项目背景
在今天产品高度同质化的阶段,市场竞争不断加剧,企业与企业之间的竞争,主要集中在对客户的争夺上。“用户就是上帝”促使众多企业不惜代价去争夺尽可能多的新客户。但是,在企业不惜代价发展新用户的过程中,往往会忽视老用户的流失情况,结果就导致出现新用户在源源不断的增加,辛苦找来的老用户却在悄无声息的流失的窘状。
如何处理客户流失的问题,成为一个非常重要的课题。那么,我们如何从数据汇总挖掘出有价值的信息,来防止客户流失呢?
行业情况:携程曾占据在线酒店的主要市场,但是随着美团在2017年加入,格局很快被打破
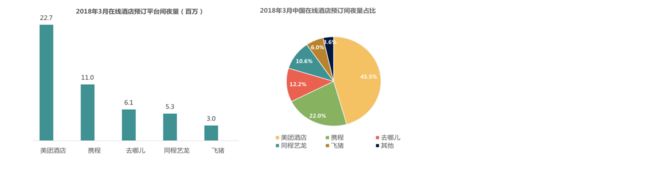
从下图可以看出:行业Top3的用户重合率较低,用户差异度明显。用户与市场竞争具有很大的相关性。

项目目标
- 挖掘用户流失的关键因素
- 预测客户的转化效果
- 用户画像
项目方案
- 使用pandas,numpy,sklearn.processing对数据进行预处理
- 使用LogisticRedression和DecisionTreeClassifier预测
- 用K-Means对用户进行画像,针对不同用户类别,提出可行建议
项目流程
- 数据预处理
- 衍生变量
- 删除缺失比列>80%的列
- 过滤无用维度
- 异常值负数处理
- 缺失值填充
- 极值处理
- 相关性
- 标准化处理
- 建模预测
- LogisticRedression预测
- DecisionTreeClassifier预测
- 结果可视化
- 用户画像
- 用K-Means对用户进行画像
- 数据预处理
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('userlostprob.txt',sep = '\t')
df.info() #查看数据信息
df.head() #查看前5行数据
df.describe() #查看数值型数据描述统计信息
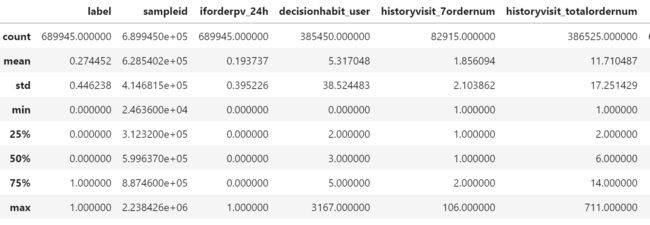
看一下每個特徵的含義,最大最小值
特徵含義在https://www.jianshu.com/p/c77d4f4cea3c拿的
maxx = [] #放最大值的列表
minn = [] #放最小值的列表
for i in df.columns: #遍歷
maxx.append(df[i].max()) #插入
minn.append(df[i].min())
data = pd.DataFrame(df.columns,columns = ['name']) #dataframe生成
chinese = pd.read_csv('description.csv') #讀取之前爬的含義列表
chinese = chinese.drop(['Unnamed: 0'], axis=1) #刪一下第一行,之前標題沒處理好= =
chinese = chinese.drop([0]) #爬完然後to_csv處理沒注意,多了一列索引
data = pd.merge(chinese,data, on='name') #xxxjoinxxx on xxx =xxx
data['max'] = maxx
data['min'] = minn


晚些再對著這個表幹活,現在看看缺失情況
data_count = df.count() #計算個屬性的非空值數量
na_count = len(df) - data_count #空值數量 = 總量 - 非空值
na_rate = na_count/len(df) #空值占比 = 空值數量/總量
a = na_rate.sort_values(ascending=True) #控制占比的排序 基於上面的排序默認是從低到高
#按values正序排列,不放倒序是为了后边的可視化展示排列
a1 = pd.DataFrame(a)
a1.head()
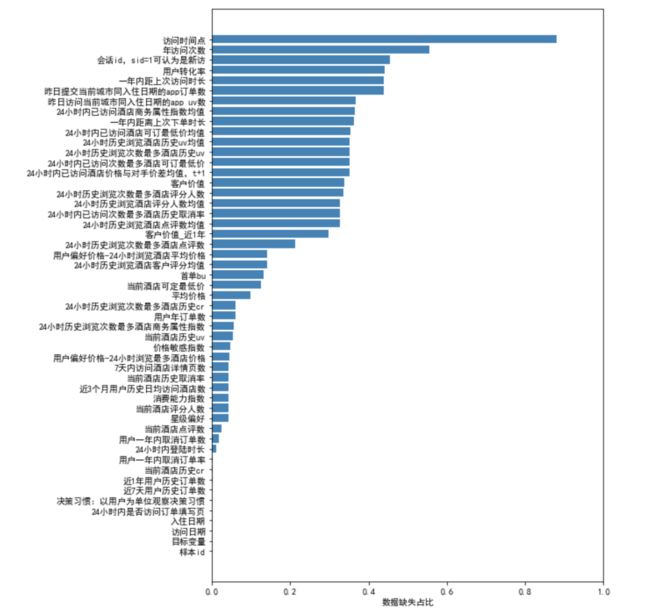
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
x = df.shape[1] #有幾個屬性?
fig = plt.figure(figsize=(8,12)) #設置畫布大小
plt.barh(range(x),a1[0],color='steelblue',alpha=1) ##框架句,(51條屬性,缺失占比,藍色)
plt.xlabel('数据缺失占比') #添加轴标签
#英文列名称
#columns1 = a1.index.values.tolist()
#中文列名称
columns1 = data['chinese'].values.tolist()
plt.yticks(range(x),columns1)
plt.xlim([0,1]) #设置X轴的刻度范围
plt.show()
。。。有點多
数据预处理
衍生变量
删除80%+缺失值列
过滤无用维度
异常值负数处理
缺失值填充
极值处理
首先回顧一下表格
再回顧下之間的df.info()

