索引总结
--Kane
1. 索引
每个InnoDB表都具有一个特殊的索引为聚簇索引,如果表上有定义主键,则该主键就是聚簇索引,如果未定义主键,mysql会取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引,如果没有这样的列,InnoDB就自己产生一个这样的ID值,它是6个字节,而且是隐藏的,使其作为聚簇索引。
一级索引:表中的聚簇索引;
二级索引(或辅助索引):除一级索引外,所有的非聚簇索引都是。
1)索引数据结构
B-Tree
为了描述B-Tree,首先定义一条数据记录为一个二元组[key, data],key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据。那么B-Tree是满足下列条件的数据结构:
d>=2,即B-Tree的度;
h为B-Tree的高;
每个非叶子结点由n-1个key和n个指针组成,其中d<=n<=2d;
每个叶子结点至少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶结点的指针均为NULL;
所有叶结点都在同一层,深度等于树高h;
key和指针相互间隔,结点两端是指针;
一个结点中的key从左至右非递减排列;
如果某个指针在结点node最左边且不为null,则其指向结点的所有key小于
如果某个指针在结点node最右边且不为null,则其指向结点的所有key大于
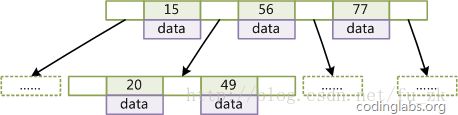
B+Tree
B+Tree是B树的变种,有着比B树更高的查询性能,来看下m阶B+Tree特征:
1、有m个子树的节点包含有m个元素(B-Tree中是m-1)
2、根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中。
3、所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素。
4、叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小从小到大顺序链接。
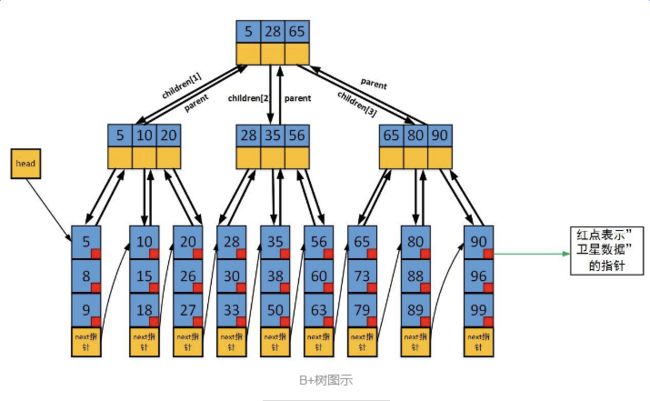
1、红点表示是指向卫星数据的指针,指针指向的是存放实际数据的磁盘页,卫星数据就是数据库中一条数据记录。
2、叶子节点中还有一个指向下一个叶子节点的next指针,所以叶子节点形成了一个有序的链表,方便遍历B+树。
2)MyISAM的索引
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
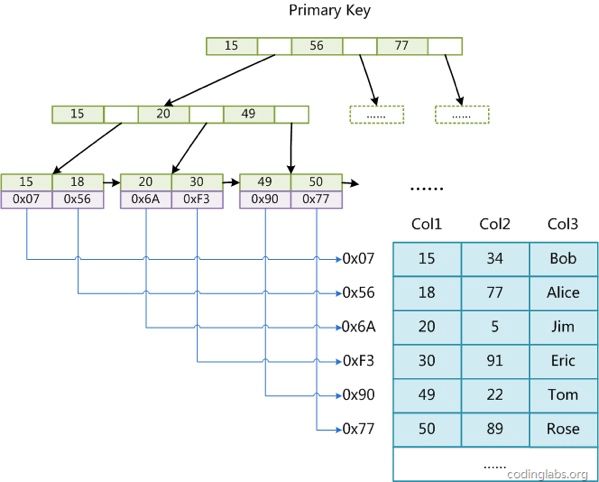
这里设表一共有三列,假设我们以Col1为主键,上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
3)InnoDB的索引
InnoDB的索引有两类索引:
一级索引:表中的聚簇索引;
二级索引(或辅助索引):除一级索引外,所有的非聚簇索引都是。
(1)如果定义了主键,则主键,就是聚簇索引
(2)如果表没有定义主键,则第一个非空unique唯一索引作为聚簇索引
(3)否则,innoDB会创建一个ID值,它是6个字节,而且是隐藏的,使其作为聚簇索引。
说明索引存储结构:B+Tree,部分结论:
(1)在索引结构中,非叶子节点存储主键,叶子节点存储value
(2)聚簇索引,叶子节点存储行记录(InnoDB索引和记录是存储在一起的,MyISAM的索引和记录是分开存储的)
(3)二级索引(普通索引)中,叶子节点存储的是主键(这就意味着,通过二级索引查找行,存储引擎需要进行两遍扫描,首先需要找到二级索引的叶子节点,获得对应的主键值,然后根据这个主键值去聚簇索引查找行)
针对二级索引(普通索引)进行两遍扫描进行举例说明:
t(id PK, name KEY, sex, flag);
表中有四条记录:
1, shenjian, m, A 3, zhangsan, m, A 5, lisi, m, A 9, wangwu, f, B
