1. 简称
论文《Switch-based Active Deep Dyna-Q: Efficient Adaptive Planning for Task-Completion Dialogue Policy Learning》简称Switch-DDQ,作者Yuexin Wu(Carnegie Mellon University),经典的对话策略学习论文。
2. 摘要
使用强化学习训练任务完成对话代理通常需要大量真实的用户体验。
Dyna-Q算法通过整合世界模型来扩展Q-learning,从而可以有效地利用世界模型产生的模拟经验来提高训练效率。
然而,Dyna-Q的有效性取决于世界模型的质量--或隐含地取决于Q-learning的预先指定的真实经验与模拟经验的比率。
为此,我们通过集成一个switcher(切换器)来扩展最近提出的Deep Dyna-Q(DDQ)框架,该switcher(切换器)可以自动确定是使用真实体验还是模拟体验进行Q-learning。
此外,我们探索了使用主动学习来提高样本效率,方法是鼓励世界模型在代理尚未(充分)探索的状态-行动空间中生成模拟经验。
我们的结果表明,通过将Switcher和主动学习相结合,名为Switch-based Active Deep Dyna-Q(Switch-DDQ)的新框架在模拟和人工评估方面都比DDQ和Q-learning基线有了显著的改善。
3. 核心
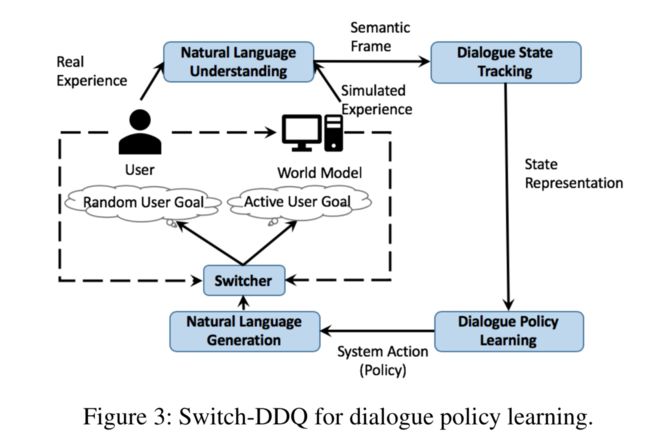
我们在图3中描述了我们的Switch-DDQ流水线。代理由六个模块组成:(1)基于lstm的自然语言理解模块(hakani-Tür et al.。
2016)用于提取用户意图/目标并计算其相关联的槽;(2)状态跟踪器(MRKS、ˇ、IC、́等,2016)用于跟踪对话状态;(3)通过使用当前对话状态的信息来选择下一个动作的对话策略;(4)基于模型的自然语言生成(NLG)模块,其输出自然语言响应(wen et al.。2015);(5)用于基于主动用户目标选择生成模拟用户动作和模拟奖励的世界模型;以及(6)用于选择对话策略训练的数据源(模拟或真实体验)的基于RNN的切换器。图中的实线说明了迭代对话策略培训循环,而虚线显示了培训世界模型和switcher(交换机)时的数据流。
3.1 Direct Reinforcement Learning and Planning

通常,在RL设置中,可以将对话策略学习表述为Markov决策过程,可以将任务完成对话视为(状态,动作,奖励)元组的序列。我们采用深度Q网络(DQN)(Mnih等人,2015)来训练对话策略(算法1中的第12行)。直接强化学习和规划都分别使用相同的Q-learning算法使用模拟和真实经验来完成。
具体而言,在每个步骤中,代理都接收状态并选择要执行到下一个对话回合的动作。使用基于的探索策略来选择动作,】其中概率被执行为随机动作,否则存在使函数最大化的动作。函数由参数化的多层感知器参数化。然后,代理从环境中观察到奖励,从真实用户或模拟器中观察到相应的响应,将对话状态更新为,直到对话结束。
然后将经验分别存储到用户经验缓冲器或模拟器经验缓冲器中。可以使用存储在缓冲器中的经验来改善函数Q(·)。
在实现中,我们优化参数。均方损失:
其中是先前版本的副本,并且仅定期更新,而是折扣因子。使用反向传播和小批量梯度下降更新。
3.2 Active Planning based on World Model
在典型的任务完成对话(Schatzmann等,2007)中,用户开始进行对话时会想到一个由多个约束组成的特定目标。例如,在电影票预订场景中,约束条件可能是剧院的位置,购买票的数量以及电影的名称。用户目标的一个例子是request(theater;numberofpeople=2, moviename=mission impossible),以其自然语言形式表示为“in which theater can I buy two tickets for mission impossible”。尽管对真实体验中的用户目标范围没有明确限制,但是在规划阶段,世界模型可以有选择地生成状态-动作空间中未(完全)由对话代理探索的模拟体验。针对特定的用户目标,以提高样本效率。我们将计划称为主动计划,因为它是主动学习的一种形式。
