在介绍之前,首先感谢组内小伙伴提供的资料,让我有机会学习,得到自己的理解,如果有理解不对的地方或者有更好的解决方案以及想法,欢迎一起交流,感激不尽
ACM介绍
"ACM"是蘑菇街算法数据流的总称,主要包含四个模块:埋点模块、ab实验模块、数据清洗模块、数据聚合模块,通过这四个模块解决蘑菇街搜索(广告与自然)、反作弊算法组同学的对各种数据收集、分析需求,帮助算法同学迭代算法模型,提升算法效果的目的
Tips:ACM的名称,参考了淘宝的打点参数SCM;同时由于与ACM竞赛同名,也蕴含了"算法"的意义。
ACM的发展史
2016.03 TOPN层改造,为每个商品增加ACM字段覆盖所有图墙(包括自然与广告的类目、搜索)相关业务
|
2016.05 团购、推荐+麦田达尔文系统增加ACM字段覆盖猜你喜欢等相关推荐业务,资源位相关业务
|
2016.07 蘑菇街PC店铺内图墙、美丽说、淘世界经过整合后与蘑菇街保持一致,使用ACM打点方式,覆盖到淘世界图墙、美丽说图墙
|
2016.09 蘑菇街app店铺内图墙、快抢等业务加入ACM打点逻辑,同时蘑菇街魔方数据接入ACM打点数据,ACM开始进入全站打点行列
|
......
ACM出现的背景
背景
对于算法策略组的同学经常需要收集用户的行为数据进行算法模型的回归,不断的通过样本数据来调参使得算法模型预测更加准确,但是不同业务场景的算法模型需要筛选相关的样本数据才会使得模型效果更佳,对于样本数据的筛选过程对应到日常流程大体需要经过三个系统模块:后端服务链路、用户行为追踪链路、行为数据采集以及清洗链路。后端服务链路,目前大部分的业务场景是3,4层:业务层,投放层,引擎层, 每个层涉及到的业务系统较分别对应到很多不同的小团队,每层链路之间要协商如何将数据进行标记和定义。用户行为追踪链路也同样涉及到很多业务团队,如何约定规则以及对应后端标记数据传递到曝光、点击、交易行为链路, 其中曝光行为的收集还存在一定的状态。后端采集链路需要大量的清洗工作、风控环节、系统的高可用、实时性等这些之后从而完成算法训练阶段的行为样本数据的筛选。
算法数据流
从背景中我们了解到,数据大致会经过三个系统模块,这三个大的系统模块中又包含了很多子服务层,下面我以服务层来描述一个完整的数据流转图,如下:
在数据流转图中,在左边的每一个层级都包含诸多子服务,每个子服务在线上都会存在数据打点需求,比如对于“投放推荐层"来说,主要有搜索和推荐两条线,每条线都需要进行数据源信息打点、算法同学的算法实验信息打点;“业务层”有针对各种业务信息的打点;“前端”有一些针对UI策略AB的打点。这些打点数据最终都会在前端进行收集,然后通过统一的日志服务器收集后进行各自的数据清洗和分析,这意味着在右边的每一个层级,都会存在与左边服务相对应的清洗服务。
存在的问题
从背景以及算法数据流中可以看出,数据的一次完整流转流程,涉及到每一个环节的数据打点,最终透出到页面端,通过页面端进行数据收集。而在缺乏ACM的情况下会存在以下问题:
- 各个系统之间的打点方案不一致,导致后续对数据进行清洗时存在多个逻辑
- 系统涉及透传链路越长,可靠性越差(特别是底层算法同学的打点数据)
- 出现透传问题时,排查困难
- 相似工作在多个团队之间存在重复
举个数据打点例子
打点需求1:
算法组的小q同学想要在数据流中增加一个打点参数A(位于投放推荐层)
做法:小q通知上游的业务层(投放层、图墙业务层、前端层)同学,我要增加打点参数A,你们处理数据的时候记得帮我透传一下
实现:业务层(投放层、图墙业务层、前端层)同学吭吭哧哧改透传逻辑代码
打点需求2:
投放组的小w同学想要在数据流中增加一个打点参数B
做法:小w通知下游的业务组、前端组同学:我要增加打点参数B了,你们处理数据的时候记得帮我透传一下
实现:业务组、前端组的同学吭吭哧哧改透传逻辑代码
打点需求XXX
、、、、
前端同学:停!谁再提打点的事我就从天台跳下去!