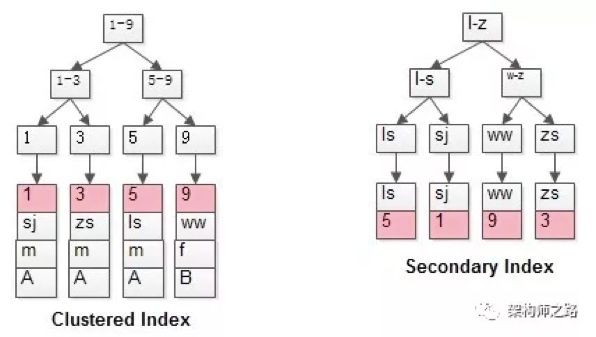
可以看到:
(1) 第一幅,id主键的聚簇索引,叶子存储了所有的行记录
(2) 第二幅,name上的普通索引,叶子存储了主键的值
对于:
select * from t where name=’shenjian’;
(1) 会先在name普通索引上查询到主键id=1;
(2) 再在聚簇索引下查询到(1,shenjian,m,A)的行记录;
不会使用索引的情况如下:
1. 以%开头的LIKE查询不会使用B-TREE索引。
2. 数据类型出现隐式转换时不会使用索引。比如某列是varchar类型当查询语句为:
column_name = 1时不会使用索引,而查询语句为:column_name = ‘1’时可以使用索引。
3. 不符合最左前缀原则
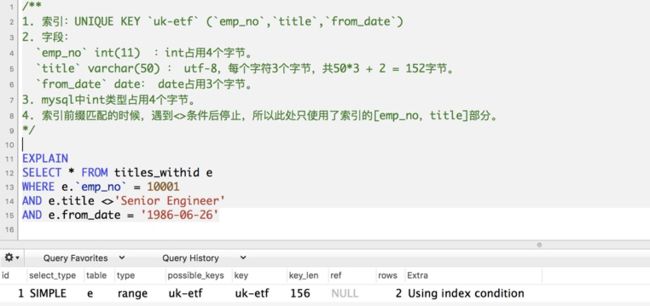
4. 如果查询条件有or分割,or前面的使用索引,or后面的未使用索引,则不会使用索引。
因为即使or之前的使用了索引,但是or之后的也需要全表查询,索引就忽略索引,直接全表查询。
5. 如果MySql认为使用索引会比全表查询更慢,则不会使用索引。
6. 如果查询条件中含有函数或表达式,则MySQL不会为这列使用索引
聚簇索引优势:
主键访问/修改相对较快
使用覆盖索引扫描的查询可以直接使用节点中的主键值
减小了移动数据或者数据页面分裂时维护二级索引的开销
劣势:
通过二级索引查询数据,需要访问额外的一次索引访问
全表扫描性能相对较慢。
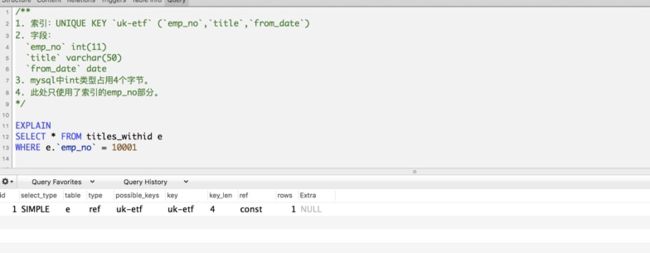
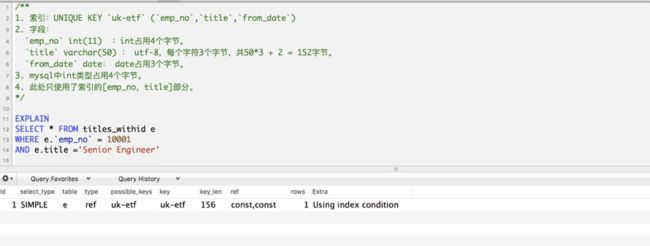
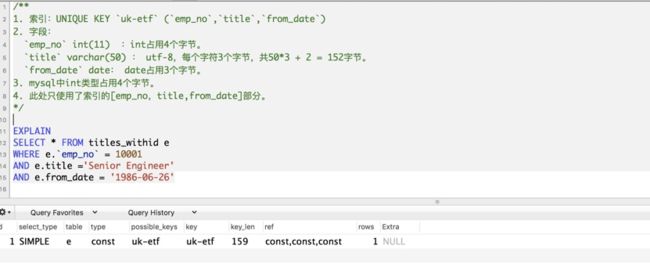
4)"最左前缀匹配”的原则
最左前缀匹配原则,非常重要的原则,
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配;
比如`a = 1 and b = 2 and c > 3 and d = 4 `
如果建立(a,b,c,d)顺序的索引,d是用不到索引的;
如果建(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序=,
mysql的查询优化器会帮你优化成索引可以识别的形式
考虑定义为key1(P1,P2)的复合索引:
条件P1 = 1定义了此间隔:
(1,-inf) <= (P1, P2) < (1,+inf)
条件P1 = 1 AND P2 < 2定义了此间隔:
(1,-inf) < (P1, P2) < (1,2)
条件P1 > 5定义了间隔:
(5,-inf) < (P1, P2)
条件P1 = 'foo' AND P2 >= 10 AND P3 > 10
的间隔为:
('foo',10,-inf) < (P1,P2,P3) < ('foo',+inf,+inf)
相反,条件P3 ='abc'不定义单个间隔,范围访问方法不能使用。
所以,复合索引遵循“最左前缀匹配”的原则。
只要比较运算符为=,<=>或IS NULL,优化器将尝试使用其他关键部件来确定间隔。
如果操作符是>,<,> =,<=,!=,<>,BETWEEN或LIKE,则优化程序使用它,但不再考虑关键部分。
EXPLAIN输出中的key_len列表示使用的key前缀的最大长度。
举例:
5) 覆盖索引
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为“覆盖索引”,
即只需扫描索引而无需回表;
优点:
(1)索引条目通常远小于数据行大小,只需读取索引,则极大减少数据访问量
(2)因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从
磁盘读取每一行数据的io少很多次;
(3)一些存储引擎如MYISAM在内存中只缓存索引,数据则依赖于操作系统来缓存,
因此要访问数据需要一次系统调用。
(4)InnoDB的聚簇索引,覆盖索引对InnoDB,非常有用,InnoDB的二级索引在叶子节点中保存了行
