Python爬虫学习笔记_DAY_23_Python爬虫之bs4解析的基本使用介绍【Python爬虫】
目录
I.bs4的介绍
II.bs4的安装
III.bs4的基本语法使用
p.s.高产量博主,点个关注不迷路!
I.bs4的介绍
首先,介绍一下bs4,它是又一种解析的手段,之前有xpath和jsonpath。bs4的特点是这样的:
BS4全称是Beatiful Soup,它提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
bs4最舒服的一点是提供了更适合前端开发工作者使用的语言习惯,它的语法很大程度对前端开发工作者是友好的,同时它解析的对象是本地html文件和服务器的响应html文件。
II.bs4的安装
接下来,我们安装一下bs4:
1️⃣ 首先,我们打开pycharm,选中File - - - > setting
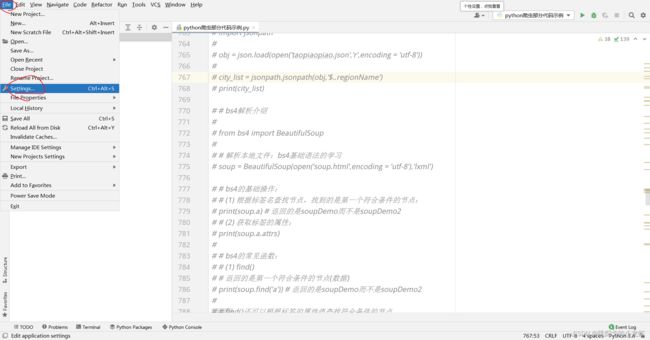
之后选择 Project:xxxx - - - > Python Interpreter
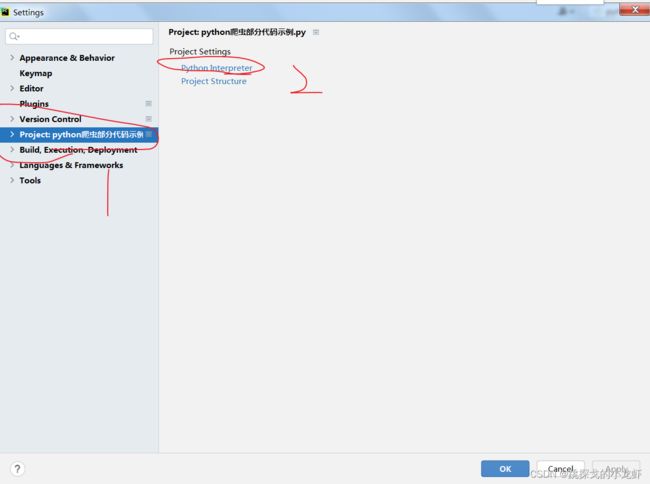
最后按照图中位置,找到自己的python的安装地址,并且进入该地址:
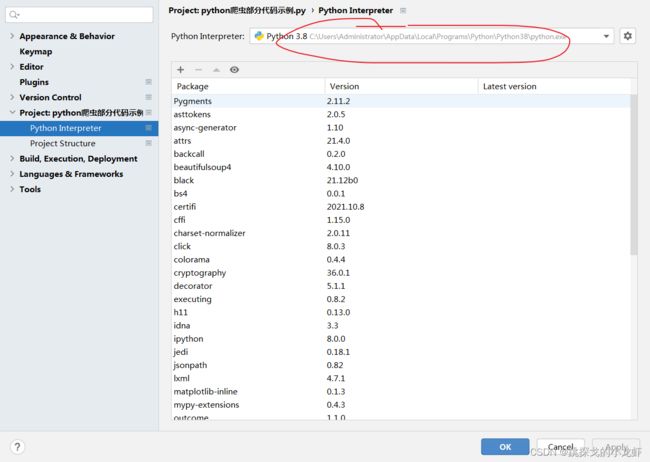
2️⃣ 之后,在地址所示的这个位置,我们按 Win + R,调出终端框,并输入 cd,之后路径还是用拖拽法把Scripts文件夹拖进cd光标后(要在cd后面间隔一个空格):
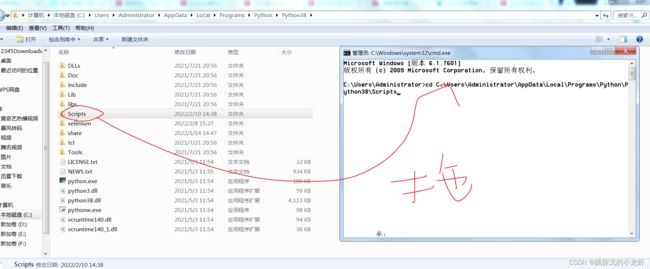
3️⃣ 最后,在终端框输入下面的指令,安装jsonpath:
pip install bs4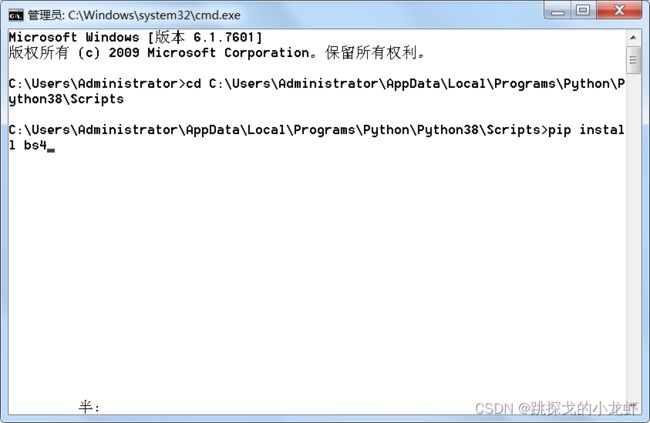
III.bs4的基本语法使用
前面提到bs4可以解析本地和服务器响应html文件,为了方便介绍bs4的基本语法,我们以本地的html为例,下面是本地html的源码:
soupDemo
- 张三
- 李四
- 王五
- 周六
soupDemo
hhh
soupDemo2
我把这个文件命名为soup.html,后面以这个名字作为读入的名称。
1️⃣ 导入本地html文件:
from bs4 import BeautifulSoup
# 解析本地文件:bs4基础语法的学习
soup = BeautifulSoup(open('soup.html',encoding = 'utf-8'),'lxml')这部分首先肯定要导入bs4,导入的格式是 from bs4 import BeautifulSoup,之后我们把本地的html文件读入即可。之前新建的soup.html文件最好放在与当前的python项目文件同级目录下,方便我们进行路径的输入。
bs4读入本地文件的格式与jsonpath基本上相同,它传入两个参数(比jsonpath多了一个):一个是文件对象,一个是字符串'lxml’,前者是一个变量,后者是一个字符串'lxml',固定的,我们只需要每一次更改文件对象即可操作不同的文件。
2️⃣ bs4的基本操作语法:
from bs4 import BeautifulSoup
# 解析本地文件:bs4基础语法的学习
soup = BeautifulSoup(open('soup.html',encoding = 'utf-8'),'lxml')
# bs4的基础操作:
# (1) 根据标签名查找节点,找到的是第一个符合条件的节点:
print(soup.a) # 返回的是soupDemo而不是soupDemo2
# (2) 获取标签的属性:
print(soup.a.attrs)上面是两个bs4的基础语法,获取标签元素和标签元素的属性,其中属性那一项指的是标签的所有属性,都会被打印出来。另外注意一下,它获取的是第一个符合条件的节点,而不是所有符合条件的节点!(这里的标签就是指的是h5的标签)
3️⃣ bs4常用的六个函数介绍:
from bs4 import BeautifulSoup
