导读:今天为大家介绍一下OPPO小布助手在对话系统技能平台建设中的落地实践,主要分为四个方面:
- 业务领域建模,建设通用能力地图
- 语义理解能力初探,多类型的场景支持
- 多模式易扩展流程化的对话管理
- 端到端一站式离线平台,看得见的技能生命周期
业务领域建模,建设通用能力地图
1、实现一个智能助手需要什么
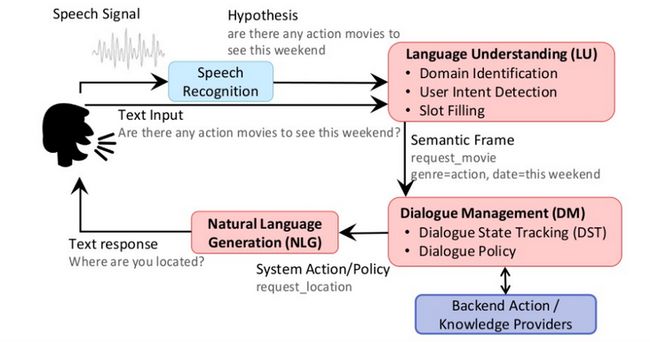
在用户讲了一句话之后,首先我们要做一次语音识别,识别用户真正的query是什么,接下来我们会进行语义理解,识别用户的意图和槽位等等。当我们识别了用户的意图之后,我们会根据用户的上下文去做整个对话的管理,以及明确对话的一些策略。在这个过程中,我们会依赖一些知识来进行整个对话策略的管理。在我们决定要执行什么动作之后,再去生成整个对话。
小布助手是OPPO智能手机和IoT设备内置的智能助手,它是一个多类型融合的对话系统。
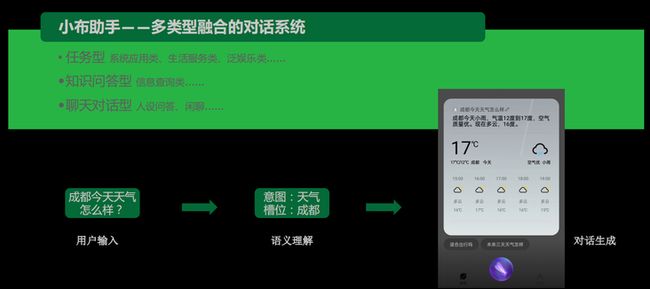
对于任务型的对话,小布助手会去执行一些系统的应用,比如打开APP、听歌等等;对于知识问答型的对话,小布助手将返回用户所查询的信息,比如问北京在哪里,今天星期几等;最后一个是聊天对话型的对话,这一类型主要和闲聊相关。
整个对话系统都是从用户的输入来进行语义理解,最后生成一个卡片去回复用户的信息。当然,我们还有一些不同的入口,可以展示不同的回复。
2、什么是技能平台
我们今天所介绍的技能平台是OPPO小布助手搭建的低代码对话系统管理平台。我们希望能够以零代码或者低代码的方式实现创建技能、配置技能和训练技能,最后进行一些技能的自动上线,再加上技能自动化的迭代,保证整个技能的生命周期都是零代码或者低代码的状态。整个平台需要设计得相对通用,因为会有不同的对话逻辑去复用。扩展性方面,我们需要去支撑多种业务场景,前面提到小布助手是一种多场景的对话系统。除此之外,整个对话平台不光是内部使用,还需要对外部开放,我们要保证整个平台的安全性和稳定性,不对小布助手的主流业务造成影响。
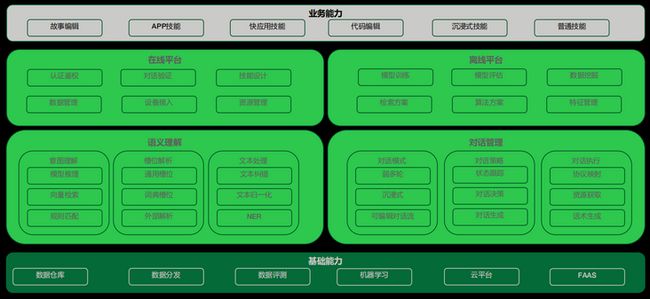
基于前文所述的场景和需要建立的业务能力,我们定义了整个能力地图,在线平台提供数据编辑的能力,离线平台提供模型训练、模型评估的能力,语义理解提供意图理解、槽位解析和通用的一些文本处理,以及对话管理提供支持不同的对话模式、生成对话策略、对话执行的能力。
接下来,我将展开说明我们是怎样去建设每一个能力的。
语义理解能力初探,多类型的场景支持
1、通用化NLU流程
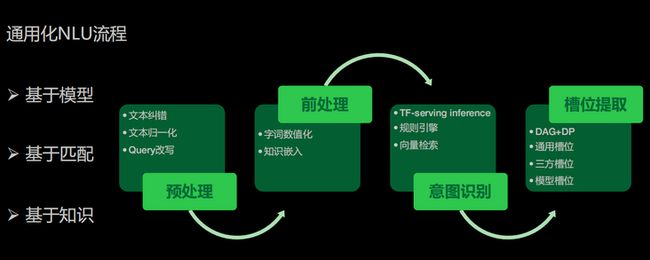