的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询
假设表:
CREATE TABLE `test_student2` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=283 DEFAULT CHARSET=utf8 COMMENT='测试表';

使用explain,可以通过输出的extra列来判断,对于一个索引覆盖查询,显示为using index,MySQL查询优化器在执行查询前会决定是否有索引覆盖查询。
Extra 字段
Using where:在查找使用索引的情况下,需要回表去查询所需的数据,表示优化器需要通过索引回表查询数据; Using index:使用覆盖索引的时候就会出现,表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表; Using index condition:查找使用了索引,但是需要回表查询数据 Using where && Using index:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据
6) 索引合并
index merge
where 中可能有多个条件(或者join)涉及到多个字段,它们之间进行 AND 或者 OR,那么此时就有可能会使用到 index merge 技术。index merge 技术如果简单的说,其实就是:对多个索引分别进行条件扫描,然后将它们各自的结果进行合并(intersect/union)。
MySQL5.0之前,一个表一次只能使用一个索引,无法同时使用多个索引分别进行条件扫描。但是从5.1开始,引入了 index merge 优化技术,对同一个表可以使用多个索引分别进行条件扫描。
1、索引合并是把几个索引的范围扫描合并成一个索引。
2、索引合并的时候,会对索引进行并集,交集或者先交集再并集操作,以便合并成一个索引。
3、这些需要合并的索引只能是一个表的。不能对多表进行索引合并。
对这些索引取交集,并集,或者先取交集再取并集。从而减少从数据表中取数据的次数,提高查询效率
index merge: 同一个表的多个索引的范围扫描可以对结果进行合并,合并方式分为三种:union, intersection, 以及它们的组合(先内部intersect然后在外面union)。
索引合并方法有几个算法:
Using intersect(…)
Using union(…)
Using sort_union(…)
例子:
(1). index merge 之 intersect
index intersect merge就是多个索引条件扫描得到的结果进行交集运算。显然在多个索引提交之间是 AND 运算时,才会出现 index intersect merge. 下面两种where条件或者它们的组合时会进行 index intersect merge:
a、条件使用到复合索引中的所有字段或者左前缀字段(对单字段索引也适用)
key_part1=const1 AND key_part2=const2 ... AND key_partN=constN
b、主键上的任何范围条件
SELECT * FROM innodb_table WHERE primary_key < 10 AND key_col1=20;
SELECT * FROM tbl_name WHERE (key1_part1=1 AND key1_part2=2) AND key2=2;
适用于同一张表上的多个索引的AND条件:
索引合并交集访问算法对所有使用的索引执行同时扫描,并产生从合并索引扫描中接收到的行序列的交集。
�(2). index merge 之 union
index uion merge就是多个索引条件扫描,对得到的结果进行并集运算,显然是多个条件之间进行的是 OR 运算。
下面几种类型的 where 条件,以及他们的组合可能会使用到 index union merge算法:
1) 条件使用到复合索引中的所有字段或者左前缀字段(对单字段索引也适用)
2) 主键上的任何范围条件