主动计划的世界模型包括两个部分:(1)用户目标抽样模块,在对话开始时对正确的用户目标进行抽样; (2)响应生成模块,它模仿真实用户与代理的交互以针对每次对话生成用户动作,奖励和用户是否终止对话的决定。
- Active user goal sampling module.假设我们已经从人与人之间的对话数据中收集了大量用户目标。这些用户目标可以分为不同的类别,每个类别都有不同的约束,构成不同程度的困难。关键的观察是,在培训过程中,在监控代理策略对验证集的执行情况的同时,我们可以收集有关每种用户目标类别对用户性能改善的影响的详细信息。对话代理,例如,根据成功率(算法1中的第13行)。所获得的信息可用于衡量主动学习环境中的成本(或收益)(Russo等人,2018年; Auer,Cesa-Bianchi和Fischer,2002年),并指导世界模型如何对用户目标进行抽样。
假设有个不同类别的用户目标。在每个时期,在验证集上估计的每个类别的故障率被表示为,并且用于估计的样本数是。为简单起见,将的求和表示为。然后,活动采样例程(算法1中的第6行)可以扩展为这里,是用于引入随机性的高斯分布。汤普森样抽样(Russo et al.。2018)算法2的子例程受到两个观察结果的推动:(1)平均而言,故障率较大的类别更可取,因为它们基于代理策略的当前性能注入更困难的情况(包含更多要学习的有用信息)。
生成的数据(模拟经验)通常与最快的学习方向相关,可以前瞻性地提高训练速度;(2)估计不太可靠的类别(由于值较小)可能具有较大的实际失败率,因此值得分配更多的训练实例以减少不确定性。是的不确定性的度量,在高斯中起到方差的作用。
因此,即使失败率很小,仍有可能选择具有高不确定性的类别。
- Response generation module. 我们在Peng等人(2018)中使用了与世界模型相同的设计。具体来说,我们使用多任务深度神经网络对其进行参数化(Liu等人,2015)。每次世界模型观察到对话状态和来自代理的最后一个动作时,它都会通过 使输入对生成用户动作,奖励二进制终止指示符信号。 在第一层(称为层)中有一个共享表示。每项计算显示如下:
3.3 Switcher
在培训的每个步骤中,切换者都需要决定是否应使用模拟或真实经验来培训对话代理(算法1中的8-9行)。
切换器基于使用长短期记忆(LSTM)模型实现的二进制分类器(Hochreiter和Schmidhuber 1997)。假设对话表示为一系列对话转弯,由{(si,ai,ri)}表示,i = 1,...,N,其中N是对话的对话转弯数。 Q学习采用(s,a,r,s')形式的元组作为训练样本,可以从对话中两个连续的对话回合中提取。现在,切换台的设计选择是分类器是基于回合还是基于对话。为了提高数据效率,我们选择了前者,尽管有点违反直觉。匝数比对数大一个数量级。结果,与基于对话的分类器相比,可以更可靠地训练基于回合的分类器。然后,给定一个对话,我们对它的每个对话转弯的质量进行评分,然后对这些得分取平均值,以测量对话的质量(算法1中的第6行)。如果对话级别分数低于某个阈值,则代理将切换为与真实用户进行交互。
请注意,每次对话回合都是通过在同一对话框中考虑之前的回合来计分的。给定对话回合及其历史我们使用LSTM使用隐藏状态向量对进行编码,然后通过型层输出回合质量得分:
由于我们分别将用户体验和模拟体验存储在缓冲区和中(算法1中的第4、7行),因此的训练遵循与最小化交叉熵损失相同的过程。使用小批次的常见领域对抗训练设置(Ganin等,2016):