语义理解的能力,本质上是我们怎样以各种方式识别用户想做什么事。在这里,我们定义了一些通用化NLU流程,包括如下三种:
- 基于模型,我们可以将用户的语料自动训练成一个模型,再上传到技能;
- 基于匹配,当用户的语料非常少的时候,我们会推荐他用这种匹配方案去实现一些高精准的匹配;
- 基于知识,对于一些问答类的语料,我们会推荐他用第三种,也就是基于知识的NLU识别。
整个过程分为:预处理,前处理,意图识别和槽位提取。
首先是预处理,主要包含文本纠错、文本归一化和query改写。归一化是比如特殊字符的处理、大小写转换等,有时候语音转换的query不符合用户上下文,我们还需要改写query。
之后是前处理,对于模型,我们需要做数值化,通过数值化进行预测,所以我们会做字向量或词向量的数值化。同时,我们也会嵌入定义好的一些知识,将知识嵌入到模型当中,做一次数值的处理。
前处理完成后,我们会将数值向量传到模型中去做预测。如果不用模型,我们会支持用户编辑一些规则,通过规则引擎实现精准匹配。对于这种匹配,我们还支持向量检索的方式,能够从语义的层面去做一些检索。
当我们识别到用户的意图之后,就需要去做槽位的处理。我们定义了几种槽位,一种是基于词典的槽位提取,我们有自研的DAG+DP的词典提取的方法。同时,我们还定义了几十种通用的槽位,方便外部用户进行常规的槽位提取,不需要提供他自己的词典,比如说提取城市、数字、人名等通用的槽位,只要选择就可以了。我们还会接入一些三方,如果他自己有NLU能力,我们也可以让他接入他自己的三方槽位。部分技能有模型训练的能力,我们也支持他去接入一些模型槽位。
2、基于模型的意图识别
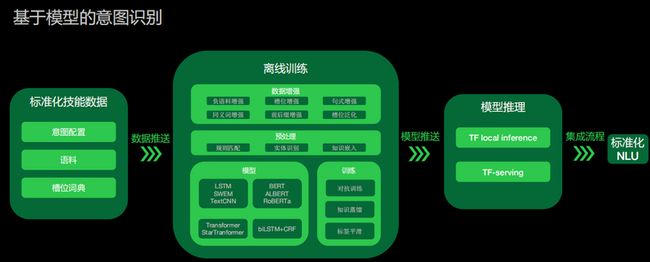
基于模型的意图识别的过程分成为四个步骤。
首先是定一些标准化的技能数据,包括意图配置,比如定义技能可能有三个意图,每个意图会有一些什么样的槽位,对于每个意图它需要去提供标准化的语料,可以提供一些正语料,也可以提供一些负语料,还可以去配置它的槽位词典,这里主要是用户自定义的词典。
这些信息会放到离线训练的系统当中,离线训练系统会做数据增强。对于配置的负语料会做负语料的增强,提取的槽位也会做槽位的增强。如果配置了规则也会进行句式的增强,还会做一些泛化。数据增强之后进行预处理,主要是实体识别、知识嵌入。在基本的数据处理完之后,就会把它放到模型里。这里定义了几类通用的模型去做整个意图识别的训练。训练完之后再通过知识蒸馏等等生成一个真正可以进行推理的模型。对于一些小的模型,我们会直接做local的inference,效率更好。而对于一些大的模型,我们会用TF serving的方式进行预测。
生成模型之后,我们会集成流程去做标准化NLU,也就是我们前面提到的预处理、前处理、意图识别和槽位提取。
