python不使用框架编写神经网络实现手写数字识别
实验目的及要求
目的:不使用框架, 用python实现神经网络, 学习算法最好的方法就是实现它, 掌握反向传播算法的推导及代码实现,掌握Xavier初始化、Adam算法、数据归一化、batch-normalization、dropout等技术。
要求:实现给定结构和指定初始化和学习算法的网络,不能使用现成的机器学习库,可以使用numpy库,对比1. 有无归一化。2. 有无batch-normalization。3. 有无dropout。的损失曲线和混淆矩阵。
实验环境及采用技术
实验环境:windows10,pycharm,python3.7,mnist数据集,numpy,random。
采用技术:Xavier初始化、Adam算法、数据归一化、batch-normalization、dropout。
数据集
mnist.pkl.gz
下载地址
网络结构
- 输入:28*28
- 隐藏层: 两层每层512各结点,激活函数:双曲正切函数
- 输出层: 10个结点,激活函数:softmax
Xavier初始化公式
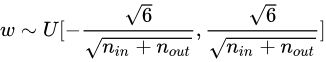
权值学习:Adam算法
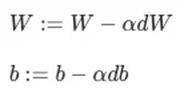
梯度下降(左:Momentum, 右:RMSprop)
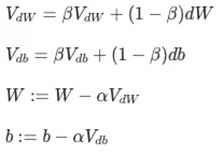
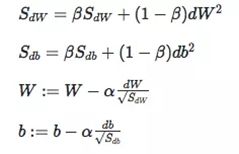
结合起来
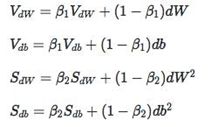
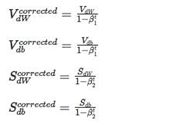
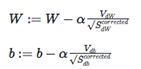
损失函数:交叉熵损失函数
训练结果对比:
是否采用输入数据归一化的对比(同样的前提即Xavier初始化、Adam算法)
左:使用归一化的损失曲线
右:未使用归一化的损失曲线
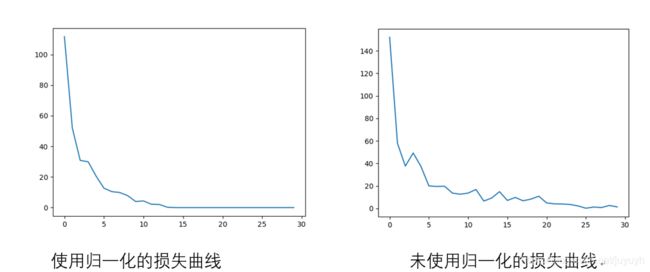
可以看出使用输入数据归一化的收敛快,震荡效果也少一些,曲线更为平滑。
对应混淆矩阵
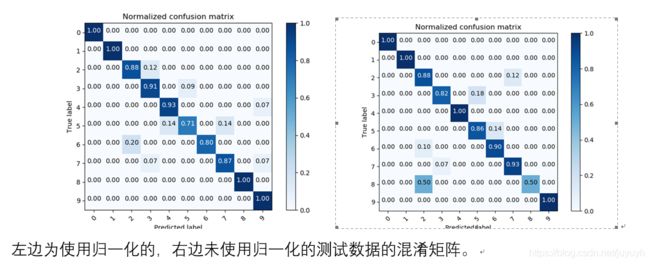
可以看出使用归一化对测试数据的预测效果好一些,预测的准确率更高。
是否采用dropout的对比(同样的前提即Xavier初始化、Adam算法、使用了归一化)
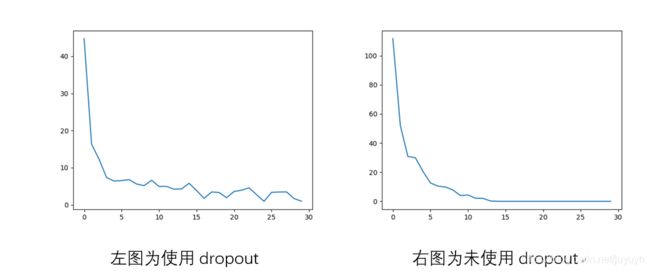
可以看出使用dropout的前面下降的快,但后面下降的慢且震荡的大,优点和不足都非常明显。
使用dropout后对训练和测试数据的混淆矩阵为
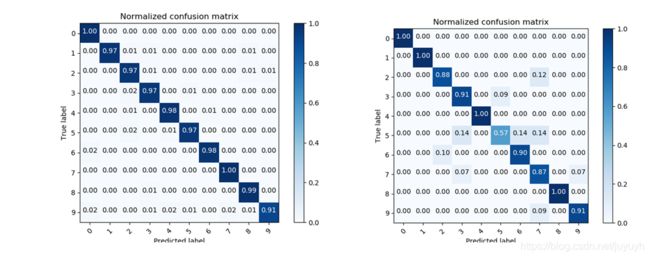
是否采用batch normalization的对比, 没有做出来
源码(NetWork类)
class Network(object):
def __init__(self, sizes):
"""初始化参数"""
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = None
self.weights = None
# self.random_parameter_init()
self.xavier_parameter_init()
def xavier_parameter_init(self):
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
self.weights = []
for i in range(1, self.num_layers):
low = -np.sqrt(6.0 / (self.sizes[i - 1] + self.sizes[i]))
high = np.sqrt(6.0 / (self.sizes[i - 1] + self.sizes[i]))
self.weights.append(np.random.uniform(low, high, (self.sizes[i], self.sizes[i - 1])))
def random_parameter_init(self):
# (y, 1)生产列向量,且服从
self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]]
# x为该层节点数,y为前一层的节点数也就是该层的输入数
self.weights = [np.random.randn(y, x) for x, y in zip(self.sizes[:-1], self.sizes[1:])]
def test(self):
print("biases:", self.biases)
print("weights type:", type(self.weights))
print("weights:", self.weights)
print(list(zip(self.biases, self.weights)))
print("b.shape", self.biases[1].shape)
print("w.shape", self.weights[2].shape)
def feedforward(self, a, ):
"""Return the output of the network if ``a`` is input."""
