介绍
更多知识分享请到 https://zouhua.top/。dplyr是data manipulation的包,其包含多个处理数据的函数。主要函数有:
mutate() 添加新变量.
select() 选择列名.
filter() 过滤行.
summarise() 求和统计.
arrange() 排序.
group_by() 分组处理.
安装
#install.packages("dplyr")
#install.packages("nycflights13")
#devtools::install_github("tidyverse/dplyr")
library(dplyr)
library(nycflights13)
tibbles数据类型
tibbles可以取代data.frame,虽然前者仍然可以认为是数据框类型,在数据处理过程中,tibbles数据类型消耗资源更少,处理速度更快。dplyr的函数可以直接处理tibbles数据类型。
#install.packages("tibble")
library(tibble)
as_tibble(iris)
## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
##
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa
## 7 4.6 3.4 1.4 0.3 setosa
## 8 5 3.4 1.5 0.2 setosa
## 9 4.4 2.9 1.4 0.2 setosa
## 10 4.9 3.1 1.5 0.1 setosa
## # ... with 140 more rows
tibble(
x = 1:5,
y = 1,
z = x ^ 2 + y
)
## # A tibble: 5 x 3
## x y z
##
## 1 1 1 2
## 2 2 1 5
## 3 3 1 10
## 4 4 1 17
## 5 5 1 26
Add new variables with mutate()
添加新的列:新的列一般在数据集的最后一列
flights %>%
select(
year:day,
ends_with("delay"),
distance,
air_time) %>%
mutate(gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)
## # A tibble: 336,776 x 9
## year month day dep_delay arr_delay distance air_time gain speed
##
## 1 2013 1 1 2 11 1400 227 -9 370.
## 2 2013 1 1 4 20 1416 227 -16 374.
## 3 2013 1 1 2 33 1089 160 -31 408.
## 4 2013 1 1 -1 -18 1576 183 17 517.
## 5 2013 1 1 -6 -25 762 116 19 394.
## 6 2013 1 1 -4 12 719 150 -16 288.
## 7 2013 1 1 -5 19 1065 158 -24 404.
## 8 2013 1 1 -3 -14 229 53 11 259.
## 9 2013 1 1 -3 -8 944 140 5 405.
## 10 2013 1 1 -2 8 733 138 -10 319.
## # ... with 336,766 more rows
如果只想保留新生成的列,则使用transmute():
flights %>%
transmute(gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours)
## # A tibble: 336,776 x 3
## gain hours gain_per_hour
##
## 1 -9 3.78 -2.38
## 2 -16 3.78 -4.23
## 3 -31 2.67 -11.6
## 4 17 3.05 5.57
## 5 19 1.93 9.83
## 6 -16 2.5 -6.4
## 7 -24 2.63 -9.11
## 8 11 0.883 12.5
## 9 5 2.33 2.14
## 10 -10 2.3 -4.35
## # ... with 336,766 more rows
Select columns with select()
筛选列,可以给出确切列名,也可通过函数匹配列名:
starts_with("abc"): matches names that begin with “abc”.
ends_with("xyz"): matches names that end with “xyz”.
contains("ijk"): matches names that contain “ijk”.
matches("(.)\1"): selects variables that match a regular expression. This one matches any variables that contain repeated characters. You’ll learn more about regular expressions in strings.
num_range("x", 1:3): matches x1, x2 and x3.
