在本章中,我们将使用 tensorflow.js 拟合曲线的合成数据集。使用一些噪声多项式函数生成的一些数据,我们通过训练模型发现用于生成数据的系数。
阅读本章钱建议先看一下上一章的内容:TensorFlow.js 中的核心概念。
本章以 github 上的 demo 为例,阐述一下实现数据曲线拟合的步骤及思路。
输入数据
我们的合成数据集是由X和Y坐标组成的,如下图绘制在坐标平面:

这个数据是由多项式方程 y = a * x ^ 3 + b * x ^ 2 + c * x + d 生成的。
我们的任务是找到这个函数的系数:a、b、c和d的值最适合数据。让我们看看如何使用 TensorFlow.j 来找到这些值操作。
第一步:设置变量
首先,让我们创建一些变量,以在模型训练的每一步中保持当前对这些值的最佳估计值。首先,我们要给每个变量分配一个随机数:
const a = tf.variable(tf.scalar(Math.random()));
const b = tf.variable(tf.scalar(Math.random()));
const c = tf.variable(tf.scalar(Math.random()));
const d = tf.variable(tf.scalar(Math.random()));
第二步:创建模型
我们可以通过一系列的加法、乘法、幂运算等数学运算,用多项式方程 y = a * x ^ 3 + b * x ^ 2 + c * x + d 来创建模型,如下代码:
下面的代码构造了一个 predict 方法,它将 x 作为输入并返回 y。
function predict(x) {
// y = a * x ^ 3 + b * x ^ 2 + c * x + d
return tf.tidy(() => {
return a.mul(x.pow(tf.scalar(3))) // a * x^3
.add(b.mul(x.square())) // + b * x ^ 2
.add(c.mul(x)) // + c * x
.add(d); // + d
});
}
让我们用a、b、c和d的随机值来绘制多项式函数,我们在步骤1中设置。大致图如下:
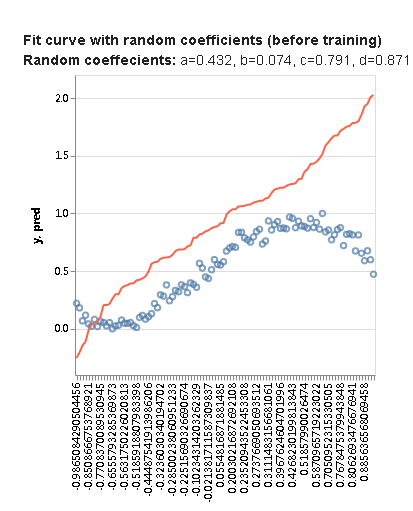
因为我们从随机值开始,我们的函数很可能对数据集拟合不好,模型还没有更好地学习系数值。
第三步:训练模型
我们的最后一步是训练模型学习好值系数。训练我们的模型前,我们需要先做三件事:
1、定义损失函数
一个损失函数,它度量一个给定的多项式与数据的匹配程度。损失值越低,多项式越拟合数据。
对于本章,我们将使用 平均平方误差(MSE) 作为我们的损失函数。MSE 的计算方法是将实际的 y 值与我们的数据集中的每个 x 值的预测值之间的差值平方,然后取所有结果项的平均值。
对损失函数做如下定义:
function loss(predictions, labels) {
// 从预测值中减去实际值,然后取平方值,最后去平均值
const meanSquareError = predictions.sub(labels).square().mean();
return meanSquareError;
}
2、设置优化器
设置优化器,它实现了一个算法,根据损失函数的输出来修改我们的系数值。优化器的目标是最小化损失函数的输出值。
对于我们的优化器,我们将使用 随机梯度下降(SGD)。SGD的工作原理是利用我们的数据集中的随机点的 梯度,并利用其值来告知是否增加或减少模型系数的值。
TensorFlow.js 提供了一个用于执行 SGD 的便利函数,因此你必担心自己会执行所有这些数学操作。tf.train.sdg 作为输入一个期望的学习速率,并返回一个 SGDOptimizer 对象,它可以被调用来优化损失函数的值。
当需要提高期望值时,学习速率的高低控制了模型如何调整。低学习率会使学习过程更慢(需要更多的训练迭代来学习好的系数),而高的学习速率会加速学习,但可能会导致模型在正确的值周围振荡,总是要矫正。
下面的代码构造了一个学习速率为 0.5 的 SGD 优化器:
const learningRate = 0.5;
const optimizer = tf.train.sgd(learningRate);
3、循环训练模型
循环训练将迭代地运行优化器以减少损失。
现在我们已经定义了损失函数和优化器,我们可以构建一个训练循环,迭代地执行 SGD 以优化模型的系数以最小化损失(MSE)。如下:
function train(xs, ys, numIterations = 75) {
const learningRate = 0.5;
const optimizer = tf.train.sgd(learningRate);
for (let iter = 0; iter < numIterations; iter++) {
optimizer.minimize(() => {
const predsYs = predict(xs);
return loss(predsYs, ys);
});
}
}
让我们一步一步地仔细看看代码。首先,我们定义我们的训练函数,以获取数据集的 x 和 y 值,以及指定的迭代次数,作为输入;接下来,我们将定义学习速率和 SGD 优化器;最后,我们为运行 numIterations 训练迭代的循环设置了一个 for 循环。在每次迭代中,我们调用优化器的最小化。
minimize 函数,它做两件事:
- 它使用我们在第2步中定义的预测模型函数来预测所有 x 值的 y 值(predYs)。
- 它用我们之前定义的损失函数定义了那些预测的平均平方误差损失。
最小化然后自动调整这个函数使用的任何变量(系数a, b, c 和 d)以最小化返回值(loss)。
在运行我们的训练循环之后,a、b、c和d将包含在75次 SGD 之后的模型所学习的系数值。
结果展示
一旦程序结束运行,我们可以取变量a、b、c和d的最终值,并使用它们绘制曲线:
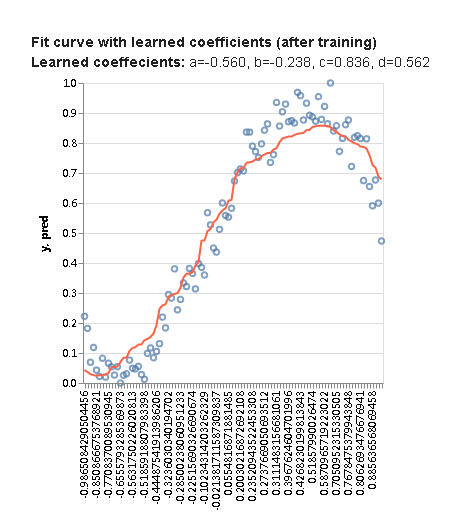
结果比我们最初用随机值计算系数的曲线要好得多。
戳我博客