由于在对话训练过程中和中存储的经验会发生变化,因此switcher(切换器)的评分功能会相应更新,从而自动调整在训练的不同阶段要执行多少计划。
4. 实验与结果
我们在电影票预订域中以两种设置评估拟议的框架:模拟和人工评估。
4.1 Dataset
对于实验,我们使用电影票预订数据集,其中包含通过Amazon Mechanical Turk收集的原始会话数据。基于域专家定义的架构手动标记数据集。如表1所示,注释架构包含11个意图和16个插槽。数据集总共包含280个标记为对话的对话,平均长度为11轮。

4.2 Baseline
我们将代理的有效性与几个基准进行了比较:
DQN代理仅在每个训练时期都通过直接强化学习来实现(算法1中没有5-9行)。DQN(K)的真实体验是DQN代理的倍(算法1中的3-4行重复K倍)。 的性能可以看作是的上限,具有相同数量的计划步骤(它们在训练期间具有相同的训练设置和相同数量的训练样本)整个学习过程)。DDQ(K)代理是使用从人类对话数据启动的联合训练的世界模型学习的,其中包含个规划步骤(用个循环替换算法1中的第5-9行) )。提出的代理程序已按照算法1中的描述进行了更新。请注意,代理程序中没有参数,因为实际/模拟比率由switcher
(切换器)模块自动控制。
4.3 Implementation Details
Agent and Hyper-parameter Settings.我们使用在所有代理变量(DQN,DDQ和Switch-DDQ)中参数化函数。MLP具有一层ReLU激活功能的80个神经元的隐藏层(Nair和Hinton 2010)。采用贪心策略来探索行动空间。将来奖励的折扣系数设置为0.9。对于DDQ(K),由于每个时期的实际和模拟体验的数量不同,因此和的缓冲区大小通常分别设置为2000和2000×K。对于Switch-DDQ,我们观察到结果与的缓冲区大小无关,因此我们将所有的大小设置为2000×5。我们在所有神经网络中随机初始化参数,并在开始时清空两个体验缓冲区和。RMSProp(Hinton,Srivastava和Swersky 2012)算法用于对学习率设置为0.001的所有参数进行优化。我们还将梯度裁剪技巧应用于最大范数为1的所有参数,以防止可能出现的梯度爆炸问题。在每个时期的开始(算法1中的第2行),参考副本被更新。每个模拟对话包含少于40个回合。超过最大转数的会话被视为失败。为了更有效地训练智能体,我们在初始阶段就采用了称为“回复缓冲加标”(RBS)的模仿学习方法(Lipton等人,2016),以从人类对话数据中训练出的基于规则的简单智能体为基础。然后,在训练代理的所有变体之前,使用受过训练的代理来向真实体验重播缓冲区填充总共50个完整的对话。World Model.我们为和采用MLP世界模型。共享的隐藏层设置为具有双曲正切激活的尺寸160。状态和动作输入通过大小为80的线性层进行编码。在计算高斯方差时(算法2的第2行),我们将每个预先填充为5,以防止被0除的错误。Switcher.LSTM切换器具有126个单元的隐藏层。与世界模型相似,状态和动作在每个时间步长都通过大小为80的线性层作为输入。切换器采用退火阈值决定每次对话的质量的时期号。如果平均对话插曲分数超过某个阈值,则所有高质量的预测将被推入缓冲区中。
4.4 Simulation Evaluation
我们通过模拟座席和编程良好的用户模拟器(而不是真实用户)之间的交互来训练对话座席。也就是说,我们训练世界模型来模仿用户模拟器的行为。
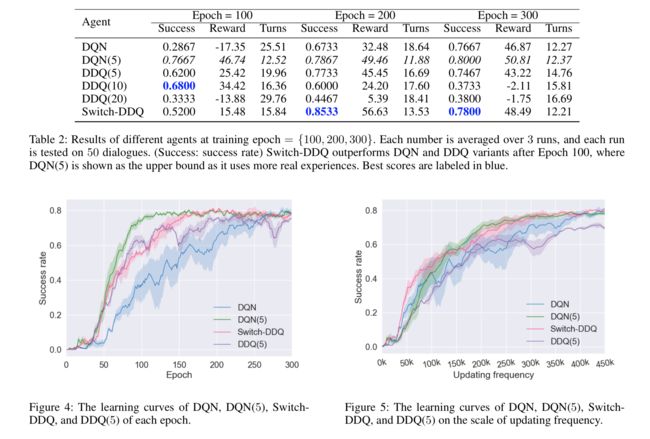