3、基于检索的意图识别
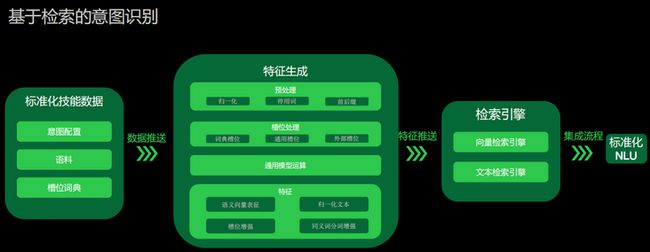
对于检索的意图识别,同样也会有它的意图识别、配置语料以及槽位词典,但语料相对来说个数不需要很多,更多的是通过它的槽位以及句式去生成检索。所以虽然我们也会做预处理,但预处理的内容就不太一样,我们会进行归一化,以及形容词和前后缀的基础的处理。相对比较重的是槽位的处理,我们会将词典槽位、通用槽位以及外部槽位一并集成进来去做槽位判定。最后再通过我们自己的预训练模型、语义向量模型去做一些运算,得到语义向量表征。为了保证整个检索的效果,我们不光会通过语义向量去做检索,还会把文本做归一化处理,生成进行过槽位增强的文本,计算在同义词和分词进行了增强处理后的文本,整体放到检索引擎上,这样在检索引擎上,我们就会有四维的特征。
我们有两个比较重的检索引擎,首先是基于语义向量的检索引擎,另外一个就是文本检索引擎,也就是说我们会从两个维度去检索整个意图。检索意图之后,我们会集成自定义的rank流程,去选择基于哪个表征去选择结果。这样生成意图之后,同样也是集成到标准化NLU流程里面去。
4、基于问答的意图识别
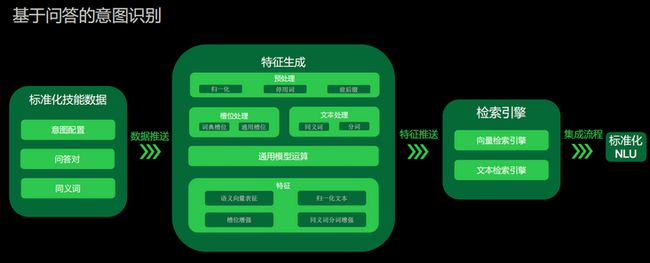
基于问答的意图识别与前面有所区别的是,它不会有很多的意图,可能是一类意图,但这一类意图当中会有非常多的问答。问答包括标准问题和相似问题,我们会让用户去把他的问题以及他的回复都配置进来,然后去做类似基于检索的一个流程,去进行归一化形容词以及槽位处理。但在这里,我们还会重点关注同义词的处理,因为很多问题是比较相似的。同义词处理完后,调用预训练模型去做通用的模型运算得到语义向量表征。然后同样的做一些文本处理,再放到检索引擎当中去,最后集成到标准化的NLU流程。这里的NLU流程只会得到问题,回复则会通过后面的对话管理模块去生成。
5、组件化核心功能,算子化编排服务

前面讲到我们定义了很多通用化的NLU流程,为了更好地复用这些NLU流程,并进行更多的NLU扩展,我们对于NLU业务的核心功能进行了去组件化,通过算子化的方式编排整个服务。
底层组件服务。文本引擎包含前面提到的预处理当中的归一化、前后缀处理、形容词处理等。检索引擎也就是前面提到的向量检索和文本检索。模型引擎包含local inference和serving inference。规则包括基于正则的规则等等。
通用业务算子。比如槽位生成算子,做词典的槽位,通用槽位算子,也会有一些预处理的槽位算子。我们还会定义一些通用的多分类模型,以及知识嵌入的业务算子等等。我们定义了几十个算子作为通用算子。
