【摘要】
看起来很简单的集合运算放在大数据的场景下,如果还想获得高性能就需要充分了解数据特征和计算特征才能设计出高效算法。充分利用序运算就是一种好办法!
交并差是常见的集合运算,SQL 中对应的 intersect/union/minus 计算也很简单。不过当数据量较大时,这类集合运算性能往往偏低,尤其当参与计算的数据量超过内存容量时,性能表现会十分糟糕。
本文专门针对这种情况下的高性能计算(HPC)需求,讨论如何使用集算器 SPL 语言通过有序计算思路显著提高大数据量下交并差三类集合运算的性能。下面讨论中使用了一个实际用户在数据库选型时的评测用例:数据基于数据库的 2 个表,共计 105 亿行数据,执行相关运算后,以输出第一批 500 条记录所用时间来衡量哪个数据库性能更优。

数据描述

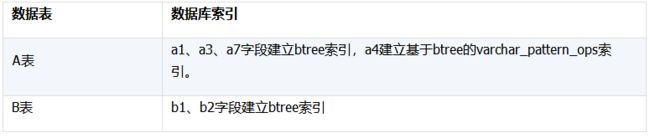
索引
样例数据
a1-a52 列值:
2018-01-07 00:00:00,8888888888,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt,MQJqxnXMLM,ccTTCC7755,aaa******8,ppppaaaavv,gggggttttt
2018-01-07 00:00:00,4444444444,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR,dv@bi-lyMF,qqoovv22ww,)))777FFF4,jjjjIIIIVV,aaaaaRRRRR
2018-01-07 00:00:00,9999999999,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP,bxk3J/2YDd,ppvv**--88,uuuNNNBBBA,BBBBhhhhjj,_____PPPPP
测试用例
l 交集(intersect)
select * from A, B where a1>'2018-01-07 02:14:43' and a1 < '2018-01-07 04:14:43' and a3=b1 or a7 = b2
intersect
select * from A, B where a1>'2018-01-07 12:14:43' and a1 < '2018-01-07 14:14:43' and a3=b1 or a7=b2
l 并集(union)
select * from A, B where a1>'2018-01-07 02:14:43' and a1 < '2018-01-07 04:14:43' and a3=b1 or a7 = b2
union
select * from A, B where a1>'2018-01-07 12:14:43' and a1 < '2018-01-07 14:14:43' and a3=b1 or a7=b2
l 差集(minus)
select * from A, B where a1>'2018-01-07 02:14:43' and a1 < '2018-01-07 04:14:43' and a3=b1 or a7 = b2
minus
select * from A, B where a1>'2018-01-07 12:14:43' and a1 < '2018-01-07 14:14:43' and a3=b1 or a7=b2
用例分析
分析上述 SQL 可以发现,此计算场景为大数据量的多对多集合运算。查询条件的前半段(a1>'2018-01-07 02:14:43' and a1 < '2018-01-07 04:14:43' and a3=b1)是 A 表 2 个小时内的数据与 B 表进行多对多关联;而后半段(or a7 = b2)则是 A 表全量数据和 B 表进行多对多关联。因此,这个用例主要考察的是大表 A 和小表 B 多对多关联后的集合运算性能。
实测时,该 SQL 使用 MPP 数据库得不到查询结果(运行时间超过 1 小时),因为数据量很大,内存无法容纳全部数据,从而造成数据库在运算时频繁进行磁盘交互,导致整体性能极低。
按照我们一贯的思路,要实施高性能计算必须设计符合数据特征和计算特征的算法,而不是简单地使用通用的算法。这里,为了避免过多的磁盘交互(这也是大数据规模计算的首要考虑目标),最好只遍历一次 A 表就能完成计算。观察数据可以发现,A 表包含时间字段(a1),而且在时间字段(a1)和关联字段(a3、a7)上均建有索引,同样 B 表的两个字段(b1、b2)也建有索引,这样,我们就可以设计出这样的算法:
1) 根据 A 表数据生成的特点,逐秒读取 A 表数据(每秒 24000 条);
2) 针对每秒的数据循环处理,根据过滤条件逐条与 B 表关联,返回关联后结果;
3) 对两部分数据,即用于交并差的两个集合进行集合运算。
通过以上三步就可以完成全部计算,而整个过程中对 A 表只遍历了 2 次(分别得到用于交并差的两个集合)。当然,整个过程中由于数据量太大,集算器将通过延迟游标的方式进行归并,游标归并时数据需要事先排序,所以在 1)和 2) 步之间还需要对每秒的 24000 条数据按照关联字段和其他字段排序,会产生一些额外的开销。下面是具体的集算器 SPL 脚本。
SPL 实现
这里分主子两个程序,主程序调用子程序分别获得交 / 并 / 差运算的两个集合并进行集合运算,子程序则根据参数计算集合,也就是说用例中的交并差三类计算可以使用同一个子程序脚本。
子程序脚本(case1_cursor.dfx)

