原文在此:【0基础】纵横中文网python爬虫实战
大家好,我是你们的机房老哥!
在粉丝群的日常交流中,爬虫是比较常见的话题。python最强大的功能之一也是爬虫。
考虑到很多0基础的小白想要入门爬虫。老哥今天就通过一个比较简单的爬虫,介绍一下python爬虫的流程及思路,并扫盲爬虫常用工具的语法。
本次教程您将学到:
爬虫思路、流程
xpath全解析
css选择器全解析
requests_html库进阶
话不多说,接下来就是:
-STUDY PYTHON WITH-
基础教程——纵横中文python爬虫
-OLDER BROTHER-
获取小说信息
http://book.zongheng.com/store.html
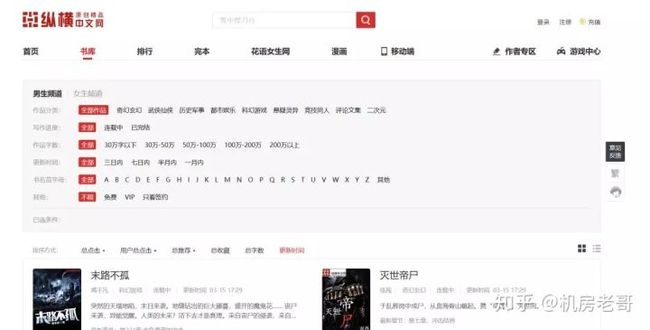
要爬取的网址如上图所示。
导入老哥最常用的爬虫库requests_html库,首先将HTMLSession()函数定义为session。使用session.get()命令提交响应,最后打印r.html.html查看网页源代码。
```
from requests_html import HTMLSession
session = HTMLSession()
url = 'http://book.zongheng.com/store.html'
r = session.get(url)print(r.html.html)
```
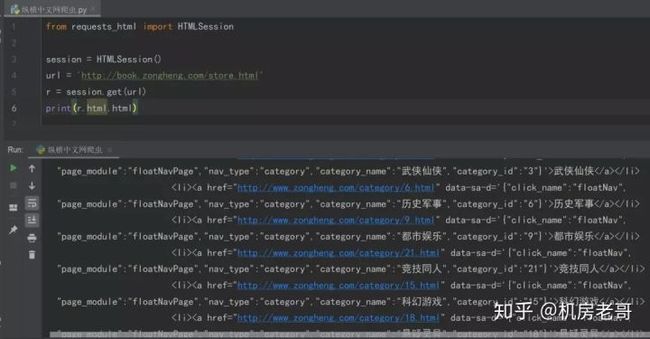
如上图所示,老哥已经成功获得网页源码了。说明网站的反爬手段比较弱,适合新手练习。
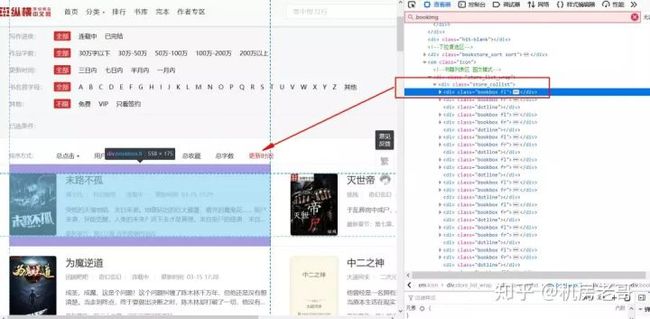
按F12打开控制台,可以看到左侧小说的信息在
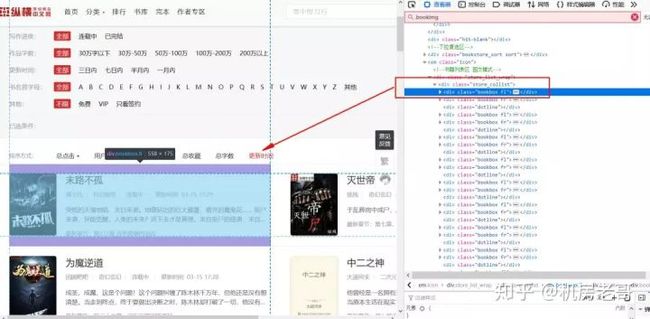
我们点入每个小说信息的div下,获取小说的信息。
可以看到,
接下来通过xpath分别提取这些信息,代码如下:
```
bookname = r.html.xpath('//div[@class="bookname"]/a/text()')
bookname_links = r.html.xpath('//div[@class="bookname"]/a/@href')
authorname = r.html.xpath('//div[@class="bookilnk"]/a/text()')
author_links = r.html.xpath('//div[@class="bookilnk"]/a/@href')
typename = r.html.xpath('//div[@class="bookilnk"]/a[2]/text()')
type_links = r.html.xpath('//div[@class="bookilnk"]/a[2]/@href')
status = r.html.xpath('//div[@class="bookilnk"]/span/text()')
time_ = r.html.xpath('//div[@class="bookilnk"]/span[2]/text()')
for num in range(len(bookname_links)):
print(bookname[num], bookname_links[num], authorname[num], author_links[num], typename[num], type_links[num],
status[num].strip(), time_[num].strip())
```
解析上述代码:通过r.html.xpath调用库中自带的xpath语法提取小说名。//div代表任意位置的div标签,[@class="bookname"]是xpath语法,中括号中@符号后是div的属性,这里用div的标签class="bookname"定位到小说名称。/a代表这个div下的第一个a标签,最后用text()函数提取a标签内容,即小说标题。
