拆解Tomcat10: (四) 图解架构
上一篇从Bootstrap类中的main方法开始了代码调试之旅,现在我们继续这个过程,看看Tomcat的核心组件架构。
1. 概述
本章来分享一下Tomcat都有哪些核心组件,以及它们之间的关系是什么样的。
其实这和我们熟悉的配置文件“server.xml”的结构基本是一致的。 此文件位置为“conf/server.xml”,部署Tomcat的时候经常会修改其中的配置。
按照此XML文件的结构画了一副结构图(各组件详细的功能不止于此,随着后期内容的深入会继续丰富这幅图。),大家看着更直观一些:
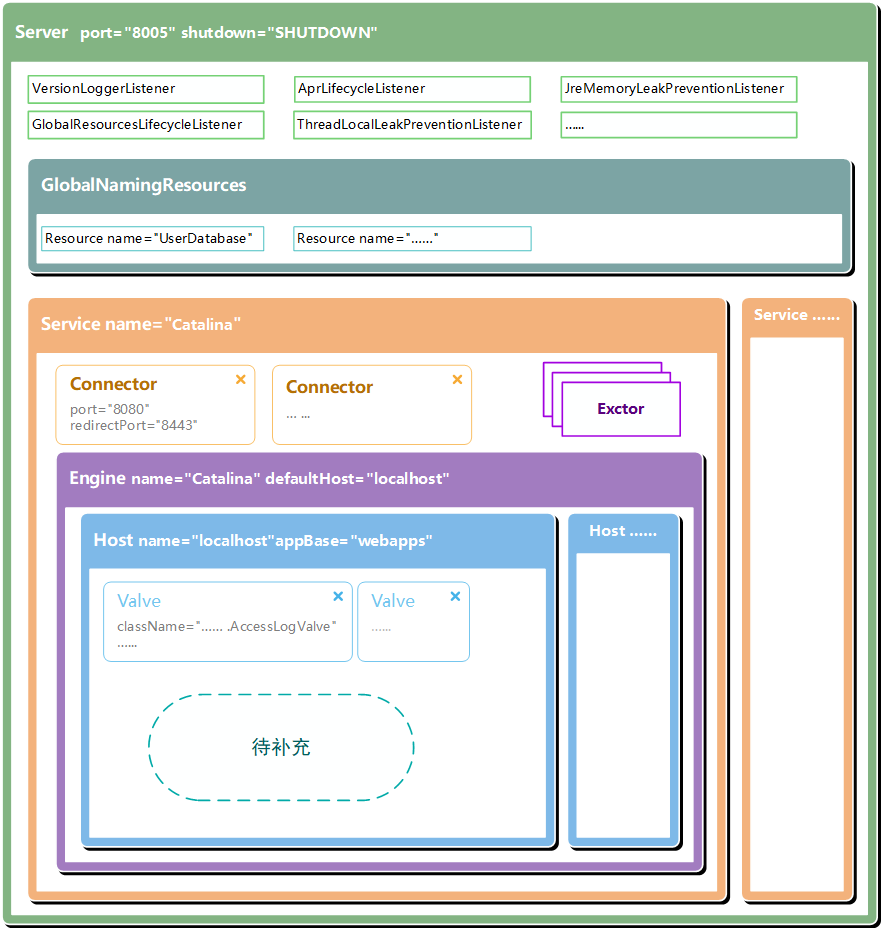
(图一)
2. 从main方法开始
上文最后讲到,main方法的最后一部分是根据启动Tomcat时传入的args进行判断的语句,若传入的参数为空,则默认为“start".,进入对应的语句块:
if (command.equals("start")) {
daemon.setAwait(true);
daemon.load(args);
daemon.start();
if (null == daemon.getServer()) {
System.exit(1);
}
}
核心就是调用daemon的setAwait、load和start三个方法,从上一篇我们已经知道,这些方法都会以反射的方式找到catalinaDaemon(对应Catalina类)的对应方法,传入参数进行调用,此处不再重复。
setAwait会调用Catalina类的setAwait方法,对await变量赋值,这个变量的具体作用后文会解释。
/**
* Use await.
