大数据分析工程师入门11-Hue&Zeppelin

日常数据分析工作中,很多时候都在处理临时性的需求,这种需求要求快速响应和很快得出结果,如果每一个需求都需要写在代码文件中,然后编译打包上传再执行,就会非常浪费时间,尤其是写出来的查询语句频繁出错,需要不断改正再重复打包上传的时候。
所以继上一篇Linux常用命令工具篇讲解完成以后,本文讲解另外两个非常重要的数据分析工作中会使用到的工具:Hue和Zeppelin。
它们都提供了非常方便的数据查询UI界面,能够很方便的进行多次查询并且能够很快地查询出结果。
那么,为什么要将两种工具都跟大家介绍一下呢?
那是因为它们都有着属于自己的特性和优势,小伙伴们需要根据不同使用场景择优选择。考虑到有的小伙伴对这两种工具目前还没有很丰富的使用经验,在本文开头不对它们的异同之处介绍说明,待大家阅读完本文正文,在文章的最后跟大家一起来总结对比一下它们的差别,这样大家理解起来会更容易一些。
(本文分为上下两段,分别由本人撰写Hue部分,同组小伙伴凯凯连撰写Zeppelin部分,所以阅读起来会感觉行文风格和知识输出方式略有差异,先就此提前说明一下。)
Hue
Hue是一个Web应用,设计初衷是简化用户和Hadoop集群间的交互。
大数据的框架很多,通常在解决一个问题的时候,会用到多种框架,这个时候有一个统一的web UI界面去管理各个大数据常用框架是非常方便的。Hue几乎可以支持所有大数据框架,包含有HDFS文件系统的页面(调用HDFSAPI,进行增删改查的操作),有HIVE UI界面(使用HiveServer2,JDBC方式连接,可以在页面上编写HiveQL语句,进行数据分析查询),YARN监控及Oozie工作流任务调度页面等等。
Hue通过把这些大数据技术栈整合在一起,通过统一的Web UI来访问和管理,极大地提高了大数据用户和管理员的工作效率。
日常数据分析工作中,Hue几乎每天都会用到,所以需要熟练掌握Hue的常用功能。
围绕日常数据分析工作中使用HiveQL在Hue上查询数据用到的功能点,写一篇类似使用手册的Hue工具操作指南。
简单来说,就以一个用户第一次进入Hue来进行一个简单的HiveQL查询为例,逐步讲解日常最常使用到的功能点。
通过已经开通了权限的用户名密码登陆Hue,首先进入的主界面如下:
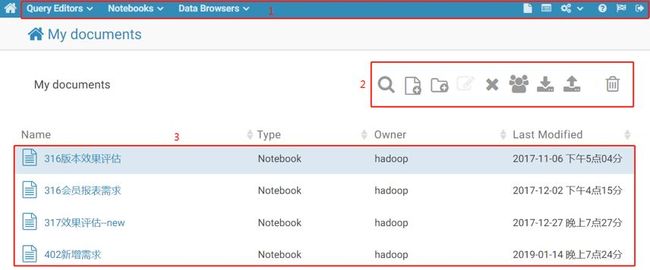
如图展示的三块红框功能区,功能区1后续会在实际使用中结合使用场景介绍,功能区2和3说明如下:
功能区2从左到右依次是搜索文件夹或Notebook、新建Hive Query或Notebook、新建文件夹、重命名文件夹、将选中的文件夹或者Notebook移到回收站、将选中文件夹或Notebook分享给其他用户或用户组、下载选中的文件夹或Notebook(下载下来是个json文件)、上传文件(要求是指定格式的json文件)、进入回收站。功能区3罗列了目前该用户权限下看到的所有文件夹和Notebook,可以点击进入目标文件夹或Notebook页面。
主界面简单介绍完以后,下一步就是如何进入库表查看和HiveQL编辑界面了,入口在功能区1,共有两种进入方式。
第一种:点击Query Editors出现下拉框