提取网址方法类似,区别在于在a标签后接/@href提取a标签下的href属性。
当一个div标签下有两个a标签时,a[2]代表第二个a标签。

这里顺便扫盲一下xpath的基础语法:
详解xpath
选取节点:
xpath('/div')——从根节点上选取div节点。
xpath('//div')——选取所有div节点。
xpath('./div')——选取当前节点下的div节点。
xpath('../a')——选取当前的父节点下的第一个a节点。
谓语:
xpath('/body/div[1]') ——选取body下的第一个div节点。
xpath('/body/div[last()]')——选取body下的最后一个div节点。
xpath('/body/div[last()-1]')——选取body下的倒数第2个div节点。
xpath('/body/div[positon()<3]')——选取body下的前2个div节点。
xpath('/body/div[@class]')——选取body下带有class属性的div节点。
xpath('/body/div[@class="main"]')——选取body下class属性为main的div节点。
xpath('/body/div[price>35.00]')——选取body下price元素值大于35的div节点。
xpath('/div/*')——选取div下的所有子节点。
xpath('/div[@*]')——选取所有带属性的div节点。
xpath('/div/node()')——匹配div下任何类型的节点。
xpath('//div|//table')——选择所有div和table节点。
功能函数:
xpath('//div[starts-with(@id,"ma")]')——选取id值以ma开头的div节点。
xpath('//div[contains(@id,"ma")]')——选取id值包含ma的div节点。
xpath('//div[contains(@id,"ma") and contains(@id,"in")]')——选取id值包含ma和in的div节点。
xpath('//div[contains(text(),"ma")]')——选取文本中包含ma的节点。
在这里老哥在稍微拓展一下。获得小说链接,除了上文中的方式,还可以用如下代码:
bookname_links = r.html.xpath('//div[@class="bookname"]/a', first=True)
print(bookname_links.attrs['href'])
解析一下上述代码,使用first=True提取div下的第一个a标签。在这里用.attrs['href']命令提取a标签下的href属性,同样可以得到链接。
值得注意的是,first=True提取的是第一个标签,返回element格式。如果不加,则返回列表格式,就不能使用该方法了。
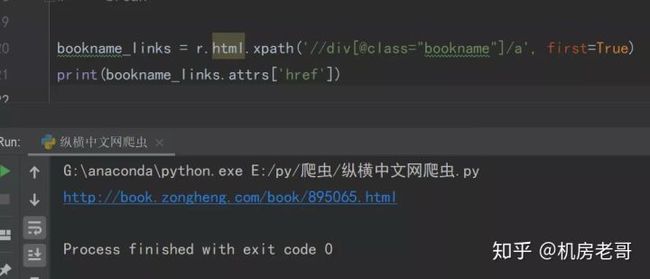
进入小说内容页
上文中已经提取到小说的链接,我们只需要再次用session.get()命令请求这个链接,即可得到小说内容。
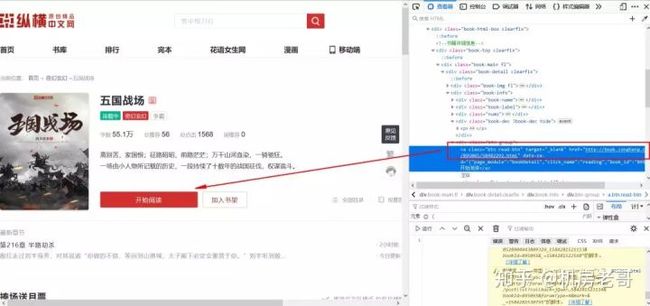
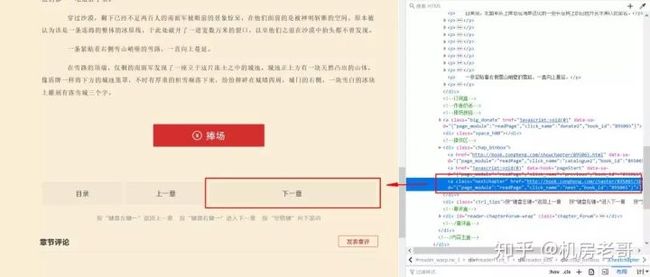
不过,上文中提出的链接点进去是小说详情页,所以想要获取小说内容,还需要提取“开始阅读”对应的href链接。代码如下:
```
bookname_links = r.html.xpath('//div[@class="bookname"]/a/@href')
for num in range(len(bookname_links)):
bookname_link = bookname_links[num]
