前言
从kotlin1.1开始,协程就被添加到kotlin中作为实验性功能,直到kotlin1.3,协程在kotlin中的api已经基本稳定下来了,现在kotlin已经发布到了1.4,为协程添加了更多的功能并进一步完善了它,所以我们现在在kotlin代码中可以放心的引入kotlin协程并使用它,其实协程并不是kotlin独有的功能,它是一个广泛的概念,协作式多任务的实现,除了kotlin外,很多语言如Go、Python等都通过自己的方式实现了协程,本文阅读前希望你已经知道如何使用kotlin协程,如果不熟悉可以阅读一下官方文档:
Coroutine的简单理解
提到协程,很对人会把它和线程进行比较,就像提到线程,很多人会把它和进程进行比较,线程和进程分别是操作系统中的CPU调度单位和资源划分单位,它们在操作系统中有专门的数据结构代表,而协程在操作系统中没有专门的数据结构代表,所以协程并不是由操作系统创建和调度,它而是由程序自己创建和调度,由于不需要操作系统调度,所以协程比线程更加的轻量,切换协程比切换线程的开销更小,即它的上下文切换比线程更快,因为操作系统切换线程时一般都会涉及到用户态内核态的转换,这是一个开销相对较大的操作。
协程的实现依赖于线程,它不能脱离线程而存在,因为线程才是CPU调度的基本单位,协程通过程序的调度可以执行在一个或多个线程之中,所以协程需要运行于线程之中,由于协程是由程序自己调度的,所以程序就需要实现调度逻辑,不同语言的调度的实现不一样,在kotlin中,通过Dispatcher来调度协程,而Dispatcher它通常是一个线程池的实现或者基于特定平台(例如Android)主线程的实现,通过调度让协程运行于一个或多个线程之中,这些协程可以在同一线程的不同时刻被执行,也可以在不同线程上的不同时刻被执行。
协程可以说是编程语言的能力, 是上层的能力,它并不需要操作系统和硬件的支持, 是编程语言为了让开发者更容易写出协作式任务的代码,而封装的一种任务调度能力,所以协程通常是包含一段特定逻辑的代码块,多个协程之间就组合成一段具有特定逻辑的代码流程,这些编程语言为了让开发者更方便的使用协程,它通常会提供一些关键字, 而这些关键字会通过编译器自动生成了一些支持型代码,例如kotlin中的suspend关键字,对于suspend修饰的方法,编译器会方法生成一些额外的代码。
上面就是我对协程的简单理解,总的来说:协程需要线程的承载运行,协程需要程序自己完成调度,协程让你更容易写出协作式任务。
Coroutine的简单使用
fun main(){
val scope = CoroutineScope(CoroutineName("Coroutine-Name") + Dispatchers.IO)
val job = scope.launch(start = CoroutineStart.DEFAULT){
println("hello world")
}
//进程保活1s,只有进程存活的前提下,协程才能会启动和执行
Thread.sleep(1000)
}上面首先构造了一个CoroutineScope,它是协程的作用域,用于控制协程的生命周期,构造CoroutineScope需要一个CoroutineContext,它是协程的上下文,用于提供协程启动和运行时需要的信息,这是我们后面需要重点介绍的,最后通过CoroutineScope的launch方法启动协程并输出hello world,其中启动协程时可以通过CoroutineStart指定协程的启动模式,它是一个枚举值,默认是立即启动,也通过指定CoroutineStart.LAZY变为延迟启动,延迟启动需要你主动调用返回的Job对象的start方法后协程才会启动,如果我们想取消掉这个协程的执行就可以调用CoroutineScope的cancel方法,或者调用launch方法返回的Job对象的cancel方法,其实CoroutineScope的cancel方法内部也是调用返回的Job对象的cancel方法来结束这个协程。
上面就是启动一个协程的简单步骤,需要用到CoroutineScope、CoroutineContext、CoroutineStart。
通过自定义CoroutineScope,可以在应用程序的某一个层次开启或者控制协程的生命周期,例如Android,在ViewModel和Lifecycle类的生命周期里提供了CoroutineScope,分别是ViewModelScope和LifecycleScope.
CoroutineContext的元素
构造CoroutineScope使用到的CoroutineContext是一个特殊的集合,这个集合它既有Map的特点,也有Set的特点,集合的每一个元素都是Element,每个Element都有一个Key与之对应,对于相同Key的Element是不可以重复存在的,Element之间可以通过 + 号组合起来,后面我会详细介绍CoroutineContext这个特殊集合的结构,接下来我先简单讲解一下组成CoroutineContext的各个Element的作用,CoroutineContext主要由以下4个Element组成:
- Job:协程的唯一标识,用来控制协程的生命周期(new、active、completing、completed、cancelling、cancelled);
- CoroutineDispatcher:指定协程运行的线程(IO、Default、Main、Unconfined);
- CoroutineName: 指定协程的名称,默认为coroutine;
- CoroutineExceptionHandler: 指定协程的异常处理器,用来处理未捕获的异常.
它们之间的关系如下:

下面分别介绍一下4个Element各自的作用:
1、Job
public interface Job : CoroutineContext.Element {
public companion object Key : CoroutineContext.Key {
init {
CoroutineExceptionHandler
}
}
public val isActive: Boolean
public val isCompleted: Boolean
public val isCancelled: Boolean
public fun start(): Boolean
public fun cancel(cause: CancellationException? = null)
public suspend fun join()
public val children: Sequence
//...
