分布式系统中有个著名的原则CAP原则,C为Consistency(一致性)、A为Availability(可用性)、P为Partition tolerance(分区容错性)。这里主要介绍下分布式环境下如果达到一致性。
说到一致性不得不说下经典的拜占庭问题。
拜占庭问题
话说一组拜占庭将军分别各率领一支军队共同围困一座城市。为了简化问题,将各支军队的行动策略限定为进攻或撤离两种。因为部分军队进攻部分军队撤离可能会造成灾难性后果,因此各位将军必须通过投票来达成一致策略,即所有军队一起进攻或所有军队一起撤离。因为各位将军分处城市不同方向,他们只能通过信使互相联系。在投票过程中每位将军都将自己投票给进攻还是撤退的信息通过信使分别通知其他所有将军,这样一来每位将军根据自己的投票和其他所有将军送来的信息就可以知道共同的投票结果而决定行动策略。
系统的问题在于,将军中可能出现叛徒,他们不仅可能向较为糟糕的策略投票,还可能选择性地发送投票信息。假设有9位将军投票,其中1名叛徒。8名忠诚的将军中出现了4人投进攻,4人投撤离的情况。这时候叛徒可能故意给4名投进攻的将领送信表示投票进攻,而给4名投撤离的将领送信表示投撤离。这样一来在4名投进攻的将领看来,投票结果是5人投进攻,从而发起进攻;而在4名投撤离的将军看来则是5人投撤离。这样各支军队的一致协同就遭到了破坏。
拜占庭问题其实是指在一个可妥协的通信网络中实现分布式协议的问题,也就是在不可靠的环境中建立一个可靠的系统的问题。
假始那些忠诚(或是没有出错)的将军仍然能通过多数决策来决定他们的战略,便称达到了拜占庭容错。
PBFT
PBFT是Practical Byzantine Fault Tolerance的缩写,意为实用拜占庭容错算法,复杂度过高O(N^2)。PBFT是一种状态机副本复制算法,即服务作为状态机进行建模,状态机在分布式系统的不同节点进行副本复制。每个状态机的副本都保存了服务的状态,同时也实现了服务的操作。
PBFT是一个三阶段算法,分为Pre-Prepare、Prepare和Commit。
PBFT中有几个概念需要了解下,所有的节点称为副本,这些副本有两个角色,分别为主节点(primary)和备份节点(backups),所有的副本在一个被称为视图(View)的轮换过程中运作。主节点和备份节点是针对视图而言,视图是连续编号的整数。在某个视图中,从副本中选出一个副本为主节点,选择算法为p = v mod |R|,其中v是视图编号,|R|为副本个数,p为副本编号,除主节点之外所有的节点都为备份节点。当主节点失效的时候就需要启动视图更换过程。
知道上述概念之后,来看下算法的具体流程:
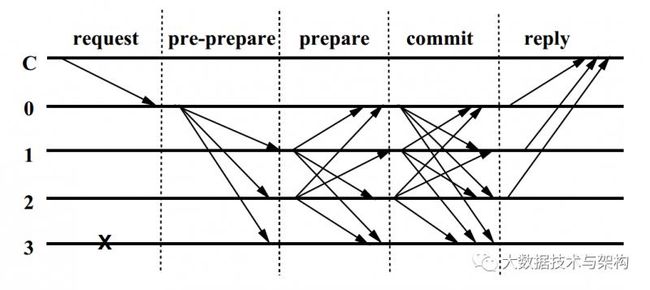
其中0为主节点,123为备份节点,3宕机无法响应请求
主节点0接收到客户端C发来的请求request,给请求分配一个序列号n,然后向所有备份节点群发预准备消息,预准备消息的格式为<
备份节点收到主节点广播的消息之后,check下自己是否接受,接受之后向其它副本进行prepare广播
某个副本在接收到2f个prepare信息之后,向其它副本广播commit
某个副本在接收到2f+1个commit信息之后,向客户端C发送reply
客户端C在接收到f+1个相同的reply之后则达成共识
拜占庭问题是一个理论性的模型,解决起来比较困难,工程实践上可以将其模型的某些条件进行假设,这样可以解决一些特定的问题。
将集群中是否存在背叛者作为一个已知条件来将拜占庭问题细分下:
假如集群中存在背叛者,也就是有一些伪造信息,这种情况称为拜占庭错误,伪造信息的节点称为拜占庭节点。其一致性算法为BFT(Byzantine Fault Tolerance),上文介绍的PBFT就是一个拜占庭容错算法。
如果集群中不存在背叛者,都是忠诚者,只是这些忠诚者由于某种原因无法正常工作,这种情况称为非拜占庭错误。其一致性算法为CFT(Crash Fault Tolerance)。
