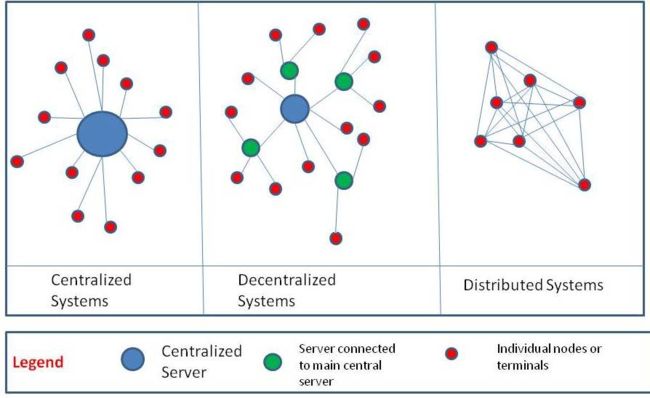
1. 分布式一致性
分布式一致性大体上意味着, 在多个分散的机器上, 如何保证状态(key value tuple)是完全一致的.
HDFS非常粗暴的使用写入后三备份来保证, 如果三备份中的一个坏掉了. 另外两个发生silent corrupition 同时恰好发生位置是文件校验码, 那么程序就无法判断剩下的两个备份哪个是正确的. 因为IBM和微软会每隔一段时间联合发布Disk Silent Corruption的概率, 所以这种极端情况是可以计算概率.
同时在HDFS中有唯一的NameNode来协调保持元数据一致,元数据是单点写入的.
在某些系统里所有工作节点是平权的, 任何节点挂掉都要保证数据的一致性, 就需要更复杂的算法
2. 拜占庭将军
https://people.eecs.berkeley.edu/~luca/cs174/byzantine.pdf
这个问题抽象的理解为, 指挥官需要在战场上给分散在各处的将军下命令. 让他们处于进攻状态或者防守撤退状态, 所有的将军必须尽可能是统一状态的, 才能保证战争胜利.
- 递送消息的人可能半路被敌军截获, 导致消息没有传送到位. 也就是说网络可能波动
- 将军相互之间传递信息也可能被截获. 网络分区可能直接出问题
- 将军中可能有叛徒, 故意给其它人扩散假消息. 可能存在错误的节点, 或者消息包可能损坏.
在以上情况下, 如何保证将军们, 至少是绝大多数将军们状态是一致的?
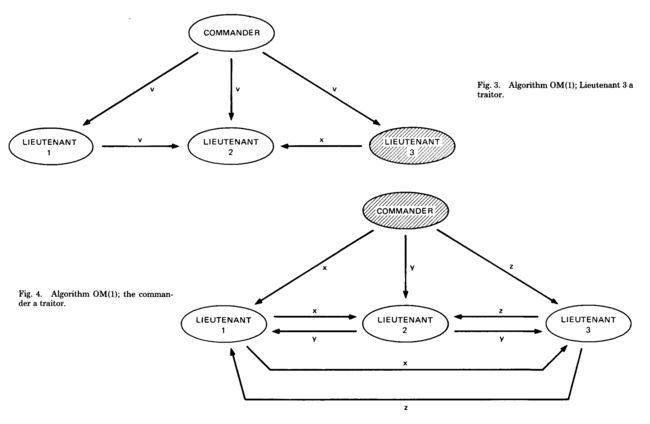
最早的思路认为所有的将军是全联通的, 两两都可以通信, 在这种情况下. 实际上就是采用了投票机制, 大家相互交换自己对情况的看法. 是攻还是守, 少数服从多数. 如果一个意见无法形成绝对多数就不动. 相当于本地投票没有有效结果.
这种实现效率极低, 无法解决现实中的问题. 后续对拜占庭问题有了几种抽象优化来解决.