# 解析本地文件:bs4基础语法的学习
soup = BeautifulSoup(open('soup.html',encoding = 'utf-8'),'lxml')
# bs4的常见函数:
# (1) find()
# 返回的是第一个符合条件的节点(数据)
print(soup.find('a')) # 返回的是soupDemo而不是soupDemo2
# find()还可以根据标签的属性值查找符合条件的节点,
# 例如下面通过title属性值查找:
print(soup.find('a',title = 's2'))
# class属性也可以被查找,但是注意class本身是python的关键字
# 因此我们要加一个下划线:class_
print(soup.find('a',class_ = "a1"))
# (2) find_all() :返回结果是一个列表,包含了所有目标标签(这里是a标签)
print(soup.find_all('a'))
# 如果想要多标签的数据,需要在find_all中传入列表对象,如下例:['a','span']
print(soup.find_all(['a','span']))
# 如果想要限制返回的标签数量,可以加一个limit,它的值表示查找前n个数据
print(soup.find_all('li',limit = 2)) # 查找前两个数据
# (3) select() (推荐)
# select()返回一个列表,同时和find_all一样返回所有的目标标签
print(soup.select('a'))
# 类选择器(在前端的一种叫法):可以通过加一个 .类名 来筛选class
print(soup.select('.s1'))
# id选择器(也是前端的一种叫法):可以通过加一个 #id名 来筛选id
print(soup.select('#s2'))
# 属性选择器:可以通过属性存在与否、属性的具体值来筛选
print(soup.select('li[id]')) # 这表示查找所有的 li标签 中含有 id 的标签li
print(soup.select('li[id = "l2"]')) # 这表示查找所有的 li标签 中含有 id 且id的值为l2的标签li
# 层级选择器:
# a.后代选择器:一个空格,查找某个标签的后代,包括儿子、孙子标签
print(soup.select('div li'))
# b.子代选择器:一个大于号,只能查找某个标签的儿子标签,不包括孙子标签
print(soup.select('div > ul > li')) # 这里写 div > li,则没有内容返回,因为li是div的孙子标签而非子标签
# 多个标签都拿到:
# 在select()中,我们无需用列表的传参表示多个标签,直接以逗号隔开多个标签即可:
print(soup.select('a,li'))
# (4) 获取节点具体的信息的函数
# a.获取节点的内容
# 注意要加一个索引,因为我们的select会返回一个列表,不加索引,就无法处理成字符串
obj = soup.select('#s2')[0]
# 如果标签对象中只有内容,那么string和 get_text()都可以使用
# 但是如果标签对象中有内容也有标签,那么string就无法使用,只能用get_text()
print(obj.get_text())
# b.获取某个具体的节点(标签)的属性
# 首先获取id值是s2的标签
tag = soup.select('#s2')[0]
# 返回这个标签的名字,例如a标签,就返回一个a
print(tag.name)
# 将所有的标签属性以字典的格式返回
print(tag.attrs)
# 获取某个节点的具体某一个属性,原理是可以根据attrs的字典对象特点,
# 用字典对象的get函数,传入键,来获取某一个键值对的值
print(tag.attrs.get('title')) # 获取id值是s2的标签的title属性
关于最后一条,补充一下,就是说tag.attrs会返回一个字典,这个字典是该标签所有的属性,那么我们需要其中一个属性,可以用字典的一个方法get(),传入键,获得对应的值,这是一个键值对的关系!