.
第二阶段:事务协调器要求每个数据库提交数据。
优点:尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能100%保证强一致)
缺点:实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景,如果分布式系统跨接口调用
二、补偿事务(TCC)
TCC其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
Try 阶段主要是对业务系统做检测及资源预留
Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行Confirm阶段时,默认Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
优点:跟2PC比起来,实现以及流程相对简单一些,但数据的一致性比2PC也要差一些
缺点:在2,3步中都有可能失败。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
三、本地消息表(异步确保)
本地消息表这种实现方式应该是业界使用最多的,其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于ebay。
基本思路就是:
消息生产方,需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方,需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
优点:一种非常经典的实现,避免了分布式事务,实现了最终一致性。
缺点:消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
四、MQ 事务消息
有一些第三方的MQ是支持事务消息的,比如RocketMQ,他们支持事务消息的方式也是类似于采用的二阶段提交,但是市面上一些主流的MQ都是不支持事务消息的,比如RabbitMQ和Kafka都不支持。
RocketMQ中间件其思路大致为:
第一阶段Prepared消息,拿到消息的地址。
第二阶段执行本地事务
第三阶段通过第一阶段拿到的地址去访问消息,并修改状态。
在业务方法内要向消息队列提交两次请求,一次发送消息和一次确认消息。如果确认消息发送失败了RocketMQ会定期扫描消息集群中的事务消息,这时候发现了Prepared消息,它会向消息发送者确认,所以生产方需要实现一个check接口,RocketMQ会根据发送端设置的策略来决定是回滚还是继续发送确认消息。这样就保证了消息发送与本地事务同时成功或同时失败。
优点: 实现了最终一致性,不需要依赖本地数据库事务。
缺点: 实现难度大,主流MQ不支持,没有.NET客户端,RocketMQ事务消息部分代码也未开源。
五、Sagas 事务模型
Saga事务模型又叫做长时间运行的事务(Long-running-transaction), 它描述的是另外一种在没有两阶段提交的的情况下解决分布式系统中复杂的业务事务问题。
该模型核心思想就是拆分分布式系统中的长事务为多个短事务,或者叫多个本地事务,然后由Sagas 工作流引擎负责协调,如果整个流程正常结束,那么就算是业务成功完成,如果在这过程中出现失败,那么Sagas工作流引擎就会以相反的顺序调用补偿操作,重新进行业务回滚。
49、分布式集群下如何做到唯一序列号?
1、数据库自增长序列或字段
优点:
1)简单,代码方便,性能可以接受。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
2)在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
3)在性能达不到要求的情况下,比较难于扩展。
4)如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
5)分表分库的时候会有麻烦。
优化方案:
针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。比如:Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3生成的是 3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
2、UUID
优点:
1)简单,代码方便。
2)生成ID性能非常好,基本不会有性能问题。
3)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
1)没有排序,无法保证趋势递增。
2)UUID往往是使用字符串存储,查询的效率比较低。
3)存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
4)传输数据量大
5)不可读。
3、UUID的变种
1)为了解决UUID不可读,可以使用UUID to Int64的方法。
2)为了解决UUID无序的问题,NHibernate在其主键生成方式中提供了Comb算法(combined guid/timestamp)。保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime)。
4、Redis生成ID
当使用数据库来生成ID性能不够要求的时候,可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。可以使用Redis集群来获取更高的吞吐量。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
5、Twitter的snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生4096个ID),最后还有一个符号位,永远是0。
snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)ID按照时间在单机上是递增的。
缺点:在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
6、利用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号来作为唯一的序列号。很少会使用zookeeper来生成唯一ID。主要是由于需要依赖zookeeper,并且是多步调用API,如果在竞争较大的情况下,需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
7、MongoDB的ObjectId
MongoDB的ObjectId和snowflake算法类似。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。使其在分片环境中要容易生成得多。
50、阐述下SOLID原则
SOLID是面向对象设计5大重要原则:
1)单一职责原则(SRP):一个类有且只有一个职责
2)开放封闭原则(OCP):一个类应该对扩展开放,对修改关闭
3)里氏替换原则(LSP):派生的子类应该是可替换基类的
4)接口隔离原则(ISP):类不应该被迫依赖他们不使用的方法
5)依赖倒置原则(DIP):高层模块不应该依赖低层模块,应该依赖抽象类或接口