利用pyecharts对职位数据进行地图可视化
前言
pyecharts 是基于百度开源的Echarts、方便与Python 进行对接、直接可以用于python的一个库。
今天我们利用pyecharts实现职位数据的地图可视化。
安装pyecharts
pyecharts 的安装只需要在命令端输入以下命令。
pip install pyecharts
如果下载失败或者觉得下载太慢,可以用镜像进行下载:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyecharts
pyecharts 目前不再自带地图 js 文件。所以要自行安装对应的地图文件包,如果下载失败或者觉得下载太慢,可以用镜像进行下载。
pip install echarts-countries-pypkg # 世界地图
pip install echarts-china-provinces-pypkg # 中国省级行政区地图
pip install echarts-china-cities-pypkg # 中国城市地图
pip install echarts-china-counties-pypkg # 中国县区地图
pip install echarts-china-misc-pypkg # 中国区域地图
pip install echarts-united-kingdom-pypkg
小试牛刀
导入需要的模块:
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import *
from pyecharts.globals import ThemeType
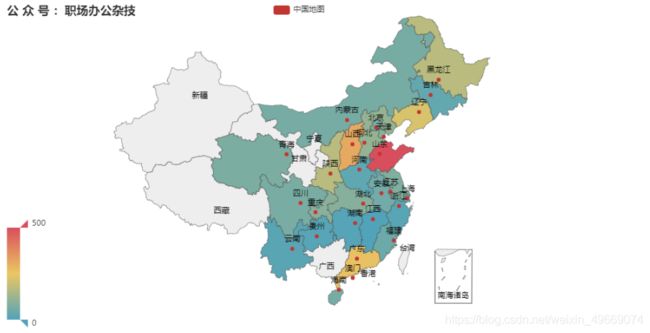
先简单的绘制出中国地图:
# 数据
data = {'河南': 25, '北京': 65, '河北': 111, '辽宁': 221, '江西': 1, '上海': 22, '安徽': 56, '江苏': 78, '湖南': 9,'浙江': 13, '海南': 62, '广东': 262, '湖北': 87, '黑龙江': 171, '澳门': 61, '陕西': 171, '四川': 67, '内蒙古': 63, '重庆': 93,'云南': 16, '贵州': 12, '吉林': 33, '山西': 312, '山东': 511, '福建': 46, '青海': 71, '天津': 91,'其他': 71}
# 以元组的方式输出数值
data_list = list(zip(data.keys(), data.values()))
map_ = (
Map() # 如果想绘制其它图形,可修改Map
.add(series_name="中国地图",data_pair=data_list,maptype="china")
.set_global_opts(title_opts=opts.TitleOpts(title="公 众 号 :Python与Excel之交")
# 设置地图显示最大值
,visualmap_opts=opts.VisualMapOpts(max_=500))
)
map_.render_notebook()
实战
导入数据源:
df = pd.read_csv('D:\数据小刀\爬虫④\前程无忧\前程无忧.csv')
df.head()

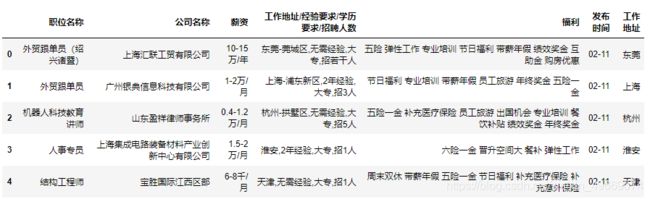
我们先对数据源的工作地址,进行字符串的切割,取出上海、广州等城市名称:
df["工作地址"] = df["工作地址/经验要求/学历要求/招聘人数"].str.split(',', expand=True)[0]
df["工作地址"] = df["工作地址"].str.split('-', expand=True)[0]
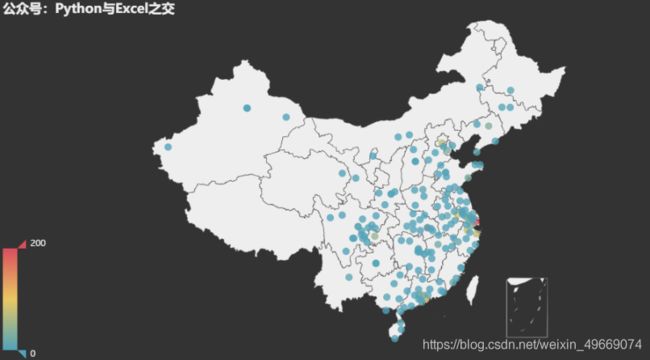
因为maptype=‘china’时,地图只显示全国省级行政区,数据只能是省级行政区,不能显示城市名称,所以我们需要导入经纬度,绘制散点图。
df1 = pd.read_csv('D:\数据小刀\爬虫④\拉勾网\中国城市地理坐标.csv')