点击Hive,进入页面如下
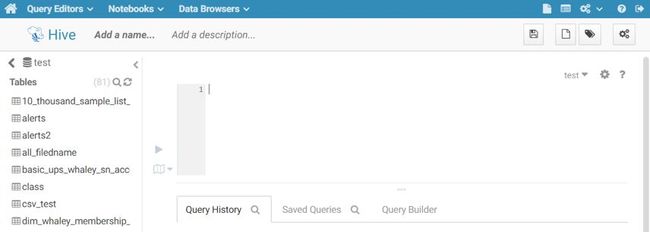
第二种:点击Notebooks

新建一个Notebook(红框1)或者进入自己已建的Notebook(红框2),如选择新建Notebook,进入页面如下:
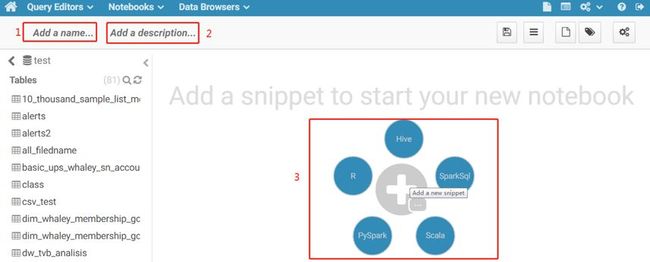
标记1处是给该Notebook命名,标记2是该Notebook的详细说明,标记3处可选择某种语言进入代码编辑页面,如选择Hive编写HiveQL。
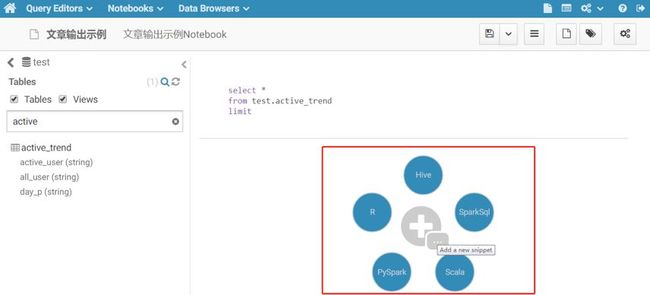
这两种方式的区别是:
后者建Notebook可以将一次完整需求的所有查询语句归整保存,便于复用。下次只要在上文所讲的主界面通过搜索该Notebook或上文所讲能够进入HiveQL编辑界面的第二个入口处,点击菜单栏Notebooks弹出下拉框后,下滑滚动找到该Notebook,点击进入,就可以再次查看这次所写的查询语句,进行复用或回顾,并且可以将该Notebook分享给他人使用。
在数据分析日常工作中,有时候需要提供给业务方某个需求的多个查询语句,以供他们需要时使用,这时候就可以建一个Notebook,帮业务方把查询语句依次写好保存,然后将Notebook分享给业务方即可。HiveQL编辑界面中点击上图中的+号可以依次添加新的查询编辑区,且新添加的查询编辑区可重新选择执行语言。
通过上面的讲解,现在我们已经可以着手进行数据查询了,首先进入上文所建的Notebook(文章输出示例Notebook)。
1.2.1 搜索目标表
假设现在需要统计的信息在test库中,且只记得表名包含active字段,直接搜索关键字即可,搜索支持模糊匹配。

1.2.2 查看字段信息
如果想要知道目标表中有哪些字段,每个字段的含义和数据类型是什么,只需点击一下查找到的目标表就可以看到字段名和字段类型,将鼠标悬停在想要查看的字段上,就可以看到字段注释。