User Simulator.我们在模拟评估中使用了开源的面向任务的用户模拟器(Li等,2016)。在每次对话时,模拟器都会向座席发出模拟的用户响应。对话结束时,将提供奖励信号。当且仅当成功预订了电影票并且代理提供的信息符合采样的用户目标中的所有约束位置时,该对话才被认为是成功的。每个完成的对话框显示对成功的正向奖励,对于失败则显示负向奖励,其中是每个对话的最大转数,在我们的实验中设置为40。此外,在每一回合中,负奖励-1被提供以鼓励较短的对话。Main Results.我们总结了表2中的主要结果,并在图4中绘制了学习曲线。如图2所示,对参数非常敏感。因此,在下图中,我们只保留性能最佳的作为基线。为此,使用了比实际用户体验多4倍的实际用户体验,是相应方法的上限。在表2中,我们报告了每个代理在3个不同运行期间的成功率、平均奖励和平均周转次数。如图所示,的代理在前100个历元之后,始终以较少的相互作用回合数实现较高的成功率。同样,和在训练过程中迅速恶化。在图4中,我们可以观察到,在前130个时期,的性能略好于。然而,在此之后,超过了,并且获得了更好的性能。它只需要 180个历元就可以达到与相当的结果,利用的实际经验比多4倍,而无法在300个历元内达到类似的性能。这是预期的,因为所采用的积极模拟器采样策略虽然在训练的早期阶段帮助更快地更新策略网络,但由于在后期阶段使用低质量的训练实例而损害了性能。注意,除了外,所有的代理在每个时代都使用相同数量的真实经验进行培训,唯一的区别是使用的模拟经验的数量(用于规划)和这些模拟经验是如何产生的(通过主动学习或不通过主动学习)。结果表明,可以比更有效、更健壮地利用模拟器。
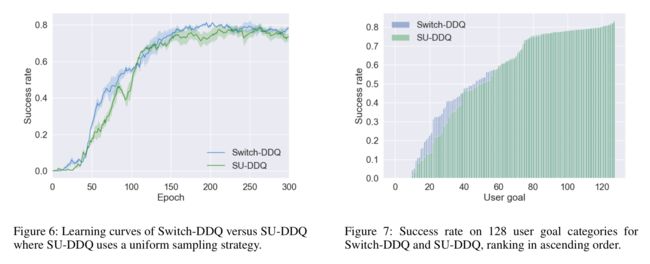
我们还检查了具有相同数量的优化操作的不同代理的性能。如图5所示,我们将成功率绘制为更新频率的函数,即总共使用了多少对话体验(真实的或模拟的)来优化代理策略网络。请注意,表现出优于的性能,因为它以相同的更新频率生成更多不同的对话(可能更频繁地指相同的体验,因为中的刷新频率低于中的)。此外,我们观察到,由于使用了许多低质量的模拟经验,无法获得与类似的性能。然而,这在中不会发生,因为它通过进行多样化的训练对话并通过谨慎地控制模拟体验的数量来主动采样用户目标。Ablation Test.为了进一步检验主动学习模块的有效性,我们通过将用户目标选择例程(算法2)替换为基于均匀采样的例程(称为)来进行消融测试。图6中的结果表明,可以始终优于,特别是在早期阶段(Epoch100之前)。这是因为代理在早期阶段对用户目标的多样性更敏感,因为在有限的数据设置中,许多重复的情况更容易引入偏差。在图7中,我们报告了不同类别的用户目标的成功率,并按递增顺序对其进行排序。可以观察到,对于相应的用户目标类别排名,特别是成功率较低的用户目标类别,的主动版本总是给出较好的分数。这些结果表明,主动模块的使用提高了培训效率。
4.5 Human Evaluation
真实用户被招募来与不同的代理进行交互,而代理系统的身份对用户是隐藏的。
在对话会话开始时,向用户提供随机采样的用户目标,并随机选择其中一个代理与用户交谈。
如果用户发现对话进行了如此多次的轮换,以致不太可能达到有希望的结果,则可以在任何时候终止对话会话。这样的对话在我们的实验中被认为是失败的。
选择三个代理(,和),如前所述(图4)在时期150处训练,用于人工评估。3如图8所示,人工评估的结果与模拟评估中的结果一致。
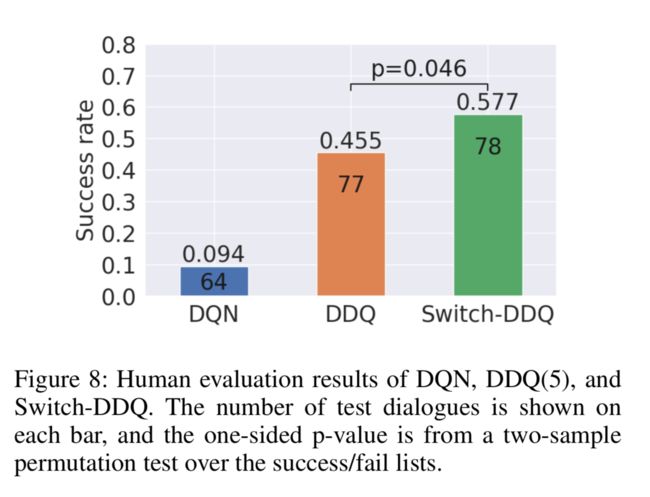
我们发现更多地被用户抛弃,因为它花费了太多的对话轮次(表2),导致了非常严重的性能下降,并且所提出的的性能优于所有其他代理。
5. 结论
提出了一种新的基于的任务完成对话策略学习框架。
通过引入切换器,能够自适应地从真实用户或世界模型中选择合适的数据源,提高对话策略学习的效率和鲁棒性。
此外,主动用户目标采样策略提供了比以前的更好的对世界模型的利用,并提高了训练的性能。
通过模拟实验和人工评估来验证在电影票预订任务中的有效性,我们表明代理的性能优于其他最先进的方法训练的代理,包括和。
可以被视为一种通用的基于模型的方法,并且很容易扩展到其他问题。