coords = {df1.iloc[i]['地名']: [df1.iloc[i]['经度'], df1.iloc[i]['纬度']] for i in range(len(df1))}
去除没有经纬度的地区和不必要的字符串:
df = df[(df['工作地址'] != '异地招聘')]
df = df[(df['工作地址'] != '工作地址/经验要求/学历要求/招聘人数')]
df = df[(df['工作地址'] != '雄安新区')]
统计每个城市的职位数量,并以元组的方式输出数值:
df_0 = df['工作地址'].astype("str").value_counts()
df_0 = df_0.sort_values(ascending=False)
regions = df_0.index.to_list()
values = df_0.to_list()
data_list = list(zip(regions, values))

设置背景颜色:
geo = Geo(init_opts=opts.InitOpts(theme=ThemeType.DARK))
设置地图类型为中国地图,当maptype等于广东、广州时,可修改为对应的地图:
geo.add_schema(maptype='china')
设置经纬度:
for key, value in coords.items():
geo.add_coordinate(key, value[0], value[1])
设置图例,数据,散点大小,散点颜色:
geo.add('',data_list, symbol_size=10, itemstyle_opts=opts.ItemStyleOpts(color='blue'))
设置为数据不显示,设置为散点图,当type等于heatmap时可修改为热力图:
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=False), type='scatter')
设置地图显示最大值:
geo.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=200),title_opts=opts.TitleOpts(title='公众号:Python与Excel之交'))
geo.render_notebook() # 打开
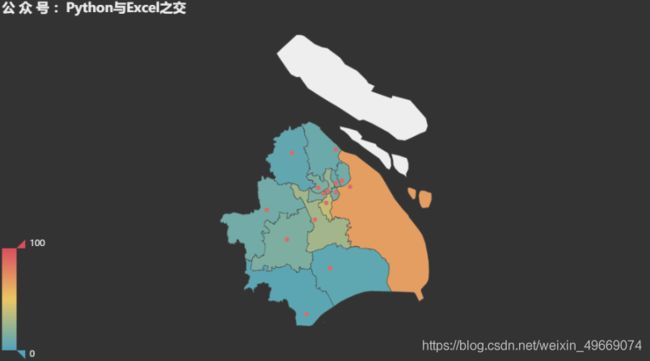
取出上海的行政区,利用Map进行地图可视化:
df["工作地址"] = df["工作地址/经验要求/学历要求/招聘人数"].str.split(',', expand=True)[0]
df8 = df.工作地址.str.contains('上海-.*') # 利用正则表达式进行匹配
df8 = df[df8]
df8 = df8["工作地址"].str.split('-', expand=True)[1]
df8 = df8.astype("str").value_counts()
df8 = df8.sort_values(ascending=False)
regions = df8.index.to_list()
values = df8.to_list()
data_list = list(zip(regions, values))
map_ = (
Map(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add("",data_pair=data_list,maptype="上海") # 修改地图
.set_global_opts(legend_opts = opts.LegendOpts(is_show = False)
,title_opts=opts.TitleOpts(title="公 众 号 :Python与Excel之交")
,visualmap_opts=opts.VisualMapOpts(max_=100,is_piecewise=False))
.set_series_opts(label_opts=opts.LabelOpts(is_show = False,font_size=15))
)
map_.render_notebook()