} 通过CoroutineScope的扩展方法launch启动一个协程后,它会返回一个Job对象,它是协程的唯一标识,这个Job对象包含了这个协程任务的一系列状态,如下:
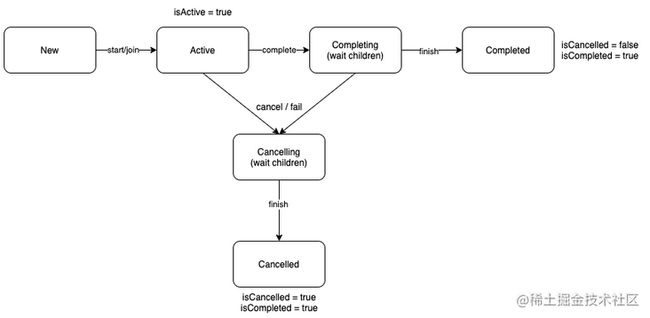
当一个协程创建后它就处于新建(New)状态,当调用Job的start/join方法后协程就处于活跃(Active)状态,这是运行状态,协程运行出错或者调用Job的cancel方法都会将当前协程置为取消中(Cancelling)状态, 处于取消中状态的协程会等所有子协程都完成后才进入取消 (Cancelled)状态,当协程执行完成后或者调用CompletableJob(CompletableJob是Job的一个子接口)的complete方法都会让当前协程进入完成中(Completing)状态, 处于完成中状态的协程会等所有子协程都完成后才进入完成(Completed)状态。
虽然协程有New、Cancelling、Completing状态,但是外部是无法感知这三个状态的,Job只提供了isActive、isCancelled、isCompleted属性来供外部判断协程是否处于Active、Cancelled、Completed状态,当协程处于Active状态时,isActive为true,isCancelled和isCompleted为false,当协程处于Cancelled状态时,isCancelled和isCompleted为true,isActive为false,当协程处于Completed状态时,isCompleted为true,isActive和isCancelled为false。
协程中有两种类型的Job,如果我们平时启动协程时没有特意地通过CoroutineContext指定一个Job,那么使用launch/async方法启动协程时返回的Job它会产生异常传播,我们知道协程有一个父子的概念,例如启动一个协程1,在协程中继续启动协程2、协程3,那么协程1就是协程2、协程3的父协程,协程2、协程3就是协程1的子协程,每个协程都会有一个对应的Job,协程之间的父子关系是通过Job对象维持的,像一颗树一样:

所以异常传播就是这个Job因为除了CancellationException以外的异常而失败时,那么父Job就会感知到并抛出异常,在抛出异常之前,父Job会取消所有子Job的运行,这也是结构化编程的一个特点,如果要抑制这种异常传播的行为,那么可以用到另外一种类型的Job - SupervisorJob,SupervisorJob它不是一个类,它是一个构造方法:
public fun SupervisorJob(parent: Job? = null) : CompletableJob = SupervisorJobImpl(parent)SupervisorJob方法会返回CompletableJob的一个supervisor实现,CompletableJob是Job的一个子接口,它比Job接口多了一个complete方法,这意味着它可以调用complete方法让协程任务进入完成状态,supervisor实现的意思是这个Job它不会产生异常传播,每个Job可以单独被管理,当SupervisorJob因为除了CancellationException以外的异常而失败时,并不会影响到父Job和其他子Job,下面是SupervisorJob的一个使用例子:
fun main(){
val parentJob = GlobalScope.launch {
//childJob是一个SupervisorJob
val childJob = launch(SupervisorJob()){
throw NullPointerException()
}
childJob.join()
println("parent complete")
}
Thread.sleep(1000)
}childJob抛出异常并不会影响parentJob的运行,parentJob会继续运行并输出parent complete。
2、CoroutineDispatcher
public abstract class CoroutineDispatcher : AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public companion object Key : AbstractCoroutineContextKey(
ContinuationInterceptor,
{ it as? CoroutineDispatcher }
)
public open fun isDispatchNeeded(context: CoroutineContext): Boolean = true
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
//...
} CoroutineDispatcher可以指定协程的运行线程,CoroutineDispatcher里面有一个dispatch方法,这个dispatch方法用于把协程任务分派到特定线程运行,kotlin已经内置了CoroutineDispatcher的4个实现,可以通过Dispatchers的Default、IO、Main、Unconfined字段分别返回使用,如下:
public actual object Dispatchers {
@JvmStatic
public actual val Default: CoroutineDispatcher = createDefaultDispatcher()
@JvmStatic
public val IO: CoroutineDispatcher = DefaultScheduler.IO
@JvmStatic
public actual val Unconfined: CoroutineDispatcher = kotlinx.coroutines.Unconfined
@JvmStatic
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
}2.1、Default、IO
Dispatchers.Default和Dispatchers.IO内部都是线程池实现,它们的含义是把协程运行在共享的线程池中,我们先看Dispatchers.Default的实现,看createDefaultDispatcher方法:
internal actual fun createDefaultDispatcher(): CoroutineDispatcher = if (useCoroutinesScheduler) DefaultScheduler else CommonPoolDefaultScheduler和CommonPool都是CoroutineDispatcher的子类,不同的是DefaultScheduler内部依赖的是kotlin自己实现的线程池逻辑,而CommonPool内部依赖的是java类库中的Executor,默认情况下useCoroutinesScheduler为true,所以createDefaultDispatcher方法返回的是DefaultScheduler实例,我们看一下这个DefaultScheduler:
internal object DefaultScheduler : ExperimentalCoroutineDispatcher() {
val IO: CoroutineDispatcher = LimitingDispatcher(
this,//DefaultScheduler实例被传进了LimitingDispatcher中
systemProp(IO_PARALLELISM_PROPERTY_NAME, 64.coerceAtLeast(AVAILABLE_PROCESSORS)),
"Dispatchers.IO",
TASK_PROBABLY_BLOCKING
)
//...