對時間為object的進行處理
df['d'] = pd.to_datetime(df['d'])
df['arrival'] = pd.to_datetime(df['arrival'])
删除缺失值比列88%的列historyvisit_7ordernum
df = df.drop(['historyvisit_7ordernum'],axis=1)
處理酒店流失問題,判定哪些特徵有無用,可以刪掉,並取新列
從日期開始後面的指標乍一看都好像很有用,那前邊的幾個呢,
ld已有索引,沒有重複 可以刪掉
label後面留著算法驗證要用
訪問日期和入住日期乍看似乎沒有用,但似乎可以構成一個新的維度
就是提前了幾天訂酒店,似乎日常上越晚訂越不會流失
可以嘗試引入一下,并把這兩個刪掉
#引入
df['Advance booking'] = (df['arrival']-df['d']).dt.days
#無用的維度
filter_feature = ['sampleid','d','arrival']
feature = []
for x in df.columns:
if x not in filter_feature:
feature.append(x)
df_x = df[feature]
df_y = df['label']
异常值负数处的处理
#查找那些屬性有負數值
a = []
for i in range(len(data['min'])):
if type(data['min'][i]) == str: #遍歷查找非int和float的值
a.append(i) #得到索引
data = data.drop(labels=a,axis=0) #利用索引刪掉
data = data.reset_index() #重構索引
for i in range(len(data)):
if data['min'][i] < 0:
print(data['name'][i])

共6列有负值,
但其中deltaprice_pre2_t1(24小时内已访问酒店价格与对手价差均值)正常,
所以其余5列,分别为
客户价值 (ctrip_profits)
客户价值近1年 (customer_value_profit)
用户偏好价格-24小时浏览最多酒店价格(delta_price1)、
用户偏好价格-24小时浏览酒店平均价格(delta_price2)、
当年酒店可订最低价(lowestprice)
根據各特徵情況
客户价值近1年 (customer_value_profit)、
客户价值 (ctrip_profits) 替换为0
用户偏好价格-24小时浏览最多酒店价格(delta_price1)、
用户偏好价格-24小时浏览酒店平均价格(delta_price2)、
当年酒店可订最低价(lowestprice)按中位数处理
df_x.loc[df_x.customer_value_profit<0,'customer_value_profit'] = 0
df_x.loc[df_x.ctrip_profits<0,'ctrip_profits'] = 0
df_x.loc[df_x.delta_price1<0,'delta_price1'] = df_x['delta_price1'].median()
df_x.loc[df_x.delta_price2<0,'delta_price2'] = df_x['delta_price2'].median()
df_x.loc[df_x.lowestprice<0,'lowestprice'] = df_x['lowestprice'].median()
缺失值填充
查看数据分布情况
for i in range(0,48):
#df_x.columns = data['chinese'] #中文化
plt.figure(figsize=(2,1),dpi=100)
plt.hist(df_x[df_x.columns[i]].dropna().get_values())
plt.xlabel(df_x.columns[i])
plt.show()
注意他們的分佈情況

趋于正态分布的字段,用均值填充:字段有businesstate_pre2,cancelrate_pre,businessrate_pre;
fill_list = ['businessrate_pre','businessrate_pre2','cancelrate_pre']
for i in fill_list:
df_x[i] = df_x[i].fillna(df_x[i].mean())
#df_x['businessrate_pre2'] = df_x['businessrate_pre2'].fillna(df_x['businessrate_pre2'].mean())
#這個是平均數替補
右偏分布的字段,用中位数填充
def filling(data):
for i in range(0,48):
df_x[df_x.columns[i]] = df_x[df_x.columns[i]].fillna(df_x[df_x.columns[i]].median())
return df_x
filling(df_x)