*/
protected boolean await = false;
public void setAwait(boolean b) {
await = b;
}
public boolean isAwait() {
return await;
}
下面看一下load方法。
3. 按配置创建核心组件
daemon.load(args)方法会调用Catalina类d的load(String args[])方法进行参数处理,进而调用load()方法,其代码如下:
/**
* 创建并初始化一个新的 server 实例.
*/
public void load() {
if (loaded) {
return;
}
loaded = true;
long t1 = System.nanoTime();
// 初始化Naming,因为在使用 digester解析server.xml时或许会被使用到
initNaming();
// 解析 server.xml
parseServerXml(true);
Server s = getServer();
if (s == null) {
return;
}
//将当前对象(catalinaDaemon)赋值给新创建的Server的catalina属性
getServer().setCatalina(this);
//将Bootstrap类中初始化的CatalinaHome和CatalinaBase赋值给Server的对应属性
getServer().setCatalinaHome(Bootstrap.getCatalinaHomeFile());
getServer().setCatalinaBase(Bootstrap.getCatalinaBaseFile());
// Stream 重定向
initStreams();
// 初始化新的Server
try {
getServer().init();
} catch (LifecycleException e) {
if (throwOnInitFailure) {
throw new java.lang.Error(e);
} else {
log.error(sm.getString("catalina.initError"), e);
}
}
// 省略写日志的代码
}
3.1 initNaming()方法
用于设置附加的环境变量的值。主要涉及key为javax.naming.Context.URL_PKG_PREFIXES和javax.naming.Context.INITIAL_CONTEXT_FACTORY的两个变量。通过调用System.setProperty方法设置这两个Key对应的值。
javax.naming.Context.URL_PKG_PREFIXES
该常量的值为“java.naming.factory.url.pkgs”。它对应的Property值应该是一个以冒号分隔的包前缀列表,用于创建 URL 上下文工厂的工厂类的类名。
在initNaming()方法中,将"org.apache.naming"添加到冒号分隔的列表中。
javax.naming.Context.INITIAL_CONTEXT_FACTORY
保存环境属性名称的常量,用于指定要使用的初始上下文工厂。 该属性的值应该是将创建初始上下文的工厂类的完全限定类名。 该属性可以在传递给初始上下文构造函数的环境参数、系统属性或应用程序资源文件中指定。
在initNaming()方法中,将"org.apache.naming.java.javaURLContextFactory"设置为此Key的值。
3.2 parseServerXml方法
此方法的作用是解析Server.xml文件,
采用的解析工具为Digester。方法里有两个出现非常多的变量generateCode和useGeneratedCode:
- generateCode:从配置文件生成Tomcat内嵌代码。
- useGeneratedCode:使用生成的代码替代配置文件。
这两个变量可以在启动的时候通过main方法的args参数设置,默认状态下都是false,删掉相关代码,精简后的代码如下:
protected void parseServerXml(boolean start) {
// 设置对应的配置文件 即Server.xml