}DefaultScheduler中的IO字段就是Dispatchers.IO,它是LimitingDispatcher实例,所以Dispatchers.IO的实现是LimitingDispatcher,同时我们要注意到DefaultScheduler是用object字段修饰,这说明它是一个单例,并且DefaultScheduler实例被传进了LimitingDispatcher的构造方法中,所以LimitingDispatcher就会持有DefaultScheduler实例,而DefaultScheduler它的主要实现都在它的父类ExperimentalCoroutineDispatcher中:
@InternalCoroutinesApi
public open class ExperimentalCoroutineDispatcher(
private val corePoolSize: Int,
private val maxPoolSize: Int,
private val idleWorkerKeepAliveNs: Long,
private val schedulerName: String = "CoroutineScheduler"
) : ExecutorCoroutineDispatcher() {
public constructor(
corePoolSize: Int = CORE_POOL_SIZE,
maxPoolSize: Int = MAX_POOL_SIZE,
schedulerName: String = DEFAULT_SCHEDULER_NAME
) : this(corePoolSize, maxPoolSize, IDLE_WORKER_KEEP_ALIVE_NS, schedulerName)
private var coroutineScheduler = createScheduler()
//返回CoroutineScheduler实例
private fun createScheduler() = CoroutineScheduler(corePoolSize, maxPoolSize, idleWorkerKeepAliveNs, schedulerName)
override fun dispatch(context: CoroutineContext, block: Runnable): Unit =
try {
//dispatch方法委托给了CoroutineScheduler的dispatch方法
coroutineScheduler.dispatch(block)
} catch (e: RejectedExecutionException) {
//...
}
internal fun dispatchWithContext(block: Runnable, context: TaskContext, tailDispatch: Boolean) {
try {
//dispatchWithContext方法委托给了CoroutineScheduler的dispatch方法
coroutineScheduler.dispatch(block, context, tailDispatch)
} catch (e: RejectedExecutionException) {
//...
}
}
//...
}我们再看Dispatchers.IO对应的LimitingDispatcher实现:
private class LimitingDispatcher(
private val dispatcher: ExperimentalCoroutineDispatcher,//外部传进的DefaultScheduler实例
private val parallelism: Int,
private val name: String?,
override val taskMode: Int
) : ExecutorCoroutineDispatcher(), TaskContext, Executor {
private val queue = ConcurrentLinkedQueue()
private val inFlightTasks = atomic(0)
override fun dispatch(context: CoroutineContext, block: Runnable) = dispatch(block, false)
private fun dispatch(block: Runnable, tailDispatch: Boolean) {
var taskToSchedule = block
while (true) {
val inFlight = inFlightTasks.incrementAndGet()
if (inFlight <= parallelism) {
//LimitingDispatcher的dispatch方法委托给了DefaultScheduler的dispatchWithContext方法
dispatcher.dispatchWithContext(taskToSchedule, this, tailDispatch)
return
}
queue.add(taskToSchedule)
if (inFlightTasks.decrementAndGet() >= parallelism) {
return
}
taskToSchedule = queue.poll() ?: return
}
}
//...
} 从上面分析得知,Dispatchers.Default的实现是DefaultScheduler,Dispatchers.IO的实现是LimitingDispatcher,而LimitingDispatcher持有DefaultScheduler实例,把dispatch操作委托给DefaultScheduler,DefaultScheduler内部持有CoroutineScheduler实例,把dispatch操作委托给CoroutineScheduler,而DefaultScheduler又是一个单例,所以Dispatchers.Default和Dispatchers.IO它们共用同一个CoroutineScheduler实例,它们之间的关系如下:
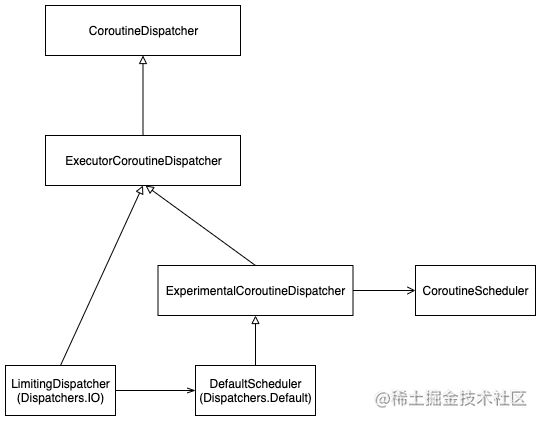
CoroutineScheduler就是kotlin自己实现的共享线程池,是Dispatchers.Default和Dispatchers.IO内部的共同实现,Dispatchers.Default和Dispatchers.IO共享CoroutineScheduler中的线程,DefaultScheduler和LimitingDispatcher的主要作用是对CoroutineScheduler进行线程数、任务数等配置,CoroutineScheduler使用工作窃取算法(Work Stealing)重新实现了一套线程池的任务调度逻辑,它的性能、扩展性对协程的任务调度更友好,具体的逻辑可以查看这个类的dispatch方法:
internal class CoroutineScheduler(
@JvmField val corePoolSize: Int,
@JvmField val maxPoolSize: Int,
@JvmField val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
@JvmField val schedulerName: String = DEFAULT_SCHEDULER_NAME
) : Executor, Closeable {
override fun execute(command: Runnable) = dispatch(command)
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
val task = createTask(block, taskContext)
//...
if (task.mode == TASK_NON_BLOCKING) {
//...
} else {
//...
}
}
//...
