本文大致介绍下SDTM数据提交的标准格式,包括数据集水平和变量水平的两种属性。
· 正 · 文 · 来· 啦·
Standard Metadata for Dataset Contents and Attributes
SDTMIG提供了常见数据domain的metadata属性,在SDTM Specification和Define.xml中均有其详细描述,它一般包括以下方面:
标准的变量名,所有提交的变量名必须标准化,即便是申办方内部数据库里的其他变量名,我们也要尽可能用一些conventional rule来命名。
标准变量标签
数据类型,是数字型的还是字符型的,与SAS格式相对应
实际的控制术语和格式
数据的来源
数据集中的变量role
方便reviewer理解变量或数据的comments
◆ ◆ ◆◆ ◆
除了以上这些,CDISC domain model还提供其他3种隐性信息,方便sponsor呈现他们的数据:
CDISC Notes,对变量解释说明,描述变量的来源、用法、意义等相关信息。当我们搞不清这个变量是干嘛用的,仔细研读这里面的内容,或许有所收获
Core,变量compliance评估,说明此变量是可有可无的,还是必须要有的
References,说明有无引用关系

Regulatory Submissions —Dataset Metadata
大部分study都会包括DM和一些安全性的domain(如EX, CM, AE, DS, MH, IE, LB, and VS)。具体提交哪些数据要看方案和机构要求。
数据集定义的metadata应该包括dataset filenames, descriptions, locations, structures, class, purpose, keys, and comments。
在试验设计之初考虑到可能有合并用药,但到最后数据锁定之后,仍然没有受试者有CM记录,此时CM是空集,我们不用提交,也不用在define.xml中描述。在annotated CRF正常注释,不需要说明no records。
◆ ◆ ◆◆ ◆
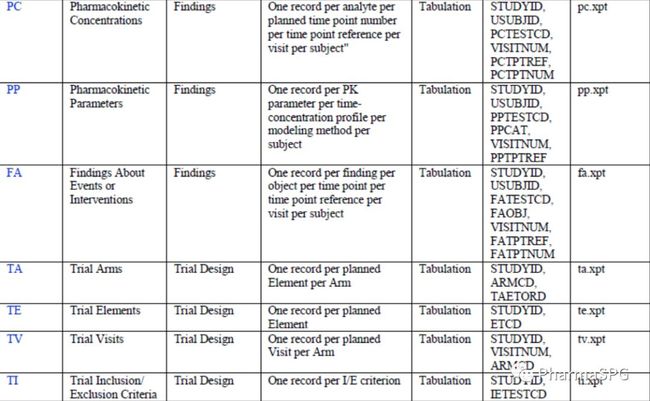
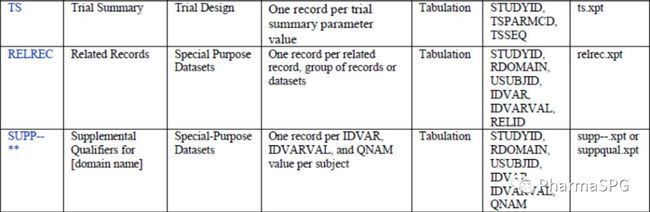
下表给出SDTM Submission Dataset-Definition Metadata例子,数据集水平的Metadata属性,描述了数据集的整体情况。此表异常重要,它基本是一个标准和参考。




◆ ◆ ◆◆ ◆
Primary Keys用于帮助reviewers理解数据集的结构,这些Keys应该确保,在同一个数据集中观测的唯一性;同时,它可能用于数据集排序,计算--SEQ变量。
我们以EX domain为例来简单说明下。
EX数据集的label是Exposure;Class为Interventions;结构是One record perconstant dosing interval per subject;Purpose为Tabulation(SDTM都是Tabulation,用于数据呈现,如同ADaM都是Analysis,用于分析);Location指define.xml中相应的xpt文件;常见的Keys是"STUDYID USUBJID EXTRT EXSTDTC"。也就是说,在EX数据集中,不存在两条及以上观测这4个变量的值完全一样,它是可以确定观测的唯一性的,同时基于这个顺序,我们再计算EXSEQ。如果有duplicate records,那有可能是data issue,或者是map出现错误。这里的Keys是SDTMIG给出的常见例子,Sponosr应该基于实际情形定义Keys,比如可能加入EXCAT,EXLOC等等信息,关键是做到“唯一”。
◆ ◆ ◆◆ ◆
注意到SE Keys为"STUDYID USUBJID ETCD SESTDTC",但我们一般算SESEQ时,更多的是基于"TUDYID USUBJID SESTDTC ETCD"这个顺序,这样可以更清晰地知道element的经历情况,而不是将ETCD放在前面按字符排序。这里Keys和排序不矛盾,并不一定非得按Keys试算sequence number。
RELREC中的排序较为复杂,基于study而变化,这里不展开讨论。**SUPP的keys是"STUDYID RDOMAIN USUBJID IDVAR IDVARVAL QNAM",但考虑到IDVARVAL是个字符值,如果IDVAR=--SEQ,按这个顺序,则会出现"11"排在"2"的前面。所以,我们在最后排序的时候加--SEQ,这样与parent domain的顺序看起来是相对应的,方便reviewer查看。
◆ ◆ ◆◆ ◆
natural key是数据的一部分,可能有多个变量,区别于数据中的其他行。这是本身就存在的,像CM中Keys "STUDYID USUBJID CMTRT CMSTDTC"。有时考虑到商业需要,会加入位置或方位变量。
surrogate key是独立部分,人为计算加以区分的,是一种derived data。--SEQ便是一个例子。有的时候,--SEQ也可作为natural keys的替换。

CDISC Submission Value-Level Metadata
Value-Level Metadata,讲的是数据集里面的变量属性,是一种相对数据集而言,更微观的数据属性。
比如VS包括收缩压,舒张压,身高,体重,身体质量指数BMI。我们知道,VS的结构是一条观测一次测试,这样,同一个人在某个时间点就有5条观测,parameter names存储Code/Name variables,parameter values存储结果,分别由5条不同的记录表示。为了加以区分,这5条Test Code/Names必有不同的属性。
CDISC V3.x Findings是一种标准的垂直的数据结构,一条记录,一条观测。因为要将多种不同类型的观测以同一种结构呈现,有必要有另外的metadata来描述可能的不同。故而需要value-level metadata,它存放于一个单独的文件Report Tabulation Data Definition Specification(Define-XML)。在SDTM编程过程中,经常会碰到数据结构从横向往纵向的转换。

Conformance表示数据集要符合一定的标准,至少要满足以下条件:
有完整的数据结构
符合SDTMIG model
使用SDTM-specified标准的domain名字,前缀,变量名,标签,变量类型,控制术语
包括所有Required and Expected变量,保证所有的Required变量有值。
有适合的Identifier and, Timing variables,Topic variable
是否符合CDISC Notes描述的business rules和domain-specific假设
我们不用将数据集一一做这种排查,已经有像OpenCDISC之类的工具来帮我们做validation,而这一步不仅仅是完善SDTM数据集,同时也包括其他submission package的更新和发展过程。