"""遍历的是非输入层,b是该层的偏置数组,w是该层的权重数组"""
"""遍历完一次即完成一次向前传播"""
for b, w in list(zip(self.biases, self.weights))[:-1]:
a = tanh(np.dot(w, a) + b)
# 最后一层采用softmax激活
a = softmax(np.dot(self.weights[-1], a) + self.biases[-1])
# for b, w in zip(self.biases, self.weights):
# a = sigmoid(np.dot(w, a)+b)
return a
def Adam(self, training_data, epochs, mini_batch_size, eta, test_data=None):
"""
training_data:训练数据
epochs:迭代次数
mini_batch_size:块大小
eta:学习率
test_data:测试数据
"""
'''随机梯度下降'''
if test_data:
n_test = len(test_data)
n = len(training_data)
losses = []
# 循环一次即迭代一次
for j in range(epochs):
# 将所有元素随机排序
random.shuffle(training_data)
# 将所有训练数据按块大小划分成块形成一个块列表
mini_batches = [training_data[k:k+mini_batch_size] for k in range(0, n, mini_batch_size)]
# 对块列表进行遍历,每个块进行反向传播,并更新参数
for i, mini_batch in enumerate(mini_batches):
nabla_b_g, nabla_w_g = self.mini_batch_backprop(mini_batch)
beta1 = 0.9
beta2 = 0.999
eps_station = 1e-10
# 初始化m,v
b_m = [np.zeros(b.shape) for b in self.biases]
w_m = [np.zeros(w.shape) for w in self.weights]
b_v = [np.zeros(b.shape) for b in self.biases]
w_v = [np.zeros(w.shape) for w in self.weights]
b_res = [np.zeros(b.shape) for b in self.biases]
w_res = [np.zeros(w.shape) for w in self.weights]
for index in range(self.num_layers-1):
b_m[index] = beta1 * b_m[index] + (1 - beta1) * nabla_b_g[index]
b_v[index] = beta2 * b_v[index] + (1 - beta2) * nabla_b_g[index] ** 2
m_bar_b = b_m[index] / (1 - beta1 ** (i + 1))
v_bar_b = b_v[index] / (1 - beta2 ** (i + 1))
b_res[index] = eta * m_bar_b / (np.sqrt(v_bar_b) + eps_station)
w_m[index] = beta1 * w_m[index] + (1 - beta1) * nabla_w_g[index]
w_v[index] = beta2 * w_v[index] + (1 - beta2) * nabla_w_g[index] ** 2
m_bar_w = w_m[index] / (1 - beta1 ** (i + 1))
v_bar_w = w_v[index] / (1 - beta2 ** (i + 1))
w_res[index] = eta * m_bar_w / (np.sqrt(v_bar_w) + eps_station)
self.weights = [w - nw for w, nw in zip(self.weights, w_res)]
self.biases = [b - nb for b, nb in zip(self.biases, b_res)]
loss = self.get_loss(training_data)
losses.append(loss)
# 执行一次迭代用测试数据检测一次正确率
if test_data:
print("Epoch: {0} loss: {1} acc: {2}/ {3}".format(j, loss, self.evaluate(test_data), n_test))
else:
print("Epoch {0} complete".format(j))
return losses
def get_loss(self, training_data):
# loss = log(e, s_max)
loss = 0
for x, y in training_data:
y_pred = self.feedforward(x)
s_max = y_pred[np.argmax(y_pred)]
loss += -1*np.log(s_max)
return loss
def mini_batch_backprop(self, mini_batch):
X = np.array([x.reshape(784) for (x, y) in mini_batch])
Y = np.transpose(np.array([y.reshape(10) for (x, y) in mini_batch]))
# 初始化b,w
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# 向前传播
activation = np.transpose(X)
# 存放每层的输入,上一层的结果
activations = [activation]
# 存放每层未激活的结果(向量)
zs = []
for b, w in list(zip(self.biases, self.weights))[:-1]:
# 向前一层的计算存储相应的数据
z = np.dot(w, activation) + b
zs.append(z)
activation = tanh(z)
activations.append(activation)
# 最后一层用softmax
z = np.dot(self.weights[-1], activation) + self.biases[-1]
zs.append(z)
activation = softmax(z)
activations.append(activation)
delta = activations[-1] - Y
# 各列相加保持维度不变
nabla_b[-1] = np.sum(delta, axis=1, keepdims=True)
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in range(2, self.num_layers):
z = zs[-l]
sp = tanh_prime(z)
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
nabla_b[-l] = np.sum(delta, axis=1, keepdims=True)
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
nabla_b_g = [nb / len(mini_batch) for nb in nabla_b]
nabla_w_g = [nw / len(mini_batch) for nw in nabla_w]
return nabla_b_g, nabla_w_g
def evaluate(self, test_data):
test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def softmax(z):
return np.exp(z) / np.sum(np.exp(z))
def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
def tanh_prime(x):
return 1-(tanh(x))**2
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
# sigmoid的导数
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))
项目源码