Asterisk现有版本不支持播放视频文件(支持视频通话),无法满足发送视频通知、视频IVR等场景。本系列文章,通过学习音视频的相关知识和工具,尝试实现一个通过Asterisk播放mp4视频文件的应用。
- Asterisk播放mp4(1)——音频和PCM编码
- Asterisk播放mp4(2)——音频封装
- Asterisk播放mp4(3)——搭建开发环境
- Asterisk播放mp4(4)——H264&AAC
- Asterisk播放mp4(5)——MP4文件解析
- Asterisk播放mp4(6)——音视频同步
- Asterisk播放mp4(7)——DTMF
本文分为四个部分:音频基本概念,PCM编码格式介绍,PCM A-law编码格式介绍,制作测试样本。
音频基本概念

我们听到的声音是由频率(是什么)和强度(有多响)决定的。上图是一个正弦函数生成的音频,频率是441Hz,采样率是44.1kHz,采样(sample)的最大值是4095。声音的频率就是一个完整的波形没秒钟重复的次数,采样率(sample_rate)是每秒钟收集多少次声音的强度数据,这样每个完整的波形包含100个采样。
上面这个图是个单声道(channel)的音频,实际的音频很多都是多声道的。当有多个声道时,需要定义每个声道中的采样用什么方式进行排列,例如:双声道的时,可以LRLR...,也可以LL...,RR...。(这个问题会在后续讲容器的文章中在详细说明)
每个采样(sample)代表了声音的强度,但它这并不是个绝对的声音大小,只是相对的。因为,同样的声音文件通过不同的设备播放,声音的大小显然不同,这个和播放设备提供的能量有关。声音的绝对大小用分贝(dB)度量,采样只是和分贝的相对关系。
PCM编码
PCM(Pulse Code Modulation,脉冲编码调制)是对声音的振幅(音量的大小)进行编码,位深度为14bit,20bit,24bit等(用多少个二进制位表示)。通过每秒钟记录若干次振幅的值(采样率,8k,44.1k,48k等),把声音的波形记录下来(频率)。
计算机系统中8个二进制位对应1个字节,所以实际表示一个采样时,需要用1个,2个或4个字节进行表示;每个字节又可采用有符号或无符号的方式。当用多个字节表示一个采样时,又存在字节序的问题,就是前面的字节表示的高位还是低位,分为大字节序(big-endian,将高序字节存储在起始地址)和小字节序(little-endian,将低序字节存储在起始地址)。这样就会产生 很多编码的组合,下面是ffmpeg支持的pcm采样格式(也可以通过命令行ffmpeg -formats | grep PCM查看)。
enum AVSampleFormat {
AV_SAMPLE_FMT_NONE = -1,
AV_SAMPLE_FMT_U8, ///< unsigned 8 bits
AV_SAMPLE_FMT_S16, ///< signed 16 bits
AV_SAMPLE_FMT_S32, ///< signed 32 bits
AV_SAMPLE_FMT_FLT, ///< float
AV_SAMPLE_FMT_DBL, ///< double
AV_SAMPLE_FMT_U8P, ///< unsigned 8 bits, planar
AV_SAMPLE_FMT_S16P, ///< signed 16 bits, planar
AV_SAMPLE_FMT_S32P, ///< signed 32 bits, planar
AV_SAMPLE_FMT_FLTP, ///< float, planar
AV_SAMPLE_FMT_DBLP, ///< double, planar
AV_SAMPLE_FMT_S64, ///< signed 64 bits
AV_SAMPLE_FMT_S64P, ///< signed 64 bits, planar
AV_SAMPLE_FMT_NB ///< Number of sample formats. DO NOT USE if linking dynamically
};
PCM A-law编码
PCM本身是一种无损(lossless)编码格式(我理解无损的含义是收集到什么就记录什么,不同格式间的差别在于记录的精度,并不因为方式产生的损失)。但是在电话系统中为了更有效地传递数据,提出了PCM A-alaw和PCM mu-law两种编码格式,其思路是将原始的PCM编码, 压缩成8位的编码(具体的算法不展开了,可以参考g711原理pcm转alaw,pcm转ulaw,alaw转pcm,ulaw转pcm)。
alaw是将13位的有符号数压缩为8位的有符号数,是有损编码(压缩),编码后的数据通过解码无法恢复到原状,数值越大的采样损失的数据就越多。(这里有个疑问,在系统中是用16位保存一个样本的,那是否又有3位数据丢掉了?)
alaw只定义了采样的编解码方法,但是实际使用中还要注意采样率的问题,通常mp3,mp4这些音视频文件中的采样率为44.1k或48k,而电话系统中的采样率为8k,那么从高采样率到低采样率,必然又会产生损失。
制作样本数据