A1:在 otherCols 中记录 A 表 52 个字段中除参与运算的 a1,a3,a7 外其他所有字段名称,用于生成 SQL 查询
A2:连接数据库
A3:SQL 语句串,用于根据条件查询 A 表所有列数据
A4:查询 B 表数据,针对 b1,b2 进行分组计数(以便在后续计算中减少比较次数),并按 b1,b2 排序(用于后续有序归并)
A5:按照 5 天时间内的秒数进行循环
B5:每次循环中在起始时间(2018-01-07 00:00:00)上加相应的秒数,查询那一秒产生的数据(24000 条)
B6:按照关联字段以及其他字段排序
B7:循环处理一秒内的每条 A 表数据
C7:根据单条 A 表数据,在 B 表中查找符合条件的记录
C8:返回计算后包含 A 表和 B 表所有字段值的结果集,这里使用了 A.news() 函数,用来计算得到序表 / 排列的字段值合并生成的新序表 / 排列,具体用法请参考http://doc.raqsoft.com.cn/esproc/func/news.html
主程序脚本
交集(intersect)

A1,A2:通过 cursor()函数调用子程序脚本,并传入 2 个时间段参数;cursor() 函数原理请参考: 《百万级分组大报表开发与呈现》
A3:根据子程序返回的游标序列进行归并,使用 @i 选项完成交集运算
A4:从游标中取出 500 条记录,并关闭游标(@x 选项)
并集(union)

A3:使用 @u 选项完成并集计算,其他 SPL 脚本完全相同
差集(minus)
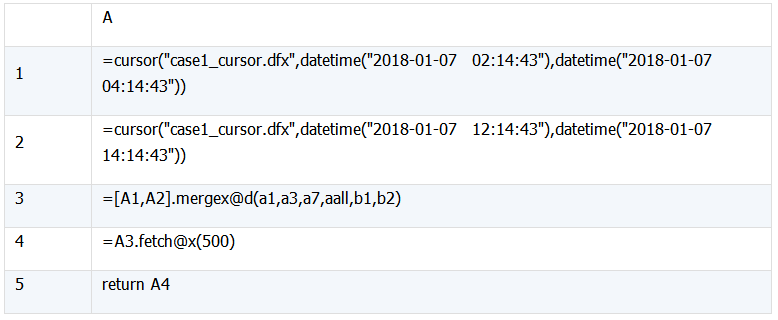
A3:使用 @d 选项完成并集计算,其他 SPL 脚本完全相同
性能表现
下表对集算器 SPL 和数据库 SQL 分别输出第一个 500 条结果集的时间进行了比较:
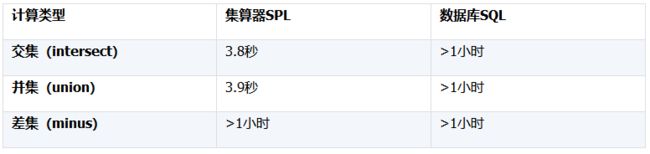
显然,交集和并集计算的性能得到了极大的提升。
为什么差集运算很慢?
差集运算依然很慢的原因是由数据特征所决定的。由于多对多关联后重复记录较多,要计算出符合条件的差集仍旧要遍历完 A 表(而另外两个计算获得 500 条结果集就可以不再遍历了),因此性能主要消耗在 IO 取数上。
总结
高性能算法需要根据数据和计算特征进行针对性设计,这要求程序猿首先能够想出高性能算法,然后以不太复杂的手段加以实现,否则就没有可行性了。
对于 SQL 体系来说,由于其封闭性原因,一些高效算法可能即使能设计出来也很难,甚至无法实现。而集算器 SPL 则极大地改善了这个问题,使用者可以在设计出高性能算法后,基于 SPL 体系快速实现。