1.2.3 查看样本值
如果想要知道表里面的字段值大概是什么样子的,有两种方式,第一种可以写HiveQL limit 几条出来看看结果。

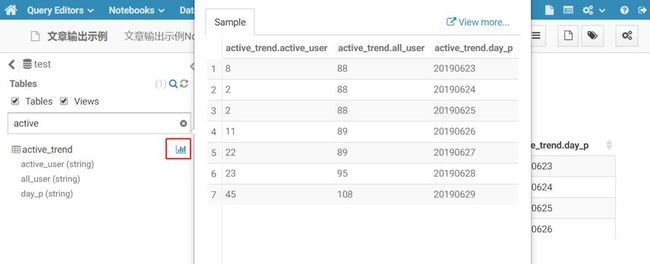
另一种可以不用写查询语句那么麻烦,通过点击上图目标表或者每个字段右侧的像柱状图一样的那个图标,就会弹出样本值浮框。
1.2.4 查看分区字段
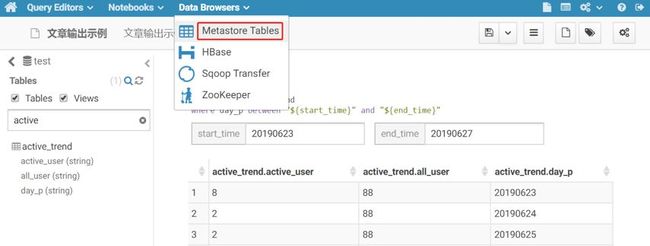
之前系列课程Hive基础中有提到过,进行表数据查询时,尤其是一张数据量非常庞大的表的时候,一定要记得加上分区字段进行条件限制,否则极可能因查询数据量过大而造成集群崩溃。想要查看目标表的分区字段是哪些,方式有两种,除了通过show create table 语句查看,还有一种方式如下,点击DataBrowsers 下的Metastore Tables:
进入test库的详情页,如下:

点击目标表红框处的向右箭头,进入该表的详情页,该页面可以看到表的基本信息、表的字段信息、分区信息、样本数据等。
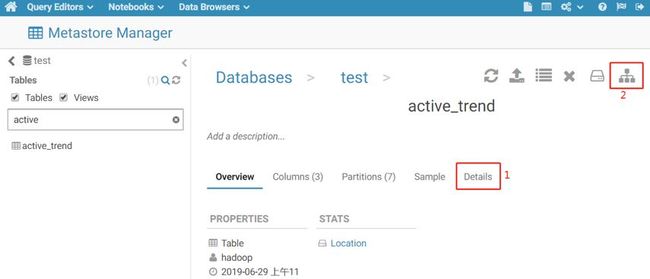
点击标记1处,查看分区字段信息如下:

点击标记2处,可查看目前的分区字段信息(比如日期信息)所有值的情况(至于页面上其他功能按钮,小伙伴们可以自己实践操作查看了解一下)。

点击标记1处可删除所选中分区,点击标记2处可跳转到HDFS查看具体HDFS路径。
字段、字段值、分区都明确了以后,可以写第一个HiveQL了,以需要查询某段时间目标表中每天所有明细数据为例。
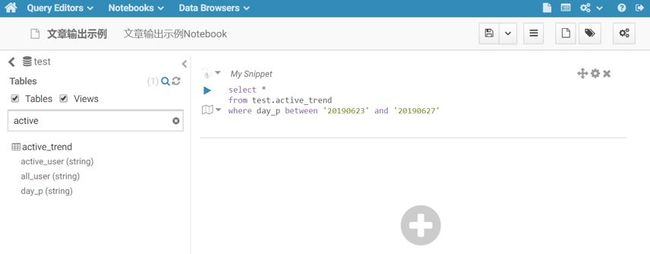
1.3.1 传参
如果这个需求需要不定时查询,那么day_p的时间区间可以采用参数的方式传入,使用者只需要在传参输入框输入想要查询的日期即可,start_time和end_time字段可依据实际需要命名为别的名称。要点是,在SQL中使用类似${argName}的形式,下面就会多一个输入框。

1.3.2 切换语言环境
目前编辑框的语言环境是HiveQL,如何想用SparkSql或者执行别的语言,可进行切换,切换语言环境的同时也会切换执行引擎。操作见下图,点击标记处就可以进行选择啦:

1.3.3 语句格式化&执行
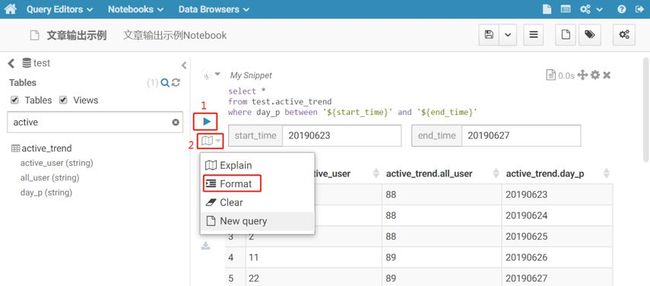
如果所编写的HiveQL包含了很多层关联或嵌套,整个语句结构不清晰,查看起来很不方便,那么可以使用Hue的Format功能,使整个语句的结构进行标准格式化。点击下图标记2处,下拉框中选择Format,即可将语句结构格式化。
标记1处是语句执行按钮,点击即开始执行。如果查询数据量非常大,已经查询了很长一段时间或者突然发现查询语句有问题,想要终止查询,那么同样可点击标记1处进行终止。
Format下方还有一个Clear选项,该选项可以将当前编辑框中的查询语句和查询结果清空。
1.3.4 查看查询结果
接下来将教大家在查询结果数据字段非常多的情况下如何选择性的筛选查看部分数据。
1.3.4.1 查看所有结果字段及其类型
点击下图标记处。

弹出如下标记处的查询结果字段值和字段类型信息。

1.3.4.2 搜索查询结果指定字段
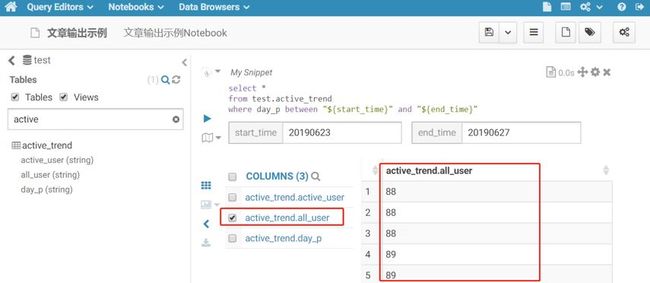
查询出来的结果字段非常多的情况下,可使用搜索功能,如查找all_user字段。

1.3.4.3 选择显示部分查询结果字段
如果只想显示部分字段查看其结果值,可针对复选框进行选择性勾选。
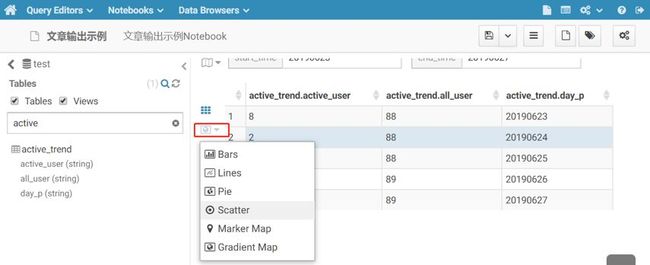
1.3.5 查询结果可视化
Hue上可对查询结果进行简单的可视化,点击下图标记处弹出的下拉选项中可选择性的进行不同类型可视化,读者可自行实践操作下,这里就不一一操作展示效果啦。
1.3.6 查询结果下载
通常情况下,在Hue上直接进行可视化操作不会太多,一般会将整个查询结果下载下来在Excel里进行结果的初步分析和查看工作。下载按钮如下图标记处,下拉框中提供不同的下载选项。需要注意的是,如果查询的是数据量非常庞大的明细数据,很可能出现结果不能完全下载下来的情况,因此建议结果数据超过1000条时,优先下载csv格式。