3) 任何符合 index intersect merge 的where条件;
上面三种 where 条件进行 OR 运算时,可能会使用 index union merge算法。
适用于同一张表上的多个索引的OR条件:
索引合并并集访问算法对所有使用的索引执行同时扫描,并产生从合并索引扫描中接收到的行序列的并集。
SELECT * FROM t1 WHERE key1=1 OR key2=2 OR key3=3;
上例,就是三个 单字段索引 进行 OR 运算,所以他们可能会使用 index union merge算法。
SELECT * FROM innodb_table WHERE (key1=1 AND key2=2) OR (key3='foo' AND key4='bar') AND key5=5;
上例,复杂一点。(key1=1 AND key2=2) 是符合 index intersect merge;(key3='foo' AND key4='bar') AND key5=5也是符合index intersect merge,所以 二者之间进行 OR 运算,自然可能会使用 index union merge算法。
(3).index merge 之 sort_union
多个条件扫描进行 OR 运算,但是不符合 index union merge算法的,此时可能会使用 sort_union算法
SELECT * FROM t1 WHERE key1 = 1 OR key2 > 10;
适用于同一张表上的多个索引的OR条件:
索引合并排序并集算法对所有使用的索引执行同时扫描,扫描结果返回ID,对ID进行排序后执行并集操作,然后再根据ID获取数据。�
索引合并的执行计划
在type列中显示index_merge。
在Extra列中显示:
Using intersect(...)
Using union(...)
Using sort_union(...)
7)前缀索引
- 场景:用在大字段上或者长度比较尝的字符串上,使用字符串的前缀作为索引。
- 语法:传入一个参数,代表截取的长度。
- 优势:使用在较大的字段上,可以使索引更小,提升查询性能。
- 缺陷:因为只存储了前缀,所以无法作为数据来操作,如order by和group by的部分,无法使用这个索引来优化。 也无法使用索引覆盖扫描。
8)索引条件下推
“索引条件下推”,称为 Index Condition Pushdown (ICP),这是MySQL提供的用某一个索引对一个特定的表从表中获取元组”,注意我们这里特意强调了“一个”,这是因为这样的索引优化不是用于多表连接而是用于单表扫描,确切地说,是单表利用索引进行扫描以获取数据的一种方式。
一是减少完整记录(一条完整元组)读取的个数;
二是对于InnoDB聚集索引无效,只能是对SECOND INDEX这样的非聚集索引有效。
实例:
set optimizer_switch='index_condition_pushdown=off'; //关闭ICP

set optimizer_switch='index_condition_pushdown=on';
//打开ICP,则Extra列中显示“Using index condition”

(1)不使用ICP技术(过程使用数字符号标示,如①②③等)
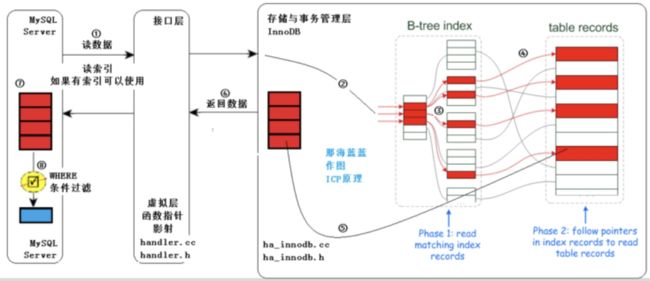
过程解释:
① MySql Server 发出读取数据的命令,调用存储引擎的索引读/全表读,进行读索引,
②、③ :进入存储引擎,读取索引树,在索引树上查找,把满足条件的(经过查找,发现红色的数据满足),
从表记录中读出(步骤④,通常有IO);此过程,从存储引擎返回⑤标识的结果的过程,
②到⑤之间,不仅要在索引行(通常内存中,速度快,步骤③),还要进行步骤④,通常有IO。
⑥: 从存储引擎返回查找到的多条元组给MySQL Server,
MySQL Server在⑦得到较多的元组。
⑦--⑧:⑦到⑧依据WHERE子句条件进行过滤,得到满足条件的元组。
注意在MySQL Server层得到较多元组,然后才过滤,最终得到的是少量的、符合条件的元组。
通俗来讲:
a.服务层负责根据查询条件确定索引元组间隔,并将元组间隔交给存储引擎层。 b.存储引擎层根据查询元组间隔,查找索引B+树,获取pk,然后去聚簇索引拿到数据,返回给服务层。 c.服务层对数据进行过滤(查询元组外的其他where条件)。
(2)使用ICP技术(过程使用数字符号标示,如①②③等)
![使用ICP技术].png](https://upload-images.jianshu.io/upload_images/9954986-a62c4bf203091beb.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
过程解释:
①:MySQL Server发出读取数据的命令,过程同图一。 ②、③:进入存储引擎,读取索引树,在索引树上查找,把满足已经下推的条件的(经过查找,红色的满足), 从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。此处,不仅要在索引行进行索引读取(通常是内存中,速度快,步骤③),还要在③这个阶段依据下推的条件进行判断,不满足条件的,不去读取表中的数据,直接在索引树上进行下一个索引项的判断,直到有满足条件的,才进行步骤④,这样较没有ICP的方式,IO量减少。 ⑥:从存储引擎返回查找到的少量元组给MySQL Server,MySQL Server在⑦得到少量的元组。因此比较图一无ICP的方式,返回给MySQL Server层的即是少量的、符合条件的元组。
概括讲:
服务层负责根据查询条件确定索引元组间隔,并将元组间隔和(索引相关的)查询条件交给存储引擎层。 存储引擎层根据查询元组间隔,查找索引B+树,在查找的同时,会根据查询条件进行过滤,获取pk, 然后去聚簇索引拿到数据,返回给服务层。 服务层对数据进行过滤(索引条件外的其他where条件)。
实现细节
1 ICP只能用于辅助索引,不能用于聚集索引。 2 ICP只用于单表,不是多表连接是的连接条件部分(如开篇强调)
如果使用了IPC,执行计划的Extra列会显示"Using index condition"
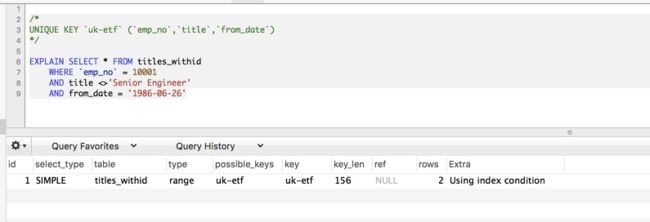
9)索引排序问题-order by
order by 实质是先排序后分组
(1)创建测试表:
CREATE TABLE tblA(
#id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
age INT,
birth TIMESTAMP NOT NULL
);
#插入数据
INSERT INTO tblA(age, birth) VALUES(22, NOW());
INSERT INTO tblA(age, birth) VALUES(23, NOW());
INSERT INTO tblA(age, birth) VALUES(24, NOW());
#添加索引
CREATE INDEX indx_A_ageBirth ON tblA(age, birth);
SELECT * FROM tblA;
(2)查看几组sql:
a. 按照索引顺序进行order by,不会产生Using filesort,使用索引进行排序:
EXPLAIN SELECT * FROM tblA WHERE age > 20 ORDER BY age;

EXPLAIN SELECT * FROM tblA WHERE age > 20 ORDER BY age, birth;

b.
EXPLAIN SELECT * FROM tblA WHERE age = 20 ORDER BY birth;

下面age遇到>索引截止,order by不使用索引了。age不再order by范围内了,前面where条件还是大于号(范围值),索引断了,所以排序的时候无法用到索引,产生了Using filesort
EXPLAIN SELECT * FROM tblA WHERE age > 20 ORDER BY birth;

EXPLAIN SELECT * FROM tblA WHERE age > 20 ORDER BY birth, age;

c.