}所以这个线程池既可以运行两种类型的任务:CPU密集型任务和IO密集型任务,用一个mode来区别,当你为协程指定Dispatchers.Default时,Dispatcher会把协程的任务指定为CPU密集型任务,对应mode为TASK\_NON\_BLOCKING,当你为协程指定Dispatchers.IO时,Dispatcher会把协程的任务指定为IO密集型任务,对应mode为TASK\_PROBABLY\_BLOCKING,所以这时CoroutineScheduler就可以根据task mode作出不同的线程创建、调度、唤醒策略,当启动协程时没有指定Dispatcher,默认会使用Dispatchers.Default。
当运行CPU密集型任务时,CoroutineScheduler最多有corePoolSize个线程被创建,corePoolSize它的取值为max(2, CPU核心数),即它会尽量的等于CPU核心数,当运行IO密集型任务时,它可以创建比corePoolSize更多的线程来运行IO型任务,但不能大于maxPoolSize,maxPoolSize会取一个很大的值,默认为max(corePoolSize, min(CPU核心数 * 128, 2^21 - 2)),即大于corePoolSize,小于2^21 - 2,而2^21 - 2是一个很大的数约为2M,但是CoroutineScheduler是不可能创建这么多线程的,所以就需要外部限制提交的任务数,而Dispatchers.IO构造时就通过LimitingDispatcher默认限制了最大线程并发数parallelism为max(64, CPU核心数),即Dispatchers.IO最多只能提交parallelism个任务到CoroutineScheduler中执行,剩余的任务被放进一个队列中等待。
CPU密集型任务:CPU密集型任务的特点是执行任务时CPU会处于忙碌状态,任务会消耗大量的CPU资源,例如计算复杂的算术、视频解码等,如果此时线程数太多,超过了CPU核心数,那么这些超出来的线程是得不到CPU的执行的,只会浪费内存资源,因为线程本身也有栈等空间,同时线程过多,频繁的线程切换带来的消耗也会影响线程池的性能,所以对于CPU密集型任务,线程池并发线程数等于CPU核心数才能让CPU的执行效率最大化;
IO密集型任务:IO密集型任务的特点是执行任务时CPU会处于闲置状态,任务不会消耗大量的CPU资源,例如网络请求、IO操作等,线程执行IO密集型任务时大多数处于阻塞状态,处于阻塞状态的线程是不占用CPU的执行时间,这时CPU就处于闲置状态,为了让CPU忙起来,执行IO密集型任务时理应让线程的创建数量更多一点,理想情况下线程数应该等于提交的任务数,对于这些多创建出来的线程,当它们闲置时,线程池一般会有一个超时回收策略,所以大部分情况下并不会占用大量的内存资源,但也会有极端情况,所以对于IO密集型任务,线程池并发线程数应尽可能地多才能提高CPU的吞吐量,这个尽可能地多的程度并不是无限大,而是根据业务情况设定,但肯定要大于CPU核心数。
2.2、Unconfined
Dispatchers.Unconfined的含义是不给协程指定运行的线程,在第一次被挂起(suspend)之前,由启动协程的线程执行它,但被挂起后, 会由恢复协程的线程继续执行, 如果一个协程会被挂起多次, 那么每次被恢复后, 都有可能被不同线程继续执行,看下面的一个例子:
fun main(){
GlobalScope.launch(Dispatchers.Unconfined){
println(Thread.currentThread().name)
//挂起
withContext(Dispatchers.IO){
println(Thread.currentThread().name)
}
//恢复
println(Thread.currentThread().name)
//挂起
withContext(Dispatchers.Default){
println(Thread.currentThread().name)
}
//恢复
println(Thread.currentThread().name)
}
//进程保活
Thread.sleep(1000)
}
运行输出:
main
DefaultDispatcher-worker-1
DefaultDispatcher-worker-1
DefaultDispatcher-worker-3
DefaultDispatcher-worker-3协程启动时指定了Dispatchers.Unconfined,所以第一次执行时是由启动协程的线程执行,上面在主线程中启动了协程,所以第一次输出主线程main,withContext方法是一个suspend方法,它可以挂起当前协程,并把指定的代码块运行到给定的上下文中,直到代码块运行完成并返回结果,第一个代码块通过withContext方法把它运行在Dispatchers.IO中,所以第二次输出了线程池中的某一个线程DefaultDispatcher-worker-1,第一个代码块执行完毕后,协程在DefaultDispatcher-worker-1线程中恢复,所以协程恢复后执行在DefaultDispatcher-worker-1线程中,所以第三次继续输出DefaultDispatcher-worker-1,第二个代码块同理。
那么Dispatchers.Unconfined是怎么做到的呢,我们看下Unconfined对应的CoroutineDispatcher实现 - kotlinx.coroutines.Unconfined:
internal object Unconfined : CoroutineDispatcher() {
override fun isDispatchNeeded(context: CoroutineContext): Boolean = false
override fun dispatch(context: CoroutineContext, block: Runnable) {
// It can only be called by the "yield" function. See also code of "yield" function.
val yieldContext = context[YieldContext]
if (yieldContext != null) {
// report to "yield" that it is an unconfined dispatcher and don't call "block.run()"
yieldContext.dispatcherWasUnconfined = true
return
}
throw UnsupportedOperationException("Dispatchers.Unconfined.dispatch function can only be used by the yield function. " +
"If you wrap Unconfined dispatcher in your code, make sure you properly delegate " +
"isDispatchNeeded and dispatch calls.")
