1 回顾感知机
废话不多说,就不从什么模拟人类的神经元开始了,在感知机(Perceptron)中我们已经说过:感知机模型是神经网络和支持向量机的基础,现在我们终于讲到神经网络了,先来复习一下作为基础的感知机。
感知机是一个通过分类超平面来对线性可分数据进行二分类的简单模型,可以表示为:
其中,函数是一个阶跃函数(step function),为分类超平面,我们可以以下图来描述一个感知机:

感知机还可以实现简单的布尔运算,比如“and”、“or”、“not”,我们只知道感知机是个线性分类器,怎么还能进行布尔运算呢?看下图相信就可以理解了,与或非运算其实也可以看成线性分类的问题(如下左图),因此可以使用感知机,这同时也是感知机不能进行“异或”运算的原因,“异或”并不是线性可分的(如下右图)。
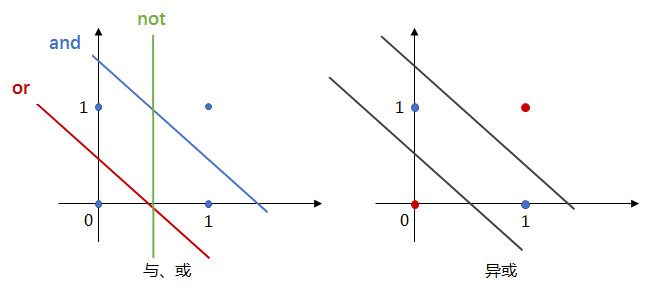
由上图可知,要解决非线性可分的问题,只用一个感知机是不够的,比如异或问题,其实使用三个感知机组成一个两层的模型就可以解决,相当于把非线性的分类边界拆解成了多个线性的分类边界,然后在下一层组合起来:

2 多层感知机、神经网络
综上所述,我们用多个、多层的感知机结构可以逼近非线性函数,所以我们就得到了多层感知机(MLP)的概念,也就是所谓的神经网络,其中一个感知机我们称为一个神经元,一个神经元的结构跟感知机是一样的,不过其激活函数一般是一个非线性函数(原因后文再说),经常使用sigmod函数、tanh函数、relu函数等,如下图所示:

将多个神经元按层次连接,像异或问题的解决方案中那样,本层的输出作为下一层的输入,就得到了一个神经网络,如下图表示一个全连接(full connected, FC)神经网络:

神经网络分为最左边的输入层、中间的隐藏层和最右边的输出层,我们总结一下全连接神经网络的结构规则:
- 同一层的神经元之间没有连接;
- 第N层的每个神经元和第N-1层的所有神经元相连(full connected),第N-1层神经元的输出就是第N层神经元的输入;
- 每个连接都有一个权值。
神经网络本质上就是以这种组合结构来逼近各种复杂的函数,所以其实神经网络也相当于是一个函数:
理论上来说,神经网络可以以任意小误差近似定义在有限维空间的任意连续函数,这是神经网络的普遍性定理,可以简单的理解一下:两个感知机构建的单层网络可以表示一个脉冲函数,通过类似积分的思想,使用很多个脉冲函数来无限逼近任意函数曲线:

注意我们上面说过神经元的激活函数一般是非线性函数,这是为什么呢?因为如果使用线性激活函数或者不使用激活函数,那么无论神经网络有多少层,其实都是一直在做线性运算而已,其组合还是线性函数,是无法近似更复杂的函数的。
3 神经网络的前向计算
前向计算:从网络的输入层开始,依次逐层往前计算,直到计算出输出层的结果,即求的过程。
我们先定义清楚神经网络权重上表示不同层、不同神经元的角标,记为第层第个神经元到第层第个神经元的权重,为第层第个神经元的偏置,为第层第个神经元的输出,如下图中表示第2层的第4个神经元与第3层第2个神经元之间连接的权重。

因此,每层神经元的输出值可表示为:
在实际使用时,为了提高效率,这些计算都是以矩阵形式进行的,上面的计算过程的矩阵形式为:
举个例子,对下图中的三层神经网络,使用矩阵形式来进行前向计算:

下面是矩阵形式前向计算的代码,很简单:
def feedforward(self, a):
for b, w in zip(self.bias, self.weights):
a = self.sigmod(np.dot(w, a) + b)
return a
4 神经网络的训练——反向传播
4.1 为什么要用反向传播
对算法的训练我们都很熟悉,无非就是根据真实y值和预测y值之间的差别来更新算法中的参数,而且我们早就掌握了一个训练神器——梯度下降,那么神经网络的训练是否可以按这个思路走下去呢?
假设代价函数是,目标是,使用梯度下降:
首先我们需要对代价函数进行求偏导,这就产生了第一个困难,不同于传统的机器学习算法,对于神经网络来说,我们并不知道其具体的函数表达式,故无法直接根据损失函数求参数导,不过这难不倒我们,我们可以直接根据导数的定义来进行求导:


