【优化】Python pandas + redis 处理900w数据量导出excel,效率整整提升10倍!!
问题:
今天,在对一个900w数据量的excel进行导出操作的时候,遇到了 Out of Memory 内存不足,导致整个网页崩溃的问题。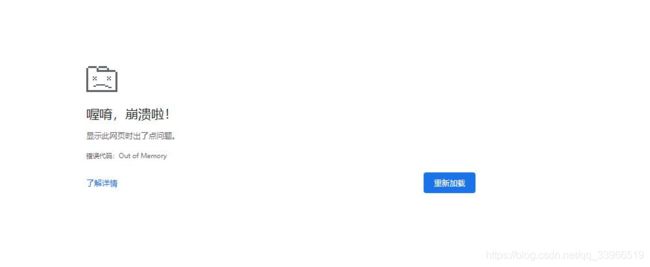
于是我度娘一通。对电脑的虚拟内存调高了一通,但是发现并没有效果。
难道真的要通过加内存条的方法来解决?当然这是一种方法,但是对于以后数据量越来越大的情况下,内存条就一直往上加吗,那显然是不可取的。
那么就只能对代码进行优化了。后来我发现,之前导出excel的形式,是通过后端将所有的900w数据全部返回到前端,前端再将数据进行缓存,通过layui excel模块进行导出。在数据量足够大的情况下,内存肯定是会爆掉的。
所以只能将数据在后端进行处理,在后端将数据写入excel,将文件下载url传回前端,对文件直接进行下载。
(因为有900w的数据量,所有我用redis将这些数据进行存储起来
后面为什么要用Decimal,因为float类型的数据会有精度问题)
# 实际有3w条数据,300个key,这边不一一写了
import redis
rdb = redis.Redis(host='localhost',port=6379,db=0,decode_responses=True)
res = [{'number':'001','name':'张三','hobby':'编程','score':Decimal('98.0')},
{'number':'002','name':'李四','hobby':'王者','score':Decimal('99.85')}]
for x in res:
hsname = x['number']
rdb.hset('stu', hsname, str(x))
rdb.lpush('stu_ls', hsname)
未优化前的代码:将所有数据统统装在数组中返回
@app.route('/calculate', methods=['GET')
def calculate():
list = rdb.lrange('stu_ls', 0, -1)
res = []
for x in list:
temp = eval(rdb.hget('stu', x))
res.append(temp)
count = len(list )
return json.dumps({"code": 0, "count":count,"data": res}, indent=4, sort_keys=True, default=str, ensure_ascii=False)
先看优化后的结果:
900w数据量,原本导出需要耗时15分钟左右,在经过优化后,导出耗时仅需101秒,这速度是原来整整的10倍!!!

优化思路:
import numpy as np
import pandas as pd
1、通过redis hvals() 获取所有数据,类型为 List
res = rdb.hvals(‘stu’)
2、将 List 转换为 numpy数组
arr = np.array(res)
3、因为reids中的数据是 str格式 ,即 ["{‘number’:‘001’,‘name’:‘张三’}","{‘number’:‘002’,‘name’:‘李四’}"] ,所以要用 eval() 将 字符 转换成 json格式
newArr = [eval(x) for x in arr]
4、利用pandas的 json_normalize 对json数据进行解析,将json串解析为 DataFrame格式
df = json_normalize(new)

5、利用pandas生成excel
writer = pd.ExcelWriter(’/file/学生名单.xlsx’, engine=‘xlsxwriter’)
df.to_excel(writer, sheet_name=‘Sheet1’)
writer.save()
6、但是,

7、利用pandas的astype,对一整列数据进行批量转化。这边列一下Pandas、Numpy、Python各自支持的数据类型。

df[‘score’].astype(“float”)
最后就是优化后的代码:
import pandas as pd
import numpy as np
import time
from pandas.io.json import json_normalize
@app.route('/calculate', methods=['GET'])
def calculate():
title = ['学号','姓名','爱好','成绩'] # 标题替换原英文
title_en = ['成绩'] # 需要转换格式的列
timev = time.strftime("%Y%m%d%H%M%S", time.localtime()) #设置时间,保证excel命名不冲突
res = rdb.hvals('stu')
arr = np.array(res)
newArr = [eval(x) for x in arr]
if len(newArr) > 0: # 如果有数据,则处理,否则返回空url
df = json_normalize(newArr)
df.columns = title # 更换中文标题
for x in title_en:
df[x] = df[x].astype("float")
writer = pd.ExcelWriter('/file/学生名单.xlsx', engine='xlsxwriter')
df.to_excel(writer, sheet_name='Sheet1')
writer.save()
return json.dumps({"code": 200,"url":'/file/学生名单.xlsx'}, indent=4, sort_keys=True, default=str, ensure_ascii=False)
else:
return json.dumps({"code": 200,"url":''}, indent=4, sort_keys=True, default=str, ensure_ascii=False)