1.3.7 命名查询主题
可以给每一条查询语句命名,以便提高辨识度,方便日后查阅。
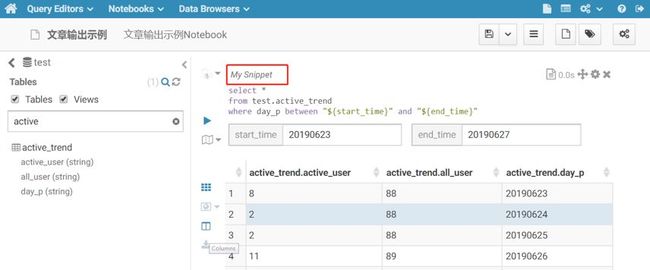
如命名以上查询语句为“查询一段时间内的明细数据”,记住命名完成以后,点击下图标记1处的保存按钮进行保存,最好养成时时保存的习惯,以免意外情况发生导致页面重新刷新,所有操作信息丢失,又得重新开始的情况。

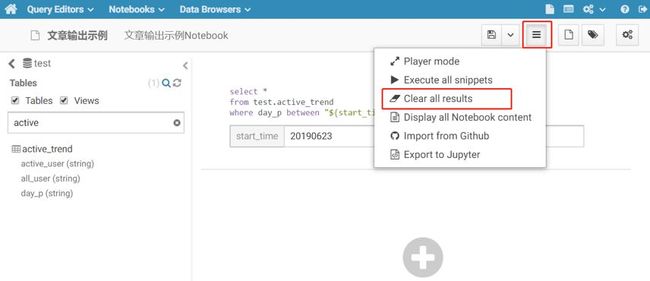
1.3.8 清空Notebook里的所有查询结果
整个Notebook页面查询结果展示过多的话,有可能出现每次进入该Notebook页面需要刷新很久的情况,如无必要,可将所有查询结果清空。
1.3.10 其他
Hue还有很多其他功能点,感兴趣的小伙伴可基于本文所介绍之基础自行查看了解,作为入门课程,这里就不继续深入介绍了,比如HDFS相关信息查看页面(通过标记1处进入)和Job信息查看页面(通过标记2处进入)等。