r = session.get(bookname_link)
r2 = r.html.xpath('//div[contains(@class,"btn-group")]/child::a')[0].links
print(r2)
```
解析上述代码:老哥为了拓展教程,用了第三种方式提取链接。首先解析xpath语法,//div[contains(@class,"btn-group")],代表获取包含"btn-group"的class属性的div节点。这种方式的好处在于,假如该div节点的class有很多,写起来比较复杂,就可以用contains获取该class中包含的某个唯一字段。/child::a代表该div下的第一个子节点a。
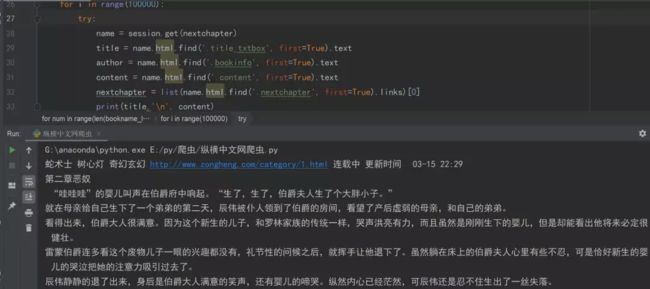
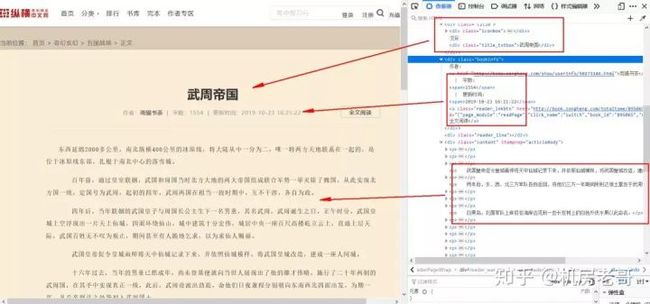
由于这种方式得到的是一个列表,提取列表的第一个值,该值包含小说链接。这个值是 'requests_html.Element'>类型,这种类型是requests_html库自带的类型,可以使用.links命令提取该requests_html.Element下的所有链接。因为本案例只有一个链接,所以就返回一个值,即小说的链接。 上述代码中的r2即小说内容页的链接。 进阶:requests_html的.links命令 为了更好的理解.links命令的强大之处,老哥附带一个小案例。例如用.links命令提取根网站下的所有网址,代码如下: ``` from requests_html import HTMLSession session = HTMLSession() url = 'http://book.zongheng.com/store.html' r = session.get(url) print(r.html.links) ``` 可以看到,如果请求的网址下有很多网址,用.links命令可以不费吹灰之力的得到他们。 有时一些链接只有后半部分,需要拼接网站的域名才能使用,这时候,只需要将.links改成.absolute_links,即可获得自动补全的所有链接。 小说内容提取 最后一步就是小说内容提取,方法和上文类似,就不赘述了。这个网站有趣的地方在于禁止左键、右键点击。如果不会爬虫,只会复制粘贴网页信息的话,就会被难住了。当然用爬虫就完全无视这种“小伎俩”啦。 这部分和上文类似,解析标题、内容所在位置,为了拓展教程,老哥这里使用css选择器。代码如下: ``` r3 = session.get(list(r2)[0]) title = r3.html.find('.title_txtbox', first=True).text author = r3.html.find('.bookinfo', first=True).text content = r3.html.find('.content', first=True).text ``` 解析上述代码,r3.html.find()代表使用css选择器。.title_txtbox代表选择class为title_txtbox的值,.是css选择器中选择class类型的符号。最后用.text命令获取内容,类似.links命令。 扫盲一下css选择器的基础语法: 详解CSS选择器 .intro——选择class="intro"的所有元素。 #firstname——选择id="firstname"的所有元素。 *——选择所有元素。 p——选择所有 元素。 div,p——选择所有 元素。 divp——选择 元素。 div>p——选择父元素为 元素。 div+p——选择紧接在 元素。 [target]——选择带有target属性所有元素。 [target=_blank]——选择target="_blank"的所有元素。 [title~=flower]——选择title属性包含单词"flower"的所有元素。 [lang|=en]——选择lang属性值以"en"开头的所有元素。 a:link——选择所有未被访问的链接。 a:visited——选择所有已被访问的链接。 a:active——选择活动链接。 a:hover——选择鼠标指针位于其上的链接。 input:focus——选择获得焦点的input元素。 p:first-letter——选择每个 元素的首字母。 p:first-line——选择每个 元素的首行。 p:first-child——选择属于父元素的第一个子元素的每个 元素。 p:before——在每个 元素的内容之前插入内容。 p:after——在每个 元素的内容之后插入内容。 p:lang(it)——选择带有以"it"开头的lang属性值的每个 元素。 p~ul——选择前面有 元素的每个 a[src^="https"]——选择其src属性值以"https"开头的每个元素。 a[src$=".pdf"]——选择其src属性以".pdf"结尾的所有元素。 a[src*="abc"]——选择其src属性中包含"abc"子串的每个元素。 p:first-of-type——选择属于其父元素的首个 元素的每个 元素。 p:last-of-type——选择属于其父元素的最后 元素的每个 元素。 p:only-of-type——选择属于其父元素唯一的 元素的每个 元素。 p:only-child——选择属于其父元素的唯一子元素的每个 元素。 p:nth-child(2)——选择属于其父元素的第二个子元素的每个 元素。 p:nth-last-child(2)——同上,从最后一个子元素开始计数。 p:nth-of-type(2)——选择属于其父元素第二个 元素的每个 元素。 p:nth-last-of-type(2)——同上,但是从最后一个子元素开始计数。 p:last-child——选择属于其父元素最后一个子元素每个 元素。 :root——选择文档的根元素。 p:empty——选择没有子元素的每个 元素(包括文本节点)。 #news:target——选择当前活动的#news元素。 input:enabled——选择每个启用的元素。 input:disabled——选择每个禁用的元素 input:checked——选择每个被选中的元素。 :not(p)——选择非 元素的每个元素。 ::selection——选择被用户选取的元素部分。 翻页 这里涉及到翻页,因为小说只有下一页,没有具体页数,所以只能循环读取下一页来不停的获取小说内容。 ``` nextchapter = list(r3.html.find('.nextchapter', first=True).links)[0] ``` 获取到下一页网址后,写一个循环来获取下一页,直到无法获取,则爬取完一本小说的所有内容。 ``` for i in range(100000): try: name = session.get(nextchapter) title = name.html.find('.title_txtbox', first=True).text author = name.html.find('.bookinfo', first=True).text content = name.html.find('.content', first=True).text nextchapter = list(name.html.find('.nextchapter', first=True).links)[0] print(title,'\n', content) except: break ``` 解析上述代码,设定一个极大的值,让程序不断循环,获取每页的小说,直到最后一页,无法获取小说内容时,break跳出循环,并开启一本新的小说的爬取。 欣赏一下最终的成果吧! 这样一个基础爬虫教程就结束了,是不是很简单呢! 本次教程的源代码,在公众号后台回复“小说爬虫”即可获取
元素。