3. Paxos
http://lamport.azurewebsites.net/pubs/paxos-simple.pdf
3.1 Paxos核心场景
- 信息可能会丢失, 可能会重复, 可能需要非常非常久的时间才能递送到, 不能保证先后顺序. 但信息不被截断或者恶意伪造
- 工作节点可能会重启, 可能会丢失消息, 可能无法保存消息到本地. 但一个消息一旦落地到了本地, 在重启前不回丢失
所以其实Paxos目标是解决了拜占庭问题的一个侧面, 并不是完全语义下的拜占庭问题. Paxos算法实际上解决了希腊Paxos岛上的法律制定者们, 如何协调意见, 通过法条的问题.每个希腊参议员, 有自己的法律条目记事簿. 通过书记团队传递自己对于法条的修订. 参议员会随机离开大厅, 书记团队也有可能不靠谱, 丢了纸条呀, 忽然离开呀之类的. 和拜占庭问题非常类似, 但是参议员不会伪造信息, 书记员不会递送一部分信息. 这是显著的不同.
Paxos是Google Chubby
3.2 Paxos的提交模式
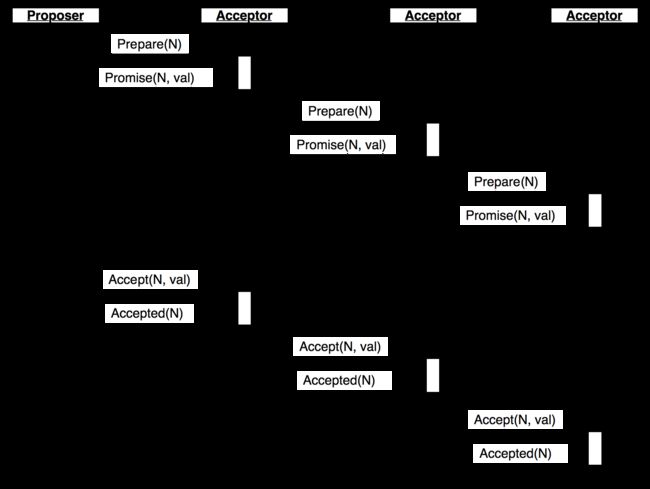
Paxos是一个两段式提交过程, 涉及到三种不同的角色Proposer, Acceptor, Listener
第一阶段, 由代表(Proposer)灵光一闪说我要发起一个提议, 这个提议之前的讨论结果和编号是xxx, 我提议的编号是zzz. 这提议必须通过书记官(Network), 广播到半数以上的议员那里(Acceptor). 这些议员可能回馈说:
- "我们当前准备好就这个法律进行讨论了, 坚决拥护代表的选择" . 说明当前参与讨论的节点状态一致
- "这个提议的编号明明是 aaa, 你那里怎么会是xxx? 大雄消息真不灵通呢.jpg" 说明Proposer有落后的信息, 它只能在同步最新信息后再次提议
- "一个比你牛逼的哥们已经提议 yyy了, 我不参与你的讨论, bye~" 说明另外一个Proposer同时发起了相同的key-value对, 且根据策略, 它优先获得了大多数人口头支持, 相当于成为了执政党, 本次提议只能作废.
第二阶段, Proposer提出具体的条目, 这些准备讨论这个条款的议员们回馈, 当然部分议员可能溜了, 消息也有可能送不到. 最后如果运气好, 超过半数通过, 则这条法律立即生效. Proposer就可以确认这条法律已经落盘到了超过半数的议员的记事本上
希腊政治体系下的参议员也是公民, 参议员也可以发起讨论. 所以Proposer, Listener, Acceptor可以是同一个节点
为了保证书记官不错漏, 让参议员们可以跟踪消息. 所有传递的信息必须有一个全局唯一递增编号. 1xx年希腊第x号参议员的第xxx号消息如下.... 这样接受者可以知道过来的消息是讨论哪个法条的. 也可以扔掉那条过时的消息和重复递送的消息.
两个代表同时提出相同的提案, 议员们的一般策略是只会Promise标号大的那个, 对于标号小的那个直接就略过.
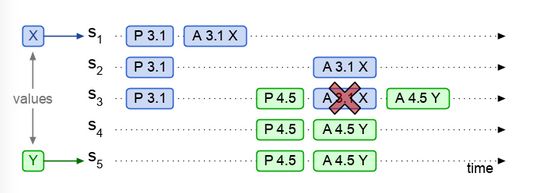
3.3 Node的策略说明
作为一个活着的node, 我在自己的小本本上记录, 当前最大编号MaxN, 所有已经通过的法条Accept Key Value, 我正在参与的讨论的编号 PromiseN. 同时我保持一个特别朴素的想法, 谁的编号大我就认谁.