上层是编排起来一个基于DAG图的流程,定义每一个算子在不同的状态,应该怎样流转到下一个模块,再执行下一个业务算子的业务逻辑,最终实现我们的NLU流程。
6、大规模数据文本处理服务
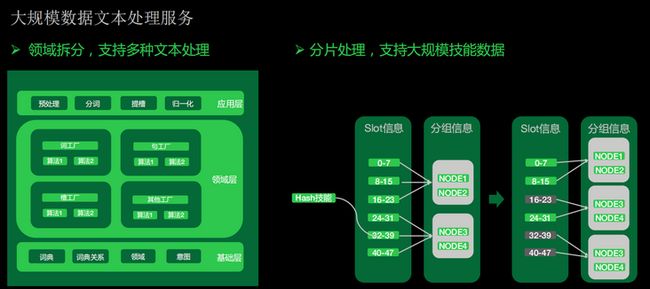
我们面临的一个比较大的挑战是在这种文本处理服务上会有很多的数据,一个技能可能需要几百万的词典,当我们的技能越来越庞大,文本处理服务很难扛起所有的技能。
因此,我们对文本处理的服务进行了一些领域的拆分,将不同的功能拆开,去支持槽位、词、句的处理。每一个处理又集成了相应的一些算法来定义领域。上层可以支持预处理、分词、提槽以及归一化等功能。为了去应对这种大批量数据的处理,我们借鉴了redis的分槽思想,将每个技能进行了一次hash来计算它的槽,然后基于槽定义分组。当我们的整个技能有一些膨胀的时候,就可以进行自动扩容,这个时候我们会去重新算它的槽。因为我们是基于哈希的方式,前两个槽还是留在本身的node上,新扩充的node我们会重新计算,分片到不同的节点上。
7、向量检索
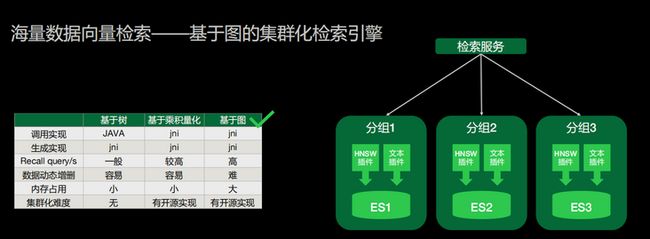
向量检索集成了一个基于图的集群化检索引擎。因为要支持很多的技能,每个技能面临的情况不一样,有些技能语料比较多,有些语料比较少。对于这种场景我们调研过不同的向量检索引擎,最终我们选择基于图的方式去做语义向量的检索。这种基于图的方式有开源的实现,可以不用在单机内存中去做,我们能很方便地把整个语义向量的检索和我们的业务逻辑拆开,将它独立出来。
我们把图检索的HNSW算法复写成了ES插件,ES就可以很好地去做集群化。不光是语义向量检索,我们的文本检索也可以很好地去复用ES本身的一些文本检索的能力。我们可以通过ES一次完成业务流程,所以我们选择了用ES去做检索引擎。
多模式易扩展流程化的对话管理
前面讲了我们在语义模块做的一些工作,接下来讲我们怎样做对话管理,也就是怎么去执行动作。
1、对话管理总览
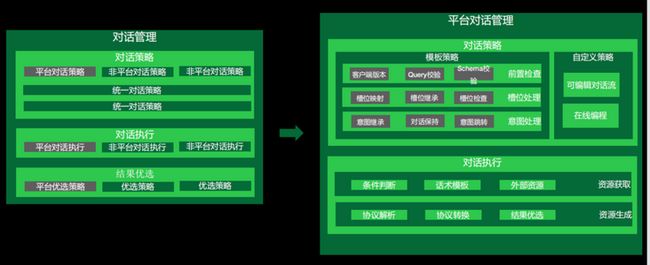
小布助手的对话管理分成三大部分。
首先是对话策略部分。小布助手里面有很多技能,既包含平台的技能,也有非平台的技能。我们首先要将对话策略和其他非平台的技能进行汇总,然后在统一对话策略的不同层级里面影响整个对话的结果。下一步是对话的执行,同样也有平台对话执行和非平台对话执行,在中控系统中会对这些执行去做一次整体的收集。收集之后进行结果的优选,有不同的优选策略,也会用到我们平台自定义的优选策略,最终为用户带来结果展示。