EXPLAIN SELECT * FROM tblA ORDER BY age ASC, birth DESC;
EXPLAIN SELECT * FROM tblA ORDER BY age DESC, birth ASC;

EXPLAIN SELECT * FROM tblA ORDER BY age ASC, birth ASC;
EXPLAIN SELECT * FROM tblA ORDER BY age DESC, birth DESC;

序的话要么都升序,要么都降序,否则mysql内部会不知道怎么排序,排序也是索引的一部分(Btree),所以不一致时会产生Using filesort
(3)可以用到索引的排序:
key a_b_c(a , b , c)
key e_m_n(e , m , n)
order by 能使用索引最左前缀:
ORDER BY a
ORDER BY a ,b
ORDER BY a ,b ,c
ORDER BY a DESC, b DESC, c DESC
如果WHERE使用索引的最左前缀定义为常量,则order by 能使用索引:
WHERE a = constant ORDER BY b ,c
WHERE a = constant AND b = constant ORDER BY c
WHERE a = constant AND b > constant ORDER BY b, c
(4)不能使用索引排序
上下排序不一致
ORDER BY a ASC ,b DESC ,c DESC
该查询对不同索引使用ORDER BY:
SELECT * FROM t1 ORDER BY a, m;
查询在索引的非连续部分使用ORDER BY:
WHERE m=constant ORDER BY a, c
该查询使用ORDER BY与包含除索引列名称之外的术语的表达式:
ORDER BY ABS(a);
ORDER BY -a;
WHERE a=constant ORDER BY a, x
该查询连接了许多表,并且ORDER BY中的列不是全部来自用于检索行的第一个表。
索引是前缀索引将无法使用order by
filesort排序算法说明mysql不能使用索引,需要手动处理排序的时候采取的算法。filesort排序算法并不像它名字中体现的有file,如果可以,mysql会不使用临时文件,只是在内存中排序,但是在执行计划中,统一显示“using filesort”。对大结果集(where条件后,limit前)进行排序是一项及其耗时费力的操作,并发的排序请求会严重拖垮数据库性能。编码中应该避免。Mysql的排序算法包含:原始文件排序算法,改进文件排序算法,内存中的排序算法。
实现比较复杂,简单来说,排序的基本逻辑如图:
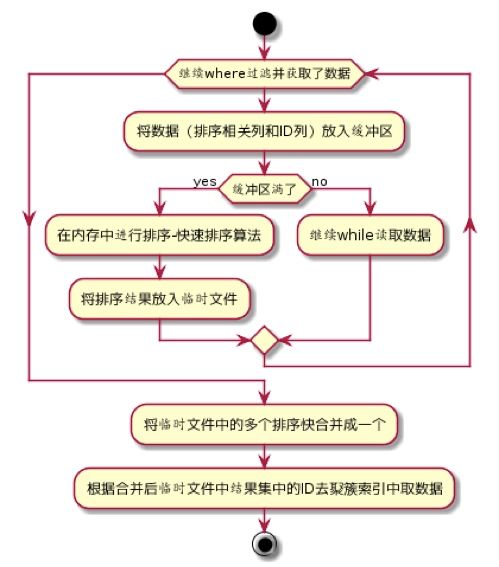
10)执行计划
执行计划中的列说明:
id:id用来表示执行顺序,id相同的为一组,先执行id数字大的组,然后执行数字小的组。在id相同的一组内,
顺序由上而下执行。子查询和union操作产生新的id,普通的join不会产生新id。
select type:查询类型,如普通查询,子查询,union,物化视图等,对于只写单表的我们,意义不大。
possible_keys:可能会用到的索引。
key:最终使用的索引。
key_len:使用索引的字节数。
rows:表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数。
ref:记录使用key列标识的索引时,查找值使用的常数或者列。
extra列:
use index:使用了覆盖索引扫描。
use where:这里并不是表示使用了where条件的意思,而是说服务层从存储引擎获取数据
之后再进行where过滤。(事实上,这一列总是在不该出现的时候出现)
Using index condition:表示使用索引条件下推。
Using filesort:使用了排序
Using temporary:使用了临时表
Impossible WHERE:出现在优化阶段,优化器根据表定义可以判断出where条件根本不可能成立,
比如主健不可能为空
Using join buffer (Block Nested Loop):mysql使用了优化过的nest loop算法,
一次读取多个块.