flights %>%
select(ends_with("time"))
## # A tibble: 336,776 x 5
## dep_time sched_dep_time arr_time sched_arr_time air_time
##
## 1 517 515 830 819 227
## 2 533 529 850 830 227
## 3 542 540 923 850 160
## 4 544 545 1004 1022 183
## 5 554 600 812 837 116
## 6 554 558 740 728 150
## 7 555 600 913 854 158
## 8 557 600 709 723 53
## 9 557 600 838 846 140
## 10 558 600 753 745 138
## # ... with 336,766 more rows
everything()选择所有剩余列名(除已选择列名外),可以将某些关心的列排在前面
flights %>%
select(time_hour, air_time, everything())
## # A tibble: 336,776 x 19
## time_hour air_time year month day dep_time sched_dep_time dep_delay arr_time
##
## 1 2013-01-01 05:00:00 227 2013 1 1 517 515 2 830
## 2 2013-01-01 05:00:00 227 2013 1 1 533 529 4 850
## 3 2013-01-01 05:00:00 160 2013 1 1 542 540 2 923
## 4 2013-01-01 05:00:00 183 2013 1 1 544 545 -1 1004
## 5 2013-01-01 06:00:00 116 2013 1 1 554 600 -6 812
## 6 2013-01-01 05:00:00 150 2013 1 1 554 558 -4 740
## 7 2013-01-01 06:00:00 158 2013 1 1 555 600 -5 913
## 8 2013-01-01 06:00:00 53 2013 1 1 557 600 -3 709
## 9 2013-01-01 06:00:00 140 2013 1 1 557 600 -3 838
## 10 2013-01-01 06:00:00 138 2013 1 1 558 600 -2 753
## # ... with 336,766 more rows, and 10 more variables: sched_arr_time , arr_delay ,
## # carrier , flight , tailnum , origin , dest , distance ,
## # hour , minute
Filter rows with filter
根据阈值筛选数据的行: 多个筛选条件,可以通过,链接。判断条件可以是逻辑运算符,如 **>, < != **等。
flights %>%
filter(month == 1, day == 1)
## # A tibble: 842 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier
##
## 1 2013 1 1 517 515 2 830 819 11 UA
## 2 2013 1 1 533 529 4 850 830 20 UA
## 3 2013 1 1 542 540 2 923 850 33 AA
## 4 2013 1 1 544 545 -1 1004 1022 -18 B6
## 5 2013 1 1 554 600 -6 812 837 -25 DL
## 6 2013 1 1 554 558 -4 740 728 12 UA
## 7 2013 1 1 555 600 -5 913 854 19 B6
## 8 2013 1 1 557 600 -3 709 723 -14 EV
## 9 2013 1 1 557 600 -3 838 846 -8 B6
## 10 2013 1 1 558 600 -2 753 745 8 AA
## # ... with 832 more rows, and 9 more variables: flight , tailnum , origin ,
## # dest , air_time , distance , hour , minute , time_hour
Grouped summaries with summarise()
summarise()单独使用时,直接对数据集加和
flights %>%
summarise(delay = mean(dep_delay, na.rm = TRUE))
## # A tibble: 1 x 1
## delay
##
## 1 12.6
summarise()结合group_by()使用:分组求和,过滤并画图(使用 %>% 管道符)
library(ggplot2)
# 分组
flights %>% group_by(dest) %>%
# 每组均值
summarise(count = n(),
dist = mean(distance, na.rm = TRUE), # na.rm=TRUE移除NA值
delay = mean(arr_delay, na.rm = TRUE)) %>%
# 解除分组
ungroup() %>%
# 过滤
filter(count > 20, dest != "HNL") %>%
# 画图
ggplot(aes(x = dist, y = delay)) +
geom_point(aes(size = count), alpha = 1/3) +
geom_smooth(se = FALSE) +
theme_bw()
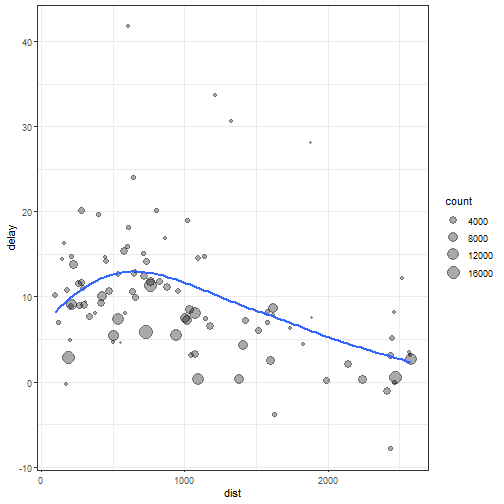
除了mean()函数外,还有其他summary函数:
Measures of Location:
mean(x),median(x).Measures of spread:
sd(x),IQR(x),mad(x).Measures of rank:
min(x),quantile(x, 0.25),max(x).Measures of position:
first(x),nth(x, 2),last(x).
flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay)) %>%
group_by(year, month, day) %>%
summarise(
first_dep = first(dep_time),
last_dep = last(dep_time)
)
## # A tibble: 365 x 5
## # Groups: year, month [12]
## year month day first_dep last_dep
##
## 1 2013 1 1 517 2356
## 2 2013 1 2 42 2354
## 3 2013 1 3 32 2349
## 4 2013 1 4 25 2358
## 5 2013 1 5 14 2357
## 6 2013 1 6 16 2355
## 7 2013 1 7 49 2359
## 8 2013 1 8 454 2351
## 9 2013 1 9 2 2252
## 10 2013 1 10 3 2320
## # ... with 355 more rows
- Counts :
n()简单计数加和延误航班次数,例如D942DN有四次延误记录。
flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay)) %>%
group_by(tailnum) %>%
summarise(
delay = mean(arr_delay),
n = n())
## # A tibble: 4,037 x 3
## tailnum delay n
##
## 1 D942DN 31.5 4
## 2 N0EGMQ 9.98 352
## 3 N10156 12.7 145
## 4 N102UW 2.94 48
## 5 N103US -6.93 46
## 6 N104UW 1.80 46
## 7 N10575 20.7 269
## 8 N105UW -0.267 45
## 9 N107US -5.73 41
## 10 N108UW -1.25 60
## # ... with 4,027 more rows
flights %>% filter(tailnum == "D942DN")
## # A tibble: 4 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier
##
## 1 2013 2 11 1508 1400 68 1807 1636 91 DL
## 2 2013 3 23 1340 1300 40 1638 1554 44 DL
## 3 2013 3 24 859 835 24 1142 1140 2 DL
## 4 2013 7 5 1253 1259 -6 1518 1529 -11 DL
## # ... with 9 more variables: flight , tailnum , origin , dest , air_time ,
## # distance , hour , minute , time_hour
统计非NA值使用sum(!is.na(x)),统计unique值使用n_distinct(x).
flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay)) %>%
group_by(dest) %>%
summarise(carriers_unique = n_distinct(carrier),
carrriers_nona = sum(!is.na(carrier)),
carrriers_n = n()) %>%
arrange(desc(carriers_unique)) %>%
ungroup()
## # A tibble: 104 x 4
## dest carriers_unique carrriers_nona carrriers_n
##
## 1 ATL 7 16837 16837
## 2 BOS 7 15022 15022
## 3 CLT 7 13674 13674
## 4 ORD 7 16566 16566
## 5 TPA 7 7390 7390
## 6 AUS 6 2411 2411
## 7 DCA 6 9111 9111
## 8 DTW 6 9031 9031
## 9 IAD 6 5383 5383
## 10 MSP 6 6929 6929
## # ... with 94 more rows
flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay)) %>%
count(dest)
## # A tibble: 104 x 2
## dest n
##
## 1 ABQ 254
## 2 ACK 264
## 3 ALB 418
## 4 ANC 8
## 5 ATL 16837
## 6 AUS 2411
## 7 AVL 261
## 8 BDL 412
## 9 BGR 358
## 10 BHM 269
## # ... with 94 more rows
Grouping by multiple variables
根据多个变量分组计算
flights %>%
group_by(year, month, day) %>%
summarise(flights = n())
## # A tibble: 365 x 4
## # Groups: year, month [12]
## year month day flights
##
## 1 2013 1 1 842
## 2 2013 1 2 943
## 3 2013 1 3 914
## 4 2013 1 4 915
## 5 2013 1 5 720
## 6 2013 1 6 832
## 7 2013 1 7 933
## 8 2013 1 8 899
## 9 2013 1 9 902
## 10 2013 1 10 932
## # ... with 355 more rows
Arrange rows with arrange()
按照从大到小对行排序:desc(rownames)
flights %>%
arrange(year, desc(month), day)