}
}Unconfined他重写了CoroutineDispatcher的isDispatchNeeded方法和dispatch方法,isDispatchNeeded方法返回了false,表示不需要dispatch,而默认CoroutineDispatcher的isDispatchNeeded方法是返回true的,Dispatchers.Default和Dispatchers.IO都没有重写这个方法,Unconfined的dispatch方法没有任何任务调度的逻辑,只是写明了只有当调用yield方法时,Unconfined的dispatch方法才会被调用,yield方法是一个suspend方法,当在协程中调用这个方法时表示当前协程让出自己所在的线程给其他协程运行,所以正常情况下是不会调用Unconfined的dispatch方法的。
在kotlin中每个协程都有一个Continuation实例与之对应,当协程恢复时会调用Continuation的resumeWith方法,它的实现在DispatchedContinuation中,如下:
internal class DispatchedContinuation(
@JvmField val dispatcher: CoroutineDispatcher,//协程的的CoroutineDispatcher实例
@JvmField val continuation: Continuation//代表协程的Continuation实例
) : DispatchedTask(MODE_UNINITIALIZED), CoroutineStackFrame, Continuation by continuation {
//...
override fun resumeWith(result: Result) {
val context = continuation.context
val state = result.toState()
if (dispatcher.isDispatchNeeded(context)) {
_state = state
resumeMode = MODE_ATOMIC
dispatcher.dispatch(context, this)
} else {//Unconfined走这里的逻辑
//调用executeUnconfined方法
executeUnconfined(state, MODE_ATOMIC) {
withCoroutineContext(this.context, countOrElement) {
//调用Continuation的resumeWith方法
continuation.resumeWith(result)
}
}
}
}
} 我们注意到by关键字,这是kotlin中的委托实现,DispatchedContinuation通过类委托加强了Continuation的resumeWith方法,即在调用Continuation的resumeWith方法之前增加了一些自己的逻辑,我们可以看到DispatchedContinuation的resumeWith方法中会根据CoroutineDispatcher的isDispatchNeeded方法返回值做出不同处理,当isDispatchNeeded方法返回true时,会调用协程的CoroutineDispatcher的dispatch方法,而当isDispatchNeeded方法返回false时,不会调用CoroutineDispatcher的dispatch方法而是调用executeUnconfined方法,上面讲到Unconfined的isDispatchNeeded方法返回了false,我们看executeUnconfined方法:
private inline fun DispatchedContinuation<*>.executeUnconfined(
contState: Any?,
mode: Int,
doYield: Boolean = false,
block: () -> Unit
): Boolean {
assert { mode != MODE_UNINITIALIZED }
//从ThreadLocal中取出EventLoop
val eventLoop = ThreadLocalEventLoop.eventLoop
if (doYield && eventLoop.isUnconfinedQueueEmpty) return false
//判断是否在执行Unconfined任务
return if (eventLoop.isUnconfinedLoopActive) {
_state = contState
resumeMode = mode
//调用EventLoop的dispatchUnconfined方法把Unconfined任务放进EventLoop中
eventLoop.dispatchUnconfined(this)
true
} else {
//执行Unconfined任务
runUnconfinedEventLoop(eventLoop, block = block)
false
}
}
internal inline fun DispatchedTask<*>.runUnconfinedEventLoop(
eventLoop: EventLoop,
block: () -> Unit
) {
eventLoop.incrementUseCount(unconfined = true)
try {
//先执行block代码块,block()就是executeUnconfined方法传进的代码块, block()里面会调用Continuation的resumeWith方法
block()
while (true) {
//再调用EventLoop的processUnconfinedEvent方法执行EventLoop中的Unconfined任务,直到EventLoop中的所有Unconfined任务执行完才跳出循环
if (!eventLoop.processUnconfinedEvent()) break
}
} catch (e: Throwable) {
//...
} finally {
eventLoop.decrementUseCount(unconfined = true)
}
}可以看到对于Unconfined任务,是在当前线程马上执行或者通过当前线程的EventLoop来执行的,EventLoop是存放在ThreadLocal中的,所以EventLoop它是跟当前线程相关联的,而EventLoop也是CoroutineDispatcher的一个子类:
internal abstract class EventLoop : CoroutineDispatcher() {
//...
private var unconfinedQueue: ArrayQueue>? = null
public fun dispatchUnconfined(task: DispatchedTask<*>) {
val queue = unconfinedQueue ?: ArrayQueue>().also { unconfinedQueue = it }
queue.addLast(task)
}
public fun processUnconfinedEvent(): Boolean {
val queue = unconfinedQueue ?: return false
val task = queue.removeFirstOrNull() ?: return false
task.run()
return true
}
} EventLoop中有一个双端队列用于存放Unconfined任务,Unconfined任务是指指定了Dispatchers.Unconfined的协程任务,EventLoop的dispatchUnconfined方法用于把Unconfined任务放进队列的尾部,processUnconfinedEvent方法用于从队列的头部移出Unconfined任务执行,所以executeUnconfined方法里面的策略就是:在当前线程立即执行Unconfined任务,如果当前线程已经在执行Unconfined任务,就暂时把它放进跟当前线程关联的EventLoop中,等待执行,同时Unconfined任务里面会调用Continuation的resumeWith方法恢复协程运行,这也是为什么指定了Dispatchers.Unconfined后协程恢复能够被恢复协程的线程执行的原因。
2.3、Main
Dispatchers.Main的含义是把协程运行在平台相关的只能操作UI对象的Main线程,所以它根据不同的平台有不同的实现,kotlin它支持下面三种平台:
- kotlin/js:kotlin/js是kotlin对JavaScript的支持,提供了转换kotlin代码,kotlin标准库的能力,npm包管理能力,在kotlin/js上Dispatchers.Main等效于Dispatchers.Default;
- kotlin/native:kotlin/native是一种将kotlin代码编译为无需虚拟机就可运行的原生二进制文件的技术, 它的主要目的是允许对不需要或不可能使用虚拟机的平台进行编译,例如嵌入式设备或iOS,在kotlin/native上Dispatchers.Main等效于Dispatchers.Default;
- kotlin/JVM:kotlin/JVM就是需要虚拟机才能编译的平台,例如Android就是属于kotlin/JVM,对于kotlin/JVM我们需要引入对应的dispatcher,例如Android就需要引入kotlinx-coroutines-android库,它里面有Android对应的Dispatchers.Main实现,其实就是把任务通过Handler运行在Android的主线程.