Zeppelin
zeppelin是一个非常流行的开源数据探索分析平台。zeppelin集成了非常多的数据处理和分析相关的组件,其核心组织概念是notebook,所有的操作都可以在notebook中完成,官网的原话是“The Notebook is the place for all yourneeds”。
它主要拥有以下优秀的功能特性:
1)非常易用的操作界面,界面上提供了非常好用的各式工具,帮助你完成各种数据处理操作。
2)支持多种编程语言,zeppelin通过interpreter实现了将多种语言和数据处理框架以插件的形式集成进来。官方默认集成了spark组件,几乎是开箱即用的,非常方便。
3)有着强大的数据可视化组件,除了支持基础图形(折线图、柱状图、饼图等)外,zeppelin还支持数据透视功能,而且是通过拖拽就可以完成可视化操作,非常强大。
4)支持动态表单,允许在你的SQL语句或者代码中嵌入变量,在执行前输入不同的参数值给变量赋值。
5)支持将zeppelin页面或段落嵌入到其他网页中,并能够实时更新数据。
那么对于大数据分析师来说,zeppelin能够帮我们做什么呢?
首先,zeppelin支持运行sparksql,我们可以在zeppelin上运行我们编写的SQL语句,通过比对运行后的结果,验证我们的SQL是否编写正确;
其次,zeppelin支持运行scala代码,那我们可以利用它来试探性地使用spark的相关api,或者在zeppelin上编写并运行spark的udf,避免反复打包上传,提高开发效率;
然后,zeppelin拥有非常强大的可视化功能,我们可以对数据进行探索分析,通过可视化直观地发现问题,快速验证构想,并深入地分析和挖掘数据价值。
最后,zeppelin的运行结果可以非常方便的导出,可以使用它来完成临时需求,提供数据结果给业务方。并且可以把相关代码或SQL保存起来,下次如有相似需求,直接修改下相关条件运行下就可以了。
官网上有非常详细的zeppelin安装步骤,大家可以依照文档来完成安装和配置,这里就不占用篇幅来讲了。在大致了解了zeppelin之后,我们来看下它的核心概念和具体的使用方法。
2.2.1 Interpreter
Interpreter是zeppelin最核心的概念,zeppelin允许任何语言和数据处理框架以interpreter的方式集成进来,这构建了zeppelin强大功能的基础。
zeppelin提供了大量的各种语言和框架的可以直接使用的interpreter,在安装zeppelin时可以选择安装包含所有interpreter的安装包,或者在安装后通过./bin/install-interpreter.sh脚本安装指定名称的interpreter。另外,你也可以参照官网上的文档,编写自己的interpreter,扩展zeppelin的功能。
在使用interpreter之前需要进行一些设定,如对于spark interpreter来说,需要设置spark的安装目录、提交作业的地址、driver和excutor的内存等信息。具体如何设置,在官网文档中都有给出详细说明。
在使用具体的interpreter时,只需要在代码的首行添加%加上具体的interpreter名称即可(首行不能有其他内容)。如使用spark时,在首行添加%spark,使用sparksql时,在首行添加%sql即可,使用pyspark,在首行添加%pyspark。如果设置了默认使用spark,则可以省略不写。
2.2.2 Note&Paragraph
Note页面是zeppelin使用频率最高的页面,这个页面是用户的主要操作界面,它有非常多的功能,我们在下一章节页面介绍时会详细介绍。note页面包含多个paragraph,每个paragraph内可以写代码。上面我们提到的interpreter标识就是写在paragraph的首行的,每个paragraph内只能使用一种interpreter,但是不同的paragraph可以使用不同的interpreter,即一个note内可以同时存在多个使用不同interpreter的paragraph。
zeppelin是以paragraph为最小运行单位的。对于spark interpreter来说,同一个用户同一时间,只能有一个paragraph处于运行状态(running),如果这时运行了其他的写了spark代码的paragraph,那么它将处于等待状态(pending),直到第一个paragraph运行结束后,它才会开始运行。当然,运行状态是可以被中断的。
2.2.3 Dynamic forms
动态表单(dynamic form)是zeppelin提供的一项非常实用的功能,允许你在代码或者SQL中使用变量,在运行前通过手动输入变量值,然后运行时动态替换代码或者SQL中的变量,避免了反复修改代码或SQL的麻烦。具体示例如下:

如果只有图中条件的值发生变化时,只需要在下方的输入框中输入新的值,直接运行就可以了,非常的方便。只要你在代码或SQL中使用类似${argName}的形式,那么就会被识别为动态表单,如果下方没有出现输入框,可以先运行一下,输入框就会出现了。
动态表单还有其他一些用法,更多详细信息可以查阅官方文档(https://zeppelin.apache.org/docs/0.8.1/usage/dynamic_form/intro.html)。
zeppelin的功能是很强大的,因此页面也比较多,这里我们只介绍最常用的几个页面。
2.3.1 主页
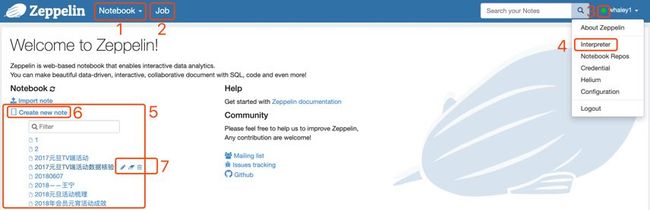
顶部导航栏上标记1的位置,点击后会展开现有note的列表,与标记5区域展示的内容一致,主要作用是为了方便你处在某个note页面中时,可以不用回到首页而方便地切换到其他note。
点击标记2的位置,会跳转到job页面,这个页面你可以查看note各paragraph的最后一次运行状态,并可通过点击图标跳转到指定的note中的paragraph位置,我们通常可以利用这个页面查看定时调度任务的执行状态。
标记3位置展示的是与ZeppelinServer的连接状态,绿色表示正常,当连接出现异常时,这里会变成红色。点击标记4的位置,可以跳转到interpreter的配置页面,我们在2.3.4小节会再详细讲。
点击标记6位置的按钮可以创建一个全新的note,这个按钮在上述提到的标记1展开的列表中也有。当你把鼠标悬停在标记5区域的某个note名字上时,后面会出现三个小按钮,如标记7位置所示,分别对应重命名、清空输出和移到回收站操作。
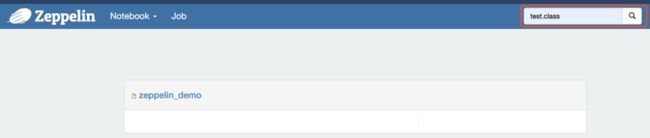
在标记3的左边有个搜索框,这里可以进行全局搜索,例如你只记得代码中的某个片段,但是不记得具体写在哪个note中,就可以通过这里搜索出对应的note,点击note的名称便可以直接跳转进去。如下所示:
2.3.2 note页