## # A tibble: 336,776 x 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier
##
## 1 2013 12 1 13 2359 14 446 445 1 B6
## 2 2013 12 1 17 2359 18 443 437 6 B6
## 3 2013 12 1 453 500 -7 636 651 -15 US
## 4 2013 12 1 520 515 5 749 808 -19 UA
## 5 2013 12 1 536 540 -4 845 850 -5 AA
## 6 2013 12 1 540 550 -10 1005 1027 -22 B6
## 7 2013 12 1 541 545 -4 734 755 -21 EV
## 8 2013 12 1 546 545 1 826 835 -9 UA
## 9 2013 12 1 549 600 -11 648 659 -11 US
## 10 2013 12 1 550 600 -10 825 854 -29 B6
## # ... with 336,766 more rows, and 9 more variables: flight , tailnum , origin ,
## # dest , air_time , distance , hour , minute , time_hour
across()
对多个列做同一个操作,可以使用across()处理
flights %>% group_by(dest) %>%
summarise(dist = mean(distance, na.rm = TRUE),
delay = mean(arr_delay, na.rm = TRUE)) %>%
ungroup()
## # A tibble: 105 x 3
## dest dist delay
##
## 1 ABQ 1826 4.38
## 2 ACK 199 4.85
## 3 ALB 143 14.4
## 4 ANC 3370 -2.5
## 5 ATL 757. 11.3
## 6 AUS 1514. 6.02
## 7 AVL 584. 8.00
## 8 BDL 116 7.05
## 9 BGR 378 8.03
## 10 BHM 866. 16.9
## # ... with 95 more rows
flights %>% select(dest, distance, arr_delay) %>%
group_by(dest) %>%
summarise(across(where(is.numeric), mean, na.rm = TRUE)) %>%
ungroup()
## # A tibble: 105 x 3
## dest distance arr_delay
##
## 1 ABQ 1826 4.38
## 2 ACK 199 4.85
## 3 ALB 143 14.4
## 4 ANC 3370 -2.5
## 5 ATL 757. 11.3
## 6 AUS 1514. 6.02
## 7 AVL 584. 8.00
## 8 BDL 116 7.05
## 9 BGR 378 8.03
## 10 BHM 866. 16.9
## # ... with 95 more rows
across() 常用场景
df %>% mutate_if(is.numeric, mean, na.rm = TRUE)
# ->
df %>% mutate(across(where(is.numeric), mean, na.rm = TRUE))
df %>% mutate_at(vars(x, starts_with("y")), mean, na.rm = TRUE)
# ->
df %>% mutate(across(c(x, starts_with("y")), mean, na.rm = TRUE))
df %>% mutate_all(mean, na.rm = TRUE)
# ->
df %>% mutate(across(everything(), mean, na.rm = TRUE))
R information
sessionInfo()
## R version 4.0.2 (2020-06-22)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19042)
##
## Matrix products: default
##
## locale:
## [1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252
## [3] LC_MONETARY=English_United States.1252 LC_NUMERIC=C
## [5] LC_TIME=English_United States.1252
## system code page: 936
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] ggplot2_3.3.2 tibble_3.0.3 dplyr_1.0.2 nycflights13_1.0.1
##
## loaded via a namespace (and not attached):
## [1] pillar_1.4.6 compiler_4.0.2 highr_0.8 tools_4.0.2 digest_0.6.25
## [6] jsonlite_1.7.1 evaluate_0.14 lifecycle_0.2.0 gtable_0.3.0 nlme_3.1-150
## [11] lattice_0.20-41 mgcv_1.8-33 pkgconfig_2.0.3 rlang_0.4.7 Matrix_1.2-18
## [16] cli_2.1.0 yaml_2.2.1 xfun_0.18 withr_2.3.0 stringr_1.4.0
## [21] knitr_1.30 generics_0.1.0 vctrs_0.3.4 grid_4.0.2 tidyselect_1.1.0
## [26] glue_1.4.2 R6_2.5.0 fansi_0.4.1 rmarkdown_2.5 purrr_0.3.4
## [31] farver_2.0.3 magrittr_1.5 scales_1.1.1 ellipsis_0.3.1 htmltools_0.5.0
## [36] splines_4.0.2 assertthat_0.2.1 colorspace_1.4-1 labeling_0.4.2 utf8_1.1.4
## [41] stringi_1.5.3 munsell_0.5.0 crayon_1.3.4
引用
dplyr
R for Data Science
dplyr across
参考文章如引起任何侵权问题,可以与我联系,谢谢。