我们再看Dispatchers.Main的实现 - MainDispatcherLoader.dispatcher:
internal object MainDispatcherLoader {
@JvmField
val dispatcher: MainCoroutineDispatcher = loadMainDispatcher()
private fun loadMainDispatcher(): MainCoroutineDispatcher {
//...主要是通过反射加载实现了MainCoroutineDispatcher的类
}
}所以Dispatchers.Main的CoroutineDispatcher实现是MainCoroutineDispatcher,MainCoroutineDispatcher的具体实现就因平台的不同而不同了,如果你直接使用Dispatchers.Main而没有引入对应的库就会引发IllegalStateException异常。
3、CoroutineName
public data class CoroutineName(
val name: String
) : AbstractCoroutineContextElement(CoroutineName) {
public companion object Key : CoroutineContext.Key
override fun toString(): String = "CoroutineName($name)"
}
CoroutineName就是协程的名字,它的结构很简单, 我们平时开发一般是不会去指定一个CoroutineName的,因为CoroutineName只在kotlin的调试模式下才会被用的, 它在debug模式下被用于设置协程运行线程的名字:
internal data class CoroutineId(
val id: Long
) : ThreadContextElement, AbstractCoroutineContextElement(CoroutineId) {
override fun updateThreadContext(context: CoroutineContext): String {
val coroutineName = context[CoroutineName]?.name ?: "coroutine"
val currentThread = Thread.currentThread()
val oldName = currentThread.name
var lastIndex = oldName.lastIndexOf(DEBUG_THREAD_NAME_SEPARATOR)
if (lastIndex < 0) lastIndex = oldName.length
currentThread.name = buildString(lastIndex + coroutineName.length + 10) {
append(oldName.substring(0, lastIndex))
append(DEBUG_THREAD_NAME_SEPARATOR)
append(coroutineName)
append('#')
append(id)
}
return oldName
}
//...
} 4、CoroutineExceptionHandler
public interface CoroutineExceptionHandler : CoroutineContext.Element {
public companion object Key : CoroutineContext.Key
public fun handleException(context: CoroutineContext, exception: Throwable)
}
CoroutineExceptionHandler就是协程的异常处理器,用来处理协程运行中未捕获的异常,每一个创建的协程默认都会有一个异常处理器,我们可以在启动协程时通过CoroutineContext指定我们自定义的异常处理器,我们可以通过CoroutineExceptionHandler方法创建一个CoroutineExceptionHandler,它会返回一个CoroutineExceptionHandler的默认实现,默认实现的handleException方法中调用了我们传进的handler方法:
public inline fun CoroutineExceptionHandler(crossinline handler: (CoroutineContext, Throwable) -> Unit): CoroutineExceptionHandler =
object : AbstractCoroutineContextElement(CoroutineExceptionHandler), CoroutineExceptionHandler {
override fun handleException(context: CoroutineContext, exception: Throwable) =
handler.invoke(context, exception)
}CoroutineExceptionHandler只对launch方法启动的根协程有效,而对async启动的根协程无效,因为async启动的根协程默认会捕获所有未捕获异常并把它放在Deferred中,等到用户调用Deferred的await方法才抛出,如下:
fun main(){
//自定义CoroutineExceptionHandler
val handler = CoroutineExceptionHandler{ coroutineContext, throwable ->
println("my coroutineExceptionHandler catch exception, msg = ${throwable.message}")
}
//handler有效
val job = GlobalScope.launch(handler){
throw IndexOutOfBoundsException("exception thrown from launch")
}
job.start()
//handler无效
val deferred = GlobalScope.async(handler){
throw NullPointerException("exception thrown from async")
}
deferred.start()
Thread.sleep(1000)
}
输出:
my coroutineExceptionHandler catch exception, msg = exception thrown from launch其中只有launch启动的根协程抛出的异常才被CoroutineExceptionHandler处理,而对于async启动的根协程抛出的异常CoroutineExceptionHandler无效,需要我们调用Deferred的await方法时try catch。
还有子协程抛出的未捕获异常会委托父协程的CoroutineExceptionHandler处理,子协程设置的CoroutineExceptionHandler永远不会生效(SupervisorJob 除外),如下:
fun main(){
//根协程的Handler
val parentHandler = CoroutineExceptionHandler{coroutineContext, throwable ->
println("parent coroutineExceptionHandler catch exception, msg = ${throwable.message}")
}
//启动根协程
val parentJob = GlobalScope.launch(parentHandler){
//子协程的Handler
val childHandler = CoroutineExceptionHandler{coroutineContext, throwable ->
println("child coroutineExceptionHandler catch exception, msg = ${throwable.message}")
}
//启动子协程
val childJob = launch(childHandler){
throw IndexOutOfBoundsException("exception thrown from child launch")
}
childJob.start()
}
parentJob.start()
Thread.sleep(1000)
}
输出:
parent coroutineExceptionHandler catch exception, msg = exception thrown from child launch可以看到子协程设置CoroutineExceptionHandler没有输出,只有根协程的CoroutineExceptionHandler输出了,但是也有例外,如果子协程是SupervisorJob,那么它设置的CoroutineExceptionHandler是生效的,前面也说过SupervisorJob不会产生异常传播。
当父协程的子协程同时抛出多个异常时,CoroutineExceptionHandler只会捕获第一个协程抛出的异常,后续协程抛出的异常被保存在第一个异常的suppressed数组中,如下:
fun main(){
val handler = CoroutineExceptionHandler{coroutineContext, throwable ->
println("my coroutineExceptionHandler catch exception, msg = ${throwable.message}, suppressed = ${throwable.suppressed.contentToString()}")