如果大佬Proposer告诉我一个Key Value改了, 并且这条信息编号比本地的大, 我就更新它, 甚至根据具体的系统设计我还会扩散这条信息
如果我已经承诺了一个大佬, 我会参与了 一个事项的讨论, 比如该不该削弱虫族, 并且大佬告诉我这是今年的第45号法案. 那么所有邀请我讨论这个事情, 并且编号小于45的一律拒绝, 因为我没时间.
经过漫长的讨论, 大佬告诉我暴雪决定削弱虫族了, 我就记下来第45号法案通过, 马上削弱小狗的攻击频率.
忽然一个新的大佬Serral出现了, 告诉我说黄旭东奶了暴雪一口, 暴雪决定加强虫族, 而且这条法案的编号高达97.... 我立马记下来这条信息覆盖掉45号法案, 广播这条信息, 并潜伏起来等待神族的黎明来临.
由于两段式确认过程都需要超过半数node参与, 根据抽屉原理. 最终必然至少有一个node参与了全程.
4. Zab
http://img.bigdatabugs.com/Zab%20High-performance%20broadcast%20for%20primary-backup%[email protected]
4.1 Zab协议和Paxos的共性包括:
- 都需要一个大佬(Leader / Propoer)来发布提案
- 发布的提案在一个议会中(Quoram)的一定数量的人(Follower / Acceptor)都认同后才算提交完成
- 为了操作幂等, 所有提案包括一个唯一的自增ID
4.2 Zab和Paxos的不同
Zab协议关注的是主从备份问题(primary backup)
Paxos协议关注的是状态机的备份(state machine replication)
4.3 state machine replication
作为图灵机的数学模型, state machine作为一条无限长的纸袋. 任何两条纸袋, 只要接收相同的action queue, 一定达到相同的结果.
一个state machine replication需要保证每个状态机都按照特定的顺序执行客户端发过来的action.
即使client端是并发发送的这些action(本身无序), 网络拓扑无法保证消息的传递按照发送的先后熟顺序(中间件不保序列), 部分action可能会重发(幂等性)
当leader挂掉, 新的leader可以为那些尚未提交的action进行任意重排序, 这不会影响最终结果的语义正确性. \
核心问题是如何让所有节点对客户端请求理解一致
海洋法系系统: 一群大法官无论以任何顺序讨论法条, 无论同时讨论多少个法条, 只要在某个最终时刻, 所有法官对法条的理解一致就可以了. 如果在讨论过程中, 发起讨论的法官去吃饭了. 接手的法官其实并不需要理解刚才那位的想法, 他只要保证讨论能继续, 并且最终一致就完了.
4.4. primary backup
在这种系统里, Follower Node接收到的是从Primary Node发过来的排好序的增量更新. 这里的增量更新必须严格和primary执行顺序一致, 每个follower也必须严格的和leader处于完全相同的初始状态. 如果leader宕机了, 新选举的leader不能随意的安排未提交操作的顺序, 也不能从一个不同的初始状态来更新.
核心问题是如何让主从保持完全一致
大陆法系系统: 人大作出了最终的法律决策, 投票通过了一个法条. 所有省级人民法院, 市级人民法院层层递推, 把法条落实到自己的工作中. 因为某次停电故障, 人大不得不换了个地方重新开会. 停电前的投票计数不能终止, 已经计数的结果不能丢失.
4.5 Paxos的局限性
恶性竞争锁
两个Proposer提出完全相同的议案, 并争取多数议员支持. 我们刚才说过, 一般系统设计类, 议员的策略很简单, 就是谁号大听谁的. 于是这两个Proposer就不断的提升自己的议案编号, 议员不断的接收到递增的Prepare请求, 并立即拒绝上一个. 导致两个Proposer都无法获得绝对多数支持, 从而谁都通不过信息.同时发起的议案不保序
一个议长Proposer同时发起多个不同的议案, 然后发起后他就去吃饭了. 接班的议长并不知道刚刚发起的多个议案相互之间的先后顺序, 就有可能导致这些议案的通过顺序不同. 如果这些议案恰好不是正交的, 那么最后会得出不同的结论.