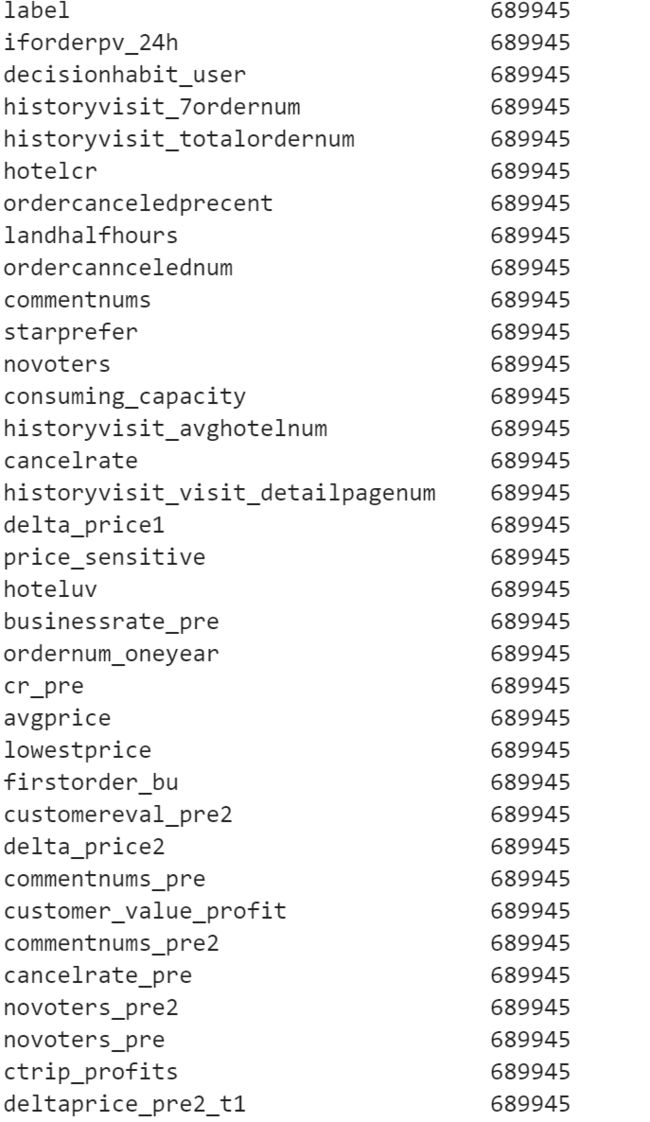
看看情況
df_count2 = df_x.count()
df_count2
data_count2 = df_x.count()
na_count2 = len(data_x) - data_count2
na_rate2 = na_count2/data_count2
aa2 = na_rate2.sort_values(ascending=False)
a3 = pd.DataFrame(aa2)
极值处理
盖帽法:某连续变量6西格玛之外的记录用正负3西格玛值替代,一般正负3西格玛包含99%的数据,所以默认凡小于百分之一分位数和大于百分之九十九分位数的值用百分之一分位数和百分之九十九分位数代替,俗称盖帽法
就是切比雪夫定理啦

data1 = np.array(data_x) #将data_x替换成numpy格式
for i in range(0,len(data1[0])): #列循环,以便取到每列的值
a = data1[:,i] #将每列的值赋值到a
b = np.percentile(a,1) #计算1百分位数据
c = np.percentile(a,99) #计算99百分位数据
for j in range(0,len(data1[:,0])):
if a[j] < b:
a[j] = b
elif a[j] > c:
a[j] = c
else:
a[j]
data1 = pd.DataFrame(data1,columns=feature)
dat = pd.concat((data1['consuming_capacity'],data1['customer_value_profit'],data1['ordercanncelednum'],data1['ordercanceledprecent'],data1['ctrip_profits'],data1['historyvisit_totalordernum'],data1['lastpvgap'],data1['lasthtlordergap']),axis=1)
dat.to_csv('rfm.csv',index=False)
檢查分佈情況
#检查处理后数据(极值和负值)
#箱线图检查极值
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
for i in range(0,48):
plt.figure(figsize=(4,8),dpi=100)
plt.boxplot(data1[data1.columns[i]].dropna().get_values())
plt.xlabel(data1.columns[i])
plt.show()
#查看最小值是不是负数
list_check = ['ctrip_profits','customer_value_profit','delta_price1','delta_price2','lowestprice']
for i in list_check:
print(data1[i].min())

最後情況

数据来源:链接:https://pan.baidu.com/s/1QDYDICb2Jo2pKgD98aDY2A
提取码:wawf
冠軍文章:https://cloud.tencent.com/developer/article/1063197