顶部导航栏和首页的导航栏作用完全相同,这里就不再重复讲了。标记1的位置展示的是note的名字,建议大家要起一个辨识度比较高的名字,不要太随意,不然后续查找代码时非常费劲。标记1右侧为工具栏,我们来逐个介绍下。标记2区域中的按钮是针对所有paragraph生效的,从左至右依次为,运行所有paragraph、显示或隐藏代码、显示或隐藏输出结果、清空所有输出结果、克隆当前note页、导出当前note页、切换为私有模式。标记3区域提供了版本控制功能。标记4区域内按钮,分别是将当前note移动到回收站和对当前note做定时调度。标记5区域的功能依次为,展示快捷键、interpreter绑定、note权限管理和主题模式选择。
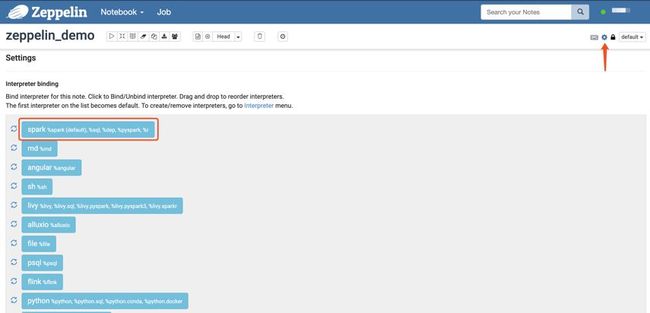
这里我们简单讲下interpreter绑定界面,点击下图中箭头位置可以打开绑定界面。界面中展示的是所有你安装的interpreter组,蓝色表示在本note中可以使用,点击蓝色方框后会变成白色,表示和当前note解绑,在当前note中不可使用。另外,可以通过拖拽改变他们的顺序,处于最顶上的那个方框里的第一个解释器就是默认解释器,当你在paragraph中不指定解释器时,就会使用这个默认解释器。点击方框前面的刷新按钮,会重启对应的interpreter。
在note页面的下方所有区域为paragraph区,我们在下一小节单独来讲下。
2.3.3 paragraph
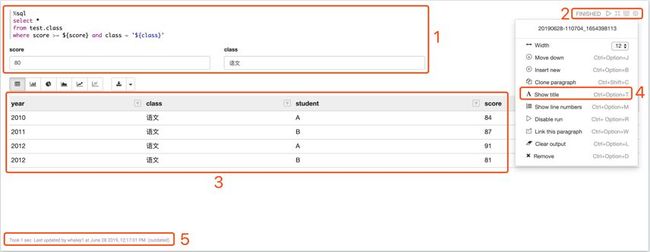
标记1区域为代码编辑区,你在paragraph的代码编辑区中的所有编辑操作都是自动保存的,而且zeppelin还提供了针对不同语言的语法高亮,非常的好用。标记2为命令区,从左只有依次为运行按钮、隐藏编辑区、隐藏输出、设置。点击运行按钮后,编辑区的代码会被运行,在运行结束前,如果再点击一次,则会中止代码的运行。点击设置按钮后会弹出下面展示的设置选项界面,这里重点关注下标记4选项,可以展示title,这样我们就可以给我们的每个paragraph起一个名字或写一句描述,提高辨识度。标记5的区域展示的是上次运行花费的时间,以及代码的最后更新时间等信息。
标记3的区域为结果展示区,在红框上面的一排按钮为可视化操作相关的按钮,大家可以尝试地去用一下,用zeppelin可以完成常用基本图形的可视化。如果你的代码有报错,错误信息也会在这个区域展示。
paragraph是我们工作的核心区域,它的功能简洁而强大,新增paragraph也是非常方便的,你可以点击任意paragraph的顶部或底部间隙来插入一个新的paragraph,如下图所示:

标记6位置即新增一个paragraph的按钮,默认是隐藏的,鼠标悬停在这里就会显示。标记7位置演示了展示错误信息的功能。
2.3.4 interpreter页
通过2.3.1小节中讲到的点击标记4的位置,可以跳转到interpreter页,当然啦,前提是你有这个页面的访问权限,具体页面的形式如下所示。

标记1区域为功能按钮,从左到右依次为跳到SparkUI界面、编辑spark interpreter的相关属性、重启spark interpreter(该动作同时会重启Spark client端,即SparkSubmit进程)、移除spark interpreter。标记2区域为设置spark interpreter实例化SparkSubmit进程的方式,图中设置结果的含义为每个用户都拥有独立的SparkSubmit进程,他们是互相隔离的。标记3区域的作用为设置spark的相关属性,如master地址、driver和executor内存等,修改设置后需要重启spark interpreter才能生效。
Hue&Zeppelin异同点
通过正文对Hue和Zeppelin的使用说明,相信大家对它们已经有了一定的了解,如开篇跟大家说的,它们都是很好的能够快速响应临时需求和很快得到查询结果的Web UI工具。
那么,它们有什么异同点呢?分以下几个方面跟大家总结一下。
(1)Zeppelin和Hue都能提供一定的数据查询和可视化的功能,都提供了多种图形化数据表示形式。
(2)Zeppelin支持的后端数据查询程序较多。
(3)Zeppelin只提供了单一的数据处理功能,包括上文提到的数据提取、数据发现、数据分析、数据可视化等都属于数据处理的范畴。而Hue的功能相对丰富的多,除了类似的数据处理,还有元数据管理、Oozie工作流管理、作业管理、用户管理、Sqoop集成等很多管理功能。从这点看,Zeppelin只是一个数据处理工具,而Hue更像是一个综合管理工具。
(1)Zeppelin采用插件式的解释器,通过插件开发,可以添加任何后端语言和数据处理程序。相对来说更独立和开放。
(2)Hue与Hadoop生态圈的其它组件密切相关,一般都与CDH(Cloudera发行版(Cloudera’s DistributionIncluding Apache Hadoop,简称 CDH ))一同部署。
(1)Zeppelin适合单一数据处理、但后端处理语言繁多的场景,尤其适合Spark。
(2)Hue适合与Hadoop集群的多个组件交互、如Oozie工作流、Sqoop等联合处理数据的场景,尤其适合与Impala协同工作。
小结
本文主要给大家介绍了两种日常数据分析工作中用来快速处理临时需求的Web UI工具-Hue&Zeppelin。
希望阅读完本文的小伙伴对于这两个工具的使用能够快速上手哦。
-end-
参考文献:
[1]《基于hadoop生态圈的数据仓库实践 —— OLAP与数据可视化》
作者 wzy0623
https://blog.csdn.net/wzy0623/article/details/52370045
[2] zeppelin官网,http://zeppelin.apache.org