}
val parentJob = GlobalScope.launch(handler){
launch {
try {
delay(200)
}finally {
//第二个抛出的异常
throw IndexOutOfBoundsException("exception thrown from first child launch")
}
}.start()
launch {
delay(100)
//第一个抛出的异常
throw NullPointerException("exception thrown from second child launch")
}.start()
}
parentJob.start()
Thread.sleep(1000)
}
输出:
my coroutineExceptionHandler catch exception, msg = exception thrown from second child launch, suppressed = [java.lang.IndexOutOfBoundsException: exception thrown from first child launch]可以看到CoroutineExceptionHandler只处理了第一个子协程抛出的异常,后续异常都放在了第一个抛出异常的suppressed数组中。
还有取消协程时会抛出一个CancellationException,它会被所有CoroutineExceptionHandler省略,但可以try catch它,同时当子协程抛出CancellationException时,并不会终止当前父协程的运行:
fun main(){
val handler = CoroutineExceptionHandler{coroutineContext, throwable ->
println("my coroutineExceptionHandler catch exception, msg = ${throwable.message}")
}
val parentJob = GlobalScope.launch(handler){
val childJob = launch {
try {
delay(Long.MAX_VALUE)
}catch (e: CancellationException){
println("catch cancellationException thrown from child launch")
println("rethrow cancellationException")
throw CancellationException()
}finally {
println("child was canceled")
}
}
//取消子协程
childJob.cancelAndJoin()
println("parent is still running")
}
parentJob.start()
Thread.sleep(1000)
}
输出:
catch cancellationException thrown from child launch
rethrow cancellationException
child was canceled
parent is still running可以看到当抛出CancellationException时,我们可以try catch住它,同时当我们再次抛出它时,协程的CoroutineExceptionHandler并没有处理它,同时父协程不受影响,继续运行。
上面就是CoroutineExceptionHandler处理协程异常时的特点。
CoroutineContext的结构
我们再次看一下CoroutineContext的全家福:

上面讲解了组成CoroutineContext的Element,每一个Element都继承自CoroutineContext,而每一个Element都可以通过 + 号来组合,也可以通过类似map的 [key] 来取值,这和CoroutineContext的运算符重载逻辑和它的结构实现CombinedContext有关,我们先来看一下CoroutineContext类:
public interface CoroutineContext {
//操作符[]重载,可以通过CoroutineContext[Key]这种形式来获取与Key关联的Element
public operator fun get(key: Key): E?
//它是一个聚集函数,提供了从left到right遍历CoroutineContext中每一个Element的能力,并对每一个Element做operation操作
public fun fold(initial: R, operation: (R, Element) -> R): R
//操作符+重载,可以CoroutineContext + CoroutineContext这种形式把两个CoroutineContext合并成一个
public operator fun plus(context: CoroutineContext): CoroutineContext
//返回一个新的CoroutineContext,这个CoroutineContext删除了Key对应的Element
public fun minusKey(key: Key<*>): CoroutineContext
//Key定义,空实现,仅仅做一个标识
public interface Key
//Element定义,每个Element都是一个CoroutineContext
public interface Element : CoroutineContext {
//每个Element都有一个Key实例
public val key: Key<*>
//...
}
} 除了plus方法,CoroutineContext中的其他三个方法都被CombinedContext、Element、EmptyCoroutineContext重写,CombinedContext就是CoroutineContext集合结构的实现,它里面是一个递归定义,Element就是CombinedContext中的元素,而EmptyCoroutineContext就表示一个空的CoroutineContext,它里面是空实现。
1、CombinedContext
我们先看CombinedContext类:
//CombinedContext只包含left和element两个成员:left可能为CombinedContext或Element实例,而element就是Element实例
internal class CombinedContext(
private val left: CoroutineContext,
private val element: Element
) : CoroutineContext, Serializable {
//CombinedContext的get操作的逻辑是:
//1、先看element是否是匹配,如果匹配,那么element就是需要找的元素,返回element,否则说明要找的元素在left中,继续从left开始找,根据left是CombinedContext还是Element转到2或3
//2、如果left又是一个CombinedContext,那么重复1
//3、如果left是Element,那么调用它的get方法返回
override fun get(key: Key): E? {
var cur = this
while (true) {
//1
cur.element[key]?.let { return it }
val next = cur.left
if (next is CombinedContext) {//2
cur = next
} else {//3
return next[key]
}
}
}
//CombinedContext的fold操作的逻辑是:先对left做fold操作,把left做完fold操作的的返回结果和element做operation操作
public override fun fold(initial: R, operation: (R, Element) -> R): R =
operation(left.fold(initial, operation), element)
//CombinedContext的minusKey操作的逻辑是:
//1、先看element是否是匹配,如果匹配,那么element就是需要删除的元素,返回left,否则说明要删除的元素在left中,继续从left中删除对应的元素,根据left是否删除了要删除的元素转到2或3或4
//2、如果left中不存在要删除的元素,那么当前CombinedContext就不存在要删除的元素,直接返回当前CombinedContext实例就行
//3、如果left中存在要删除的元素,删除了这个元素后,left变为了空,那么直接返回当前CombinedContext的element就行
//4、如果left中存在要删除的元素,删除了这个元素后,left不为空,那么组合一个新的CombinedContext返回
public override fun minusKey(key: Key<*>): CoroutineContext {
//1
element[key]?.let { return left }
val newLeft = left.minusKey(key)
return when {
newLeft === left -> this//2
newLeft === EmptyCoroutineContext -> element//3
else -> CombinedContext(newLeft, element)//4
}
}
//...