下面我们就介绍两个非拜占庭一致性算法Paxos和Raft。
Paxos
Paxos算法为非拜占庭一致性算法,运行在允许宕机故障的异步系统中,不要求可靠的消息传递,可容忍消息丢失、延迟、乱序以及重复。它利用大多数机制保证了2F+1的容错能力,即2F+1个节点的系统最多允许F个节点同时出现故障。
Paxos算法中的角色分为Proposer和Acceptor,Proposer是提案者,用来发起提案(Proposal),Acceptor是决策者,用来接收和响应Proposer提出的提案。这个算法的场景是一个或多个提议进程(Proposer)可以发起提案(Proposal),需要在所有提案中选取某一个提案,使其在所有进程中达成一致。系统中的多数派同时认可该提案,即达成了一致。最多只针对一个确定的提案达成一致。
Paxos算法流程分为两阶段,第一阶段为Prepare阶段,第二阶段为Commit阶段。两阶段提交算法的思路大致可以概括为决策者将提案的结果通知提案者,再由提案者根据所有决策者反馈的结果决定是提交操作还是终止操作。
Paxos算法大致流程为Proposer询问Acceptors是否可以发起提案,Acceptors将结果返回给Proposer(第一阶段),再由Proposer根据Acceptors反馈的结果决定提案内容以及提案是提交还是终止(第二阶段)。具体流程如下:
第一阶段Prepare阶段:
Proposer提出一个提案时,每次提案时都生成一个全局唯一且递增的ID,向Acceptors发送PrepareRequest请求,PrepareRequest请求只携带提案ID,而无需携带提案内容。
Acceptors收到Proposer的请求后,判断PrepareRequest中的ID是否大于Acceptors记录的值,如果大于则检查下是否有已经Accept过的提案,有则返回提案中ID最大的那个提案的value和ID,没有则返回空值,如果小于Acceptors记录的值则不响应。
第一阶段结束,开始第二阶段Commit阶段:
Proposer接收到多数Acceptors的PrepareResponse应答之后,从应答中选择提案ID最大对应的value作为本次要发起的提案。 如果所有应答的提案value均为空值,则可以自己随意决定提案value。然后携带当前ID,向所有Acceptors发送AccpetRequest请求。
Accpetors收到AccpetRequest后,判断AccpetRequest中的ID是否大于等于Acceptors记录的值,是则持久化当前ID和提案内容,然后返回给Proposer响应AcceptResponse
Proposer收到多数Acceptors的AcceptResponse后,决议形成。
整个流程中Acceptors的行为可以概括为两个承诺,一个应答。
两个承诺:
不再应答PrepareRequest中ID小于等于当前请求PrepareRequest中ID的请求(是因为当前PrepareRequest中ID已经赋值给minProposal)
不再应答AcceptRequest中ID小于当前请求AcceptRequest中ID的请求(因为当前AcceptRequest中ID是上次PrepareRequest请求中ID,所以不再应答小于的ID)
一个应答:
不违背之前作出的承诺下,返回自己已经Accept过的提案中ID最大的那个提案的内容,如果没有则返回空值
结合下面的伪代码能够更加深刻理解这两个承诺一个应答的含义

算法逻辑为:
获取一个ProposalID n,为了保证ProposalID唯一,可采用时间戳+ServerID生成;
Proposer向所有Acceptors广播Prepare(n)请求;
Acceptor比较n和minProposal,如果n>minProposal,则minProposal=n,并且将acceptedProposal和acceptedValue返回;