基于以上三大部分,我们定义了平台的一些对话管理。首先我们定义了一些模板策略,包括前置检查、槽位处理和意图处理。比如有一些多轮的情况,可以去做意图的继承、对话的保持或意图的跳转。有时候模板设计不能很好地满足用户的需求,我们就定义了一些可编辑对话流和在线编程的方式,用户可以自己修改对话策略,从而影响整个系统的对话策略,提高自己的优先级。在对话执行地部分,我们定义了一些条件判断和话术模板,去做资源的生存和协议的转换。
2、统一对话协议,自定义对话状态控制

在对话协议这部分,我们定义了一些对话状态的保持。我们整体定义了通用的对话信息,即能够传递上下文的意图和用户的历史信息,比如用户的兴趣爱好是什么,以及每一轮执行过的指令。通过通用对话信息的传递,我们可以在对话策略的位置区分意图确认状态,拿到这些状态后再做精细化rank决策。
通过这种模式我们可以实现弱多轮的效果。弱多轮主要是通过上下文信息保持和传递来达到的。而填槽式的强多轮,我们会填充槽位以达到跳转。在沉浸式强多轮,我们会做对话保持和意图继承。
3、定制化对话支持

对于可编辑的对话流,我们基于状态机的方式实现了流程化的对话设计。用户可以在界面上编辑每一个地方输入的语音是什么,当满足了用户输入的条件或语音输入的条件时,判断是否要进行切换,从而实现动态的对话流。比如我在节点1定义当用户讲到了成都槽位的时候,需要跳到下一个节点,如果没有讲到,则要跳到另外一个节点,这个节点的对话也可以进行支持,当用户执行完动作后是否要保存这个状态,帮助用户很好地定义多轮状态应该怎样扭转,去实现不同的强多轮弱多轮的逻辑,让用户更灵活地去实现整体的对话流。这里的每一个动作和每一个条件,我们定义了不同的扩展性的条件判断,让用户可以去判断各个维度的条件。
在线编程模式是通过函数式的编程化的方式去最小化接入成本。首先我们定义了一个通用的DST对话状态转移接口,让用户可以在拿到自己的NLU信息后去做自定义。除此之外,我们还支持python代码嵌入到我们的Java代码当中,实现自定义接口。
4、通用对话协议
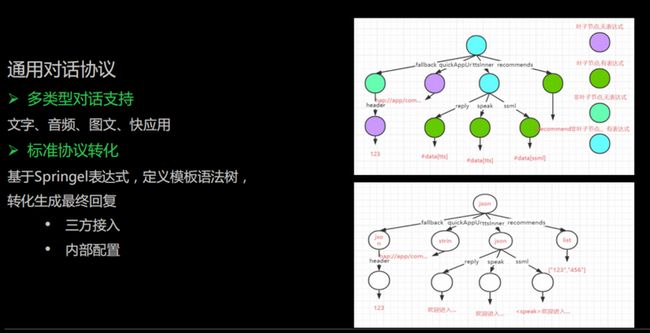
平台支持不同类型的对话回复,比如文字、音频、图文、快应用等。不同的回复类型协议比较复杂。如果我们通过三方接入,三方的协议也会比较复杂。
为了应对不同协议的转换,我们定义了模板的语法树,可以将内容填入到我们的模板里,最终生成一个我们自己的客户端协议。通过这样的方式,我们可以很好地应对协议过多以及三方接入协议比较复杂的情况,让整体管理模板可以控制,同时我们也可以在这些节点上去做一些转换。
端到端一站式离线平台,看得见的技能生命周期
对于小布助手,我们还做了一件事,就是让整体的技能以一种全生命周期的方式运转起来,让我们的平台用户能够不断地去优化它的技能。
1、跨环境数据同步
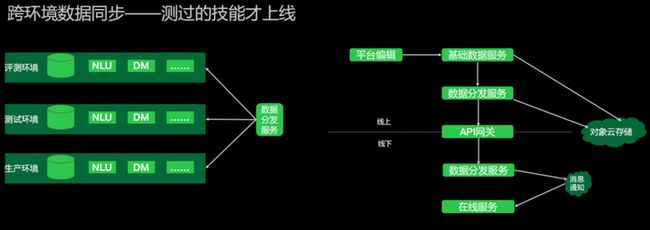