6. 重点论文
- [Sutton 1990] Sutton, R. S. 1990. Integrated architectures for learning, planning, and reacting based on approximating dynamic programming. In Machine Learning Proceedings 1990. Elsevier. 216–224.
- [Su et al. 2018] Su, S.-Y.; Li, X.; Gao, J.; Liu, J.; and Chen, Y.-N. 2018. Discriminative deep dyna-q: Ro- bust planning for dialogue policy learning. arXiv preprint arXiv:1808.09442.
- [Hakkani-Tu ̈r et al. 2016] Hakkani-Tu ̈r, D.; Tu ̈r, G.; Celiky- ilmaz, A.; Chen, Y.-N.; Gao, J.; Deng, L.; and Wang, Y.-Y. 2016. Multi-domain joint semantic frame parsing using bi- directional rnn-lstm. In Interspeech, 715–719.
- [Mrksˇic ́ et al. 2016] Mrksˇic ́, N.; Se ́aghdha, D. O.; Wen, T.- H.; Thomson, B.; and Young, S. 2016. Neural belief tracker: Data-driven dialogue state tracking. arXiv preprint arXiv:1606.03777.
- [Wen et al. 2015] Wen, T.-H.; Gasic, M.; Mrksic, N.; Su, P.- H.; Vandyke, D.; and Young, S. 2015. Semantically con- ditioned lstm-based natural language generation for spoken dialogue systems. arXiv preprint arXiv:1508.01745.
- [Mnih et al. 2015] Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A. A.; Veness, J.; Bellemare, M. G.; Graves, A.; Ried- miller, M. A.; Fidjeland, A.; Ostrovski, G.; Petersen, S.; Beattie, C.; Sadik, A.; Antonoglou, I.; King, H.; Kumaran, D.; Wierstra, D.; Legg, S.; and Hassabis, D. 2015. Human- level control through deep reinforcement learning. Nature 518(7540):529–533.
7. 代码编写
本文相关链接:https://github.com/CrickWu/Switch-DDQ
# 后续追加代码分析
参考文献
- Wu, Y., Li, X., Liu, J., Gao, J., & Yang, Y. (2019). Switch-Based Active Deep Dyna-Q - Efficient Adaptive Planning for Task-Completion Dialogue Policy Learning. Aaai.