Proposer接收到过半数回复后,如果发现有acceptedValue返回,将所有回复中acceptedProposal最大的acceptedValue作为本次提案的value,否则可以任意决定本次提案的value;
到这里可以进入第二阶段,广播Accept(n,value) 到所有节点;
Acceptor比较n和minProposal,如果n>=minProposal,则acceptedProposal=minProposal=n,acceptedValue=value,本地持久化后,返回;否则,返回minProposal。
提议者接收到过半数请求后,如果发现有返回值result>n,表示有更新的提议,跳转到1;否则value达成一致。
原始的Paxos算法(Basic Paxos)只能对一个值形成决议,决议的形成至少需要两次网络来回,在高并发情况下可能需要更多的网络来回,极端情况下甚至可能形成活锁(活锁–多个Proposer交替向Acceptors提交PrepareRequest请求,在发送AccpetRequest请求时,都因为ID发生更新,Acceptors无法接受AccpetRequest请求,返回ID,是Proposer再次向Acceptors发送PrepareRequest请求,如此反复,无法形成共识。)。更重要的是如果想连续确定多个值,Basic Paxos无法确定了。因此Basic Paxos几乎只是用来做理论研究,并不直接应用在实际工程中。
实际应用中几乎都需要连续确定多个值,而且希望能有更高的效率。Multi-Paxos正是为解决此问题而提出。Multi-Paxos基于Basic Paxos做了两点改进:
针对每一个要确定的值,运行一次Paxos算法实例(Instance),形成决议。每一个Paxos实例使用唯一的Instance ID标识。
在所有Proposers中选举一个Leader,由Leader唯一的提交提案给Acceptors进行表决。仅有一个Leader进行value提交的情况下,Prepare阶段就可以跳过,从而将两阶段变为一阶段,提高效率。同时这样没有Proposer竞争,也解决了活锁问题。
Paxos确实很强大,而且也可以应用于实际工程中,但是其理论真的很难理解,于是Raft算法出现了,以简单著称,并在工业上也得到了广泛的使用。
Raft
Raft也是两阶段提交算法,类似于Multi-Paxos。算法中的角色分为Leader、Follower和Candidate,但是这三种角色并不是同时出现的,正常运行时只有Leader和Follower,candidate只作为选举leader时的一个临时角色出现。
Leader: 接受客户端请求,并向Follower同步请求日志,当日志同步到大多数节点上后告诉Follower提交日志。
Follower: 接受并持久化Leader同步的日志,在Leader告之日志可以提交之后,提交日志。
Candidate: Leader选举过程中的临时角色。
系统在初始化时,同为Follower,在election timeout之后(各节点在150-300ms之间随机),由Follower转化为Candidate进行选举Leader
Raft算法主要用于管理多副本状态机的日志复制,并且其将一致性分解为多个子问题:Leader选举(Leader election)、日志同步(Log replication)、安全性(Safety)、日志压缩(Log compaction)、成员变更(Membership change)等。同时,Raft算法使用了更强的假设来减少了需要考虑的状态,使之变的易于理解和实现。Raft算法支持最大的容错故障节点是F,集群总数为2F+1。
关注我的公众号,后台回复【JAVAPDF】获取200页面试题!
5万人关注的大数据成神之路,不来了解一下吗?
5万人关注的大数据成神之路,真的不来了解一下吗?
5万人关注的大数据成神之路,确定真的不来了解一下吗?