我们定义了几个环境,首先是当用户编辑了数据之后,能够让用户在自己的测试环境进行一些基础的测试。基础测试完成后,我们会把数据推送到评测环境,将用户的数据和小布内部的各种数据进行融合,让它端到端地跑起来。跑起来之后,我们会知道在平台上配置的技能是否有影响我们内部开发的一些技能,如果受到了影响,那么是对回复有影响,还是对语义有影响?我们是否应该去提示开发者修改语料,还是我们的策略有问题?这些都是在评测环境中进行。
当评测环境验证通过后,我们会推送到内部的测试环境,由专门的测试验证技能在各个端上的表现。当整体数据在测试环境验证OK之后,我们才会将正式的技能推送到线上环境。这样能够保证整体用户在平台上配置的数据是可控的,而且是一个真正能够用起来的技能。
整体上,依赖于我们自定义的数据分发服务。用户在线上平台编辑后,我们把它存到基础数据服务里面,基础数据服务再去通过调用数据分发把数据推送到对象云存储中。数据分发服务通过API网关通知线下的一些数据分发服务,去拉取对应的数据。当在线服务收到了这个数据的通知之后,我们会从对象云存储把线上的数据拉取起来,进行加载。这些流程得益于我们在NLU、意图识别和对话管理的部分定义了非常多的标准化流程,所有业务流程都以数据化的方式进行表达。这样我们就能够很好地推送一份数据,把整体的NLU和DM很好地运转起来,在不同的环境去做一些验证。
2、线上数据挖掘
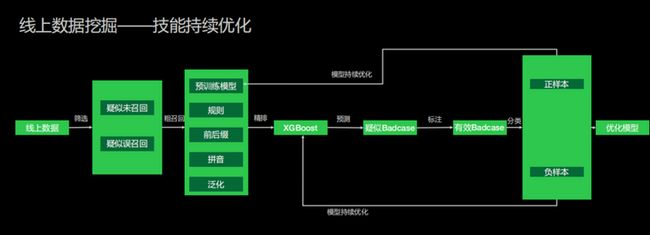
验证好后,技能上线。上线后我们还希望能够去做一些持续性的优化。因为很多技能上线后,我们并不知道它对于线上真实的用户样本是否产生了影响,所以我们还定义了一个线上数据挖掘的持续优化过程。
如果用户需要去开启我们数据挖掘的一些功能,开启后我们会对线上的数据进行筛选,得到一些疑似未召回或者疑似误召回的语料。下一步我们会用到我们自己的预训练模型,去做粗召回。之后我们再调用精排小模型去做一些预测。通过预测,我们能够得到疑似的badcase。很多时候我们还是需要通过标注去识别是不是一个有效的badcase。如果它是一个有效的badcase,我们会去标注它是正样本还是负样本。通过这种标注,我们会自动提供这些正样本和负样本的数据让用户选择,是否要把它加入到语料当中。如果能够加入到语料当中,我们会帮助用户去优化整个数据模型和语料。也就是说,如果有一些用户配置的数据比较少,我们也可以通过这样的方式进一步丰富他的语料。如果他在不同的意图下配置语料有问题,我们也可以通过这种方式纠正他的语料。同时,因为我们通过人工标注的方式得到了一些正样本和负样本,我们可以在流程中去做整个模型的持续优化,持续地优化我们的技能。通过这样的方式,我们能够达到整个流程端到端的表现,使小布技能平台实现更完整的技能。