} 可以发现CombinedContext中的get、fold、minusKey操作都是递归形式的操作,递归的终点就是当这个left是一个Element,我们再看Element类:
public interface Element : CoroutineContext {
public val key: Key<*>
//Element的get方法逻辑:如果key和自己的key匹配,那么自己就是要找的Element,返回自己,否则返回null
public override operator fun get(key: Key): E? =
if (this.key == key) this as E else null
//Element的fold方法逻辑:对传入的initial和自己做operation操作
public override fun fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
//Element的minusKey方法逻辑:如果key和自己的key匹配,那么自己就是要删除的Element,返回EmptyCoroutineContext(表示删除了自己),否则说明自己不需要被删除,返回自己
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
} 现在我们把CombinedContext和Element结合来看,那么CombinedContext的整体结构如下:

有点像是一个链表,left就是指向下一个结点的指针,有了这个图我们再从整体看当调用CombinedContext的get、fold、minusKey操作时的访问顺序:get、minusKey操作大体逻辑都是先访问当前element,不满足,再访问left的element,顺序都是从right到left,而fold的操作大体逻辑是先访问left,直到递归到最后的element,然后再从left到right的返回,从而访问了所有的element。
2、CoroutineContext的plus操作
现在我们来看CoroutineContext唯一没有被重写的方法 - plus方法:
public interface CoroutineContext {
//...
public operator fun plus(context: CoroutineContext): CoroutineContext =
if (context === EmptyCoroutineContext) this else
context.fold(this) { acc, element ->
val removed = acc.minusKey(element.key)
if (removed === EmptyCoroutineContext) element else {
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
}这个方法看起来有点复杂,为了方便我们理解,我把它简化一下,我把对ContinuationInterceptor的处理去掉,如下:
public interface CoroutineContext {
//...
public operator fun plus(context: CoroutineContext): CoroutineContext =
//如果要相加的CoroutineContext为空,那么不做任何处理,直接返回
if (context === EmptyCoroutineContext) this else
//如果要相加的CoroutineContext不为空,那么对它进行fold操作
context.fold(this) { acc, element -> //我们可以把acc理解成+号左边的CoroutineContext,element理解成+号右边的CoroutineContext的某一个element
//首先从左边CoroutineContext中删除右边的这个element
val removed = acc.minusKey(element.key)
//如果removed为空,说明左边CoroutineContext删除了和element相同的元素后为空,那么返回右边的element即可
if (removed === EmptyCoroutineContext) element else {
//如果removed不为空,说明左边CoroutineContext删除了和element相同的元素后还有其他元素,那么构造一个新的CombinedContext返回
return CombinedContext(removed, element)
}
}
}plus方法大部分情况最终下返回一个CombinedContext,即我们把两个CoroutineContext相加后,返回一个CombinedContext,在组合成CombinedContext时,+号右边的CoroutineContext中的元素会覆盖+号左边的CoroutineContext中的含有相同key的元素,如下:
(Dispatchers.Main, "name") + (Dispatchers.IO) = (Dispatchers.IO, "name")
这个覆盖操作就在fold方法的参数operation代码块中完成,通过minusKey方法删除掉重复元素,前面讲过当调用CombinedContext的fold方法时,会从left到right到访问所有的element,即会从left到right的把每一个element传入operation方法中,作为operation方法的第二个参数,而operation方法第一个参数acc的初始值为fold方法传入的initial值,然后它会不断的更新,每次更新的值为上一次调用operation方法的返回值,所以当两个CoroutineContext相加时,puls方法可以理解为下面的伪代码:
val acc = 左边的CoroutineContext
for(var element in 右边的CoroutineContext){
acc = operation(acc, element)//operation操作中会让element覆盖掉acc中与element相同的元素
}
return acc//所以plus方法最终返回的CoroutineContext是不存在key相同的element的所以puls方法最终返回的CoroutineContext是不存在key相同的element的,+号右边的CoroutineContext中的元素会覆盖+号左边的CoroutineContext中的含有相同key的元素,这像是Set的特性。
现在我们再看回简化前的plus方法,它里面有个对ContinuationInterceptor的处理,目的是让ContinuationInterceptor在每次相加后都能变成CoroutineContext中的最后一个元素, ContinuationInterceptor它也是继承自Element,通常叫做协程上下文拦截器,它的主要作用是在协程执行前拦截它,从而在协程执行前做出一些其他的操作,前面我们讲到CoroutineDispatcher它本身也继承自ContinuationInterceptor,ContinuationInterceptor有一个interceptContinuation方法用于返回拦截协程的行为,而这个行为就是前面我们所讲到Dispatchers.Unconfined时的DispatchedContinuation,DispatchedContinuation在恢复协程前根据协程的CoroutineDispatcher类型做出不同的协程分派行为,通过把ContinuationInterceptor放在最后面,协程在查找上下文的element时,总能最快找到拦截器,避免了递归查找,从而让拦截行为前置执行。
结语
本文主要介绍了CoroutineContext的元素组成和结构,理解CoroutineContext对于理解协程使用有很大的帮助,因为协程的启动时就离不开CoroutineContext,同时如果你以后想要更深入的学习协程,例如协程的创建过程,Continuation概念、suspend关键字等,本篇文章也能给你一个抛砖引玉的效果。
以上就是本文的所有内容,希望大家有所收获!
相关学习视频推荐:
【Kotlin进阶教程】——Kotlin协程从实战到原理_哔哩哔哩_bilibili