ConfigFileLoader.setSource(new CatalinaBaseConfigurationSource(Bootstrap.getCatalinaBaseFile(), getConfigFile()));
File file = configFile();
File serverXmlLocation = null;
String xmlClassName = null;
ServerXml serverXml = null;
if (serverXml != null) {
serverXml.load(this);
} else {
try (ConfigurationSource.Resource resource = ConfigFileLoader.getSource().getServerXml()) {
// 创建并执行 Digester
// createStartDigester 配置解析规则
Digester digester = start ? createStartDigester() : createStopDigester();
InputStream inputStream = resource.getInputStream();
InputSource inputSource = new InputSource(resource.getURI().toURL().toString());
inputSource.setByteStream(inputStream);
// 设置当前catalina对象为root节点
digester.push(this);
digester.parse(inputSource);
} catch (Exception e) {
log.warn(sm.getString("catalina.configFail", file.getAbsolutePath()), e);
if (file.exists() && !file.canRead()) {
log.warn(sm.getString("catalina.incorrectPermissions"));
}
}
}
}
大概处理流程总结如下:
- A. 设置并读取Server文件。
- B. 创建Digester,并调用createStartDigester()方法设置解析规则。
注意:设置解析规则的时候,指定了各个XML节点对应的接口的实现类,截取部分createStartDigester()方法中的代码如下
// server节点
digester.addObjectCreate("Server","org.apache.catalina.core.StandardServer","className");
digester.addSetProperties("Server");
digester.addSetNext("Server","setServer","org.apache.catalina.Server");
//service节点
digester.addObjectCreate("Server/Service","org.apache.catalina.core.StandardService","className");
digester.addSetProperties("Server/Service");
digester.addSetNext("Server/Service","addService","org.apache.catalina.Service");
实现类多以StandardXXX命名,例如StandardServer、StandardService、StandardThreadExecutor等。
关系图如下:
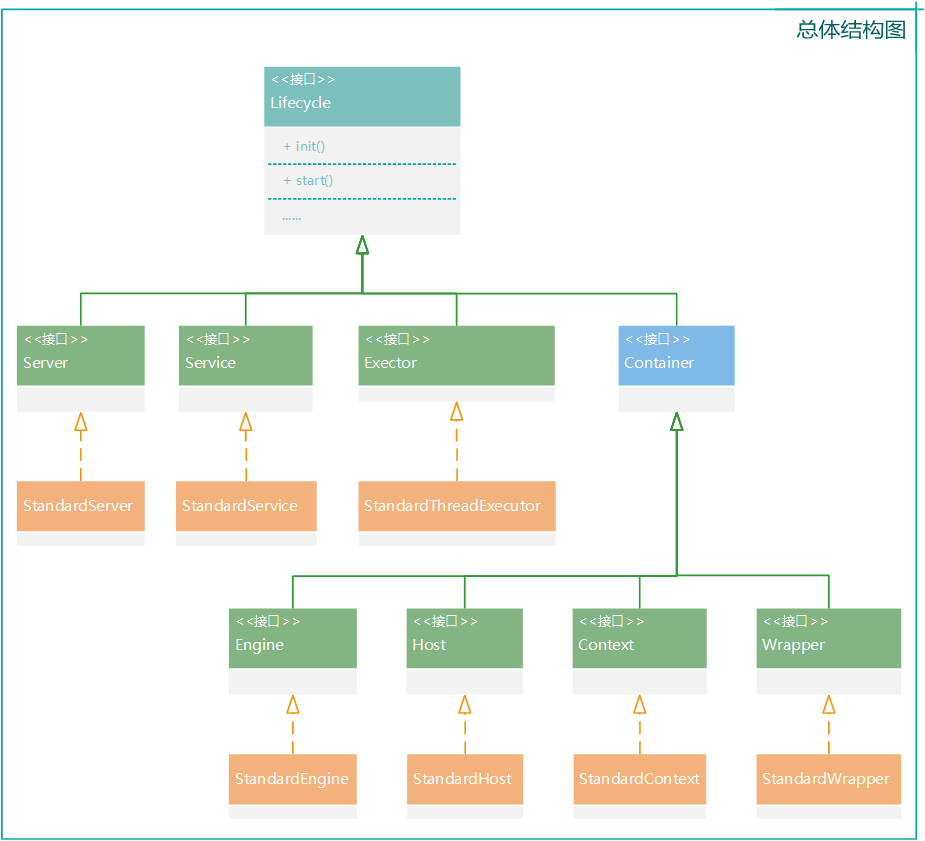
(图二)
- C. 设置当前catalina对象为root节点。
- D. 执行解析操作,此时会根据配置的规则,对应XML的节点创建对应的实现类的实例,注意此时只是执行了构造方法,未进行其他初始化操作。
3.3 Server的初始化
下一章继续进行getServer().init();方法的源码阅读,看一看都做了哪些操作,由图二所示,这些组件都实现Lifeycle接口,有什么想法?