我们可以给每个权重一个微小的改变,然后前向计算得到预测y,再得到损失函数的变化量来计算导数,看起来似乎计算简单很可行的样子,然而要注意到,假设有一个 [ 200, 100, 1 ] 的三层全连接网络,那么其参数共个参数,那么需要20201次前向计算才能得到所有参数的偏导数,这可太难了,如果网络复杂的话,一般的计算能力做不到了啊,这就是第二个困难:计算效率,这时候我们需要另一大神器:反向传播。
4.2 反向传播理解与推导
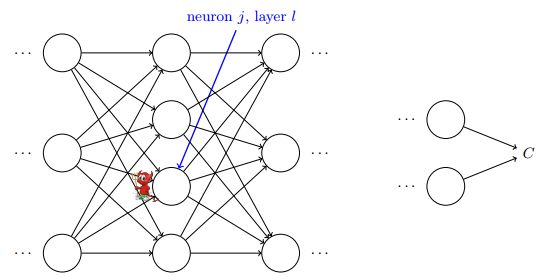
考虑到神经网络的复杂结构,要计算参数对代价函数的偏导数,首先要对参数变化影响代价函数过程有所理解。对于NN的分层结构,每一层可以看做上一层的输出,因此可以认为每层都根据其输出的误差来调整参数,我们引入中间量为神经元的带权输入,这个我们称为在 层第 个神经元上的误差项,是误差的一种度量,代表了代价函数对带权输入的变化率。设想下图中红色的小鬼专门负责调整带权输入,他调整,则代价函数变化,当他选择与相反的方向调整时,代价函数就会不断减小,直到趋近于0,这就是在NN中使用梯度下降的方法,现在我们知道,重点是获得每一层的误差项。(其实误差项定义成对激活值什么的偏导也行,不过使用带权输入比较便于计算)
反向传播给我们提供了计算每层的方法,其基础是导数的链式法则(不懂链式法则的可以看文末的附录),可以把反向传播理解为:像一根链子(或绳子),误差项先在尾部得到,然后沿着链子(或绳子)依次向前传播误差项,就像下图的甩绳一样:

1)输出层的误差项
我们先来计算尾部输出层的误差项,这是反向传播的起点:
这没什么好说的,链式法则而已,其中是激活函数。将其写成矩阵运算的形式:
式中⊙ 为Hadamard积,即矩阵的点积。
2)隐藏层的误差项
误差项传播的起点有了,接下来就要往前(隐藏层)传播了。要注意到,对于一个隐藏层结点,其下游(即下一层与之直接相连的结点)一般会有多个结点,这个隐藏层结点的带权输入的变化会对全部的下游结点产生影响,因此我们定义层第个结点的下游结点集合为,隐藏层误差项的计算如下:
同样可以写成矩阵运算的形式:
3)代价函数对参数的偏导
得到误差项(代价函数对带权输入的偏导)的计算方法,别忘了我们的最终目标:求出代价函数对参数的偏导,使用梯度下降来更新模型参数,下面分别是代价函数对偏置和权重的偏导计算方法:
有了这两个公式,直接代入梯度下降中去就行了,这一步就跟其他算法没什么区别了,不再赘述。
4.3 反向传播python实现
矩阵运算形式的反向传播代码,就是把以上我们推导的四个公式写成代码而已:
def backprop(self, x, y):
b_tmp = [np.zeros(b.shape) for b in self.bias]
w_tmp = [np.zeros(w.shape) for w in self.weights]
# 前向,与feedforward函数的区别是,每一层的输出a和加权输入z需要记录下来
activation = x
activations = [x]
zs = []
for w, b in zip(self.weights, self.bias):
z = np.dot(w, activation) + b
zs.append(z)
activation = self.sigmod(z)
activations.append(activation)
# 后向,根据前向记录的结果得到delta
delta = self.cost_derivative(activations[-1], y) * self.sigmod_derivative(zs[-1])
b_tmp[-1] = delta
w_tmp[-1] = np.dot(delta, activations[-2].transpose()) # activations[-2]层的输出,就是输出层的输入x
# 对np.array各个纬度的转变需要弄清楚
# 接下来对隐含层
for l in range(2, self.layer_count):
z = zs[-l]
delta = np.dot(self.weights[-l + 1].transpose(), delta) * self.sigmod_derivative(z)
b_tmp[-l] = delta
w_tmp[-l] = np.dot(delta, activations[-l - 1].transpose())
return b_tmp, w_tmp
5 总结
本文介绍了神经网络的一些基本概念和原理,神经网络在当下的火爆程度不必多说,反向传播居功甚伟,理解了全连接网络的反向传播,接下来再去理解CNN、RNN等特殊结构的神经网络就容易多了。
附录
导数的链式法则

主要参考
感知机
《Neural Network and Deep Learning》- Michael Nielsen