例如议长先后发起的两个语义正交的议案, 酒醉驾车违法, 家暴违法. 然后去吃饭了, 新来的哥们主持后边的会议是没有问题的.
但如果前任议长发起的议案在语义上不正交, 必须保序. 比如 F91必须在WCS上穿女装, F91必须在WCS上换一次衣服. 根据继任者的理解不同, 可能F91会先女装,然后换装, 偏离了初衷.
4.6 Zab协议
论文中的Zab的解释图
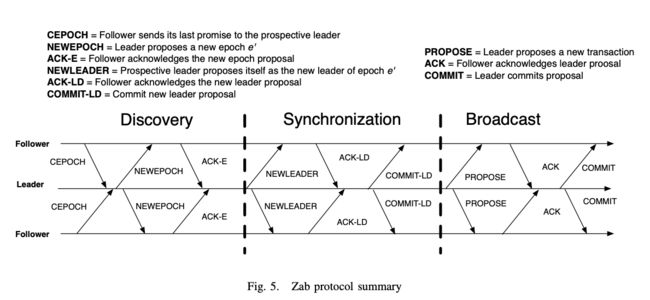
加上选举阶段, 可以认为正常流程包含4个阶段, 依次为
Leader Election
Peers在这个阶段初始化, 对于一个ZK 进程来说, 它处于leader, election, follower三种状态中的一种. 经过选举阶段, 最终一个peer为被标记为establish Leader候选人, 其它peers也都从election状态切换到follower装填Discovery
在这个阶段, leader会从follower那里收集所有最近的提交信息(transaction), 图中的CEPOCH. 这一操作保证了leader可以discovery最近所有被提交的更改, 并且知道更改的先后顺序. 以保证它和前任leader拥有完全相同的初始状态.
之后它向所有的follower发送图中NEWEPOCH并搜集回馈ACK-E, 保证多数的follower都认它做老大. 此时如果前任老大断网重连, 也会因为EPOCH不符合当前多数follower的记录只能做小弟.Synchronization
这个极端其实包含了错误恢复部分, leader昭告所有follower它的Proposing Transaction, 以继续前任可能未尽的事业, 并确立自己的地位, 图中NEWLEADER信息传递部分. 当多数follower确认ACT-LD了已经与leader保持一致后, establish Leader正式加冕为王, 可以开始提议案了Broadcast
只要系统中没有出现重大故障, 系统会一直处于这个工作状态下. 这里才是正常的zookeeper工作状态. leader从客户端接受信息, 然后非常类似paxos的进行proposeactcommit两段式记录. 区别在之前提过的, leader会为propose添加唯一递增编号, 以保证恢复时的有序性.
4.7 选举 Fast Leader Election
在老leader掉线后, 整个集群必须在有限时间内选举出一个新leader, 并且这个新leader必须和老leader的数据完全一致. 这里的状态一致不但包含了已经commit的数据, 甚至还要求哪些Propose了但没Commit的部分也要有记录.这样它才能继承前者的遗志, 把队伍带好
根据抽屉原理, 只要整个系统还活着(存活peers大于一半), 必然有一个peer满足条件, 然后我们要把这个点选出来做话事人
由于所有的Propose带唯一递增编号, 所以peers就可以相互交换自己已经知道的历史. 如果一个peers发现自己记录的历史信息比其它人都要全, 它投票给自己, 并把自己置位到leader状态,反之, 置位到folower状态.
在投票中可以制定一个规则, 在历史记录不同的情况下, 谁记录的多我就投给谁(most update). 在历史记录一样的情况下, 谁年轻(max peer id), 我就投给谁.
由于网络可能存在时延\掉包, 整个选举过程可能要来上几轮. 在peer与peer交换信息的过程, 一个peer会使用 (vote, id, state, round)来描述自己投给谁, 自己是谁, 自己的装填, 自己当前所在的投票轮数. 经过多轮投票后, 只要整个系统中有多数peer存活, 且这些存活的多数peer均可以和真正的leader通信(无网络分区错误), 最终会有leader被选出, 然后正常的后续流程.