上图是实现Asterisk播放mp4文件的简要流程,中间涉及到音频的编解码过程,其中任何一个环节(出现错误或者因为编解码带来损失)都可能导致最终听到的声音有问题(失真,噪音等)。我们必须找到一种方法验证在各个环节是否运行正确,例如;采样率,采样位深度等等。我采用的方法是通过ffmpeg这个工具生成测试数据,并按照各个环节产生的编码格式生成对应的参照数据,然后比较在各个环节实际产生的数据是否正确。
pcm_s16le
通常mp4文件中的音频解码出的裸流是pcm_s16le(有符号,2字节,小字节序),那么我们先生成一个该格式的10秒钟的裸流。
ffmpeg -lavfi sine -t 10 -f s16le -c:a pcm_s16le sine-10s.s16le

ffmpeg告诉我们生成的文件的编码格式pcm_s16le,采样率是44100,单声道mono。通过查看源码(libavfilter/asrc_sine.c)可以知道:1、正弦波的频率是441Hz,那么每周期包含100个采样(44100/441),这个有助于我们理解生成的数据的变化规律;2、采样的最大值等于4095(0xfff),并不是有符号16位数的最大值32767(0x8000),这个最大值正好是12bit,加上1位符号位是13,正好和alaw将13位有符号数转为8位对应上了。
生成文件的大小是882000字节,44100个采样/秒 * 10秒 * 2字节/采样。
读取生成文件的前200个采样(400个字节)生成图形如下:

按16进制格式打开文件(vi sine-10s.s16le,打开后:%!xxd),查看数据:
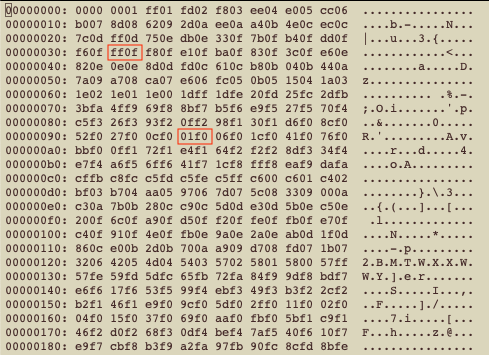
可以看到在第26个采样达到最大值ff0f,第76个采样达到最小值01f0。因为是小字节序,要调换字节顺序,所以最大值对应的是0x0fff(4095),最小值对应的是0xf001(-4095)。
用上面的ffmpeg命令生成一段10秒钟的pcm_s16le格式音频文件(裸流,没有进行封装)。我们既可以用耳朵听,也可以用眼睛看这个音频。
alaw
下面我们把同样的声音做alaw编码。
ffmpeg -lavfi sine -t 10 -f alaw -c:a pcm_alaw sine-10s.alaw

生成文件的大小441000,44100个采样/秒 * 10秒 * 2字节/采样。
读取生成文件的前200个采样(200个)字节,生成图形:

alaw采样的符号位和原始pcm数据符号位是相反的,所以波峰和波谷和s16le是相反的;因为数据进行了编码压缩,所以编码后的数据并不能体现出原始波形,但是频率并没有发生改变。
直接打开文件查看数据:

可以看到在波峰波谷位置数据的差异变小了。
如果需要设置采样率(默认是44.1k),例如:8k,可以通过ar参数实现。
ffmpeg -lavfi sine -t 10 -ar 8000 -f alaw -c:a pcm_alaw sine-8k-10s.alaw
alaw 转 s16le
alaw是一种压缩格式,需要解压缩才能播放,按alaw算法解码出来的采样时13位有符号数,对应的存储格式就是pcm_s16le,所以我们看看alaw转s16le会是什么样?
ffmpeg -f alaw -i sine-10s.alaw -f s16le -c:a pcm_s16le sine-alaw2s16le-10s.s16le
这次是用之前生成好的alaw文件作为输入。

取前200个样本生成图形。

从图形上可以看到整体波形并没有发生改变,但是在波峰波谷的位置存在失真,这表明alaw的编解码过程带来了损失。

查看原始数据我们也可以看到已经和原始s16le数据不同,数据精度下降了。
其他
其他ffmpeg命令
生成一段空白10秒裸流,采样全是0。
ffmpeg -lavfi anullsrc=r=44100:cl=mono -t 10 -f s16le -c:a pcm_s16le null-10s.raw
生成一段指定内容的裸流(并不能设定为特定值,如果指定的是0,输出的是0,否则是最大值)。
ffmpeg -lavfi aevalsrc=1 -t 1 -f s16le -c:a pcm_s16le eval-1s.raw
采样的数值含义
执行如下命令,可以查看音频文件的音量:
ffmpeg -i sine-10s.wav -filter:a volumedetect -f null /dev/null
获得输出内容:
n_samples: 441000
mean_volume: -21.1 dB
max_volume: -18.1 dB
histogram_18db: 128000
看这个数据仍然不太明白音量到底是什么,通过看源码,形成大体上的理解,0dB被当作音量的极大值,对应16位有符号数的最大值就是32767(0x8000),等于91dB的音量。(目前并不确切知道为什么选91分贝这个值,似乎是再高的值人就受不了。)
#define AMPLITUDE 4095 // 4095 0x0fff 是12bit的最大值(无符号)
#define MAX_DB 91
// 0x0fff 4095
// 0x8000 32767
4095/32767 = 0.1249733
db = 20 * log10(0.1249733) = -18.1
参考
参考:http://ffmpeg.org/ffmpeg-filters.html#anullsrc
参考:http://ffmpeg.org/ffmpeg-filters.html#sine
参考:http://ffmpeg.org/ffmpeg-filters.html#aevalsrc
参考:https://trac.ffmpeg.org/wiki/AudioVolume
参考:http://ffmpeg.org/ffmpeg-filters.html#volumedetect
参考:https://stackoverflow.com/questions/2445756/how-can-i-calculate-audio-db-level