众人:行行行,高处风大,你先下来,都好说.....
ACM的目标
初期目标
主要解决算法训练数据的筛选以及统计困难问题(服务算法策略同学)
最终目标(全站标准化)
- 承担全站曝光打点的使命,通过统一数据链路来保障数据口径一致
- 提高打点的准确性以及可维护性
- 为算法策略&BI团队&数仓提供可靠的数据链路
- 通过监控快速发现并定位埋点丢失问题
- 为整个数据链路提供相关通用服务(如算法数据源、ab报表、其他实时统计数据)
ACM的实现方案
具体方案
在背景与目标中,我们已经了解到我们所面对的问题以及我们需要达到的目标,所以具体的实现分为两个阶段:1、实现初期目标;2、在初期的基础上,往全站标准化发展。
一期主要完成一些基础的功能模块,以解决算法数据收集需求。在ACM的介绍部分,对各个模块就有所提及,一共分为四大块:acmSDK(埋点)、ABTest(ab实验支持)、acmEtl(数据清洗)、acmAgg(数据聚合),按照各个模块的性质总的又分为两个方面:1、在线部分(acmSDK、ABTest);2、离线部分(acmEtl、acmAgg)
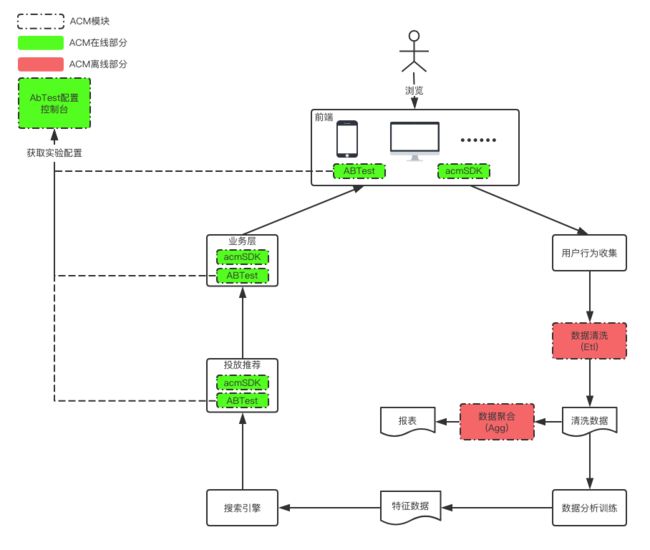
各部分解决的问题(系统实现以后有机会补上)
acmSDK
1、提供统一的打点API,提供到各个有打点需求的业务系统(统一打点口径)
2、统一打点数据格式(增加acm字段,作为透传打点数据的载体)
acm字段格式定义
版本.业务域.站点_内容类型_内容.资源位.实验.签名.自定义值
acm字段举例
3.mce.1_4_1kdf96m.39084.30655-30653.qtIkXqnaRktq3.p_11_615935107-mid_39084-lc_201
abTest
1、为算法同学提供灵活的ab配置
2、提供统一的ab配置管理平台
acmEtl
1、按照acm字段的格式定义对数据进行解析
2、按照不同的维度产出不同的数据表
acmAgg
1、按照不同的指标对数据进行统计
2、报表产出
ACM上线后带来的收益
ACM引入以后:
- 大幅度节省了算法组进行数据分析时,在打点、数据清洗工作上的投入
- 降低打点协商的成本,去掉打点导致的全流程代码变更,提升了全站的开发效率
后端同学:打点变得方便可靠,不再因为增加一个打点参数,而需要一一通知上下游了。
前端同学:按照ACM定义规则进行单次开发,就不用为打点规则变更而频繁修改代码啦!
两个成功的案例:
案例说明:
a.新品冷启动问题(EE项目)
b.广告轮询出造成的问题
案例a
新商品往往只能与常规商品共同展示。但由于排序分的缺少,排序靠后,无法与常规商品竞争流量。EE项目在保障不对用户有过多体验伤害的前提下,针对新品
给予一定的曝光机会。通过曝光期用户对该新品的一些行为数据,确定他是否具有成为爆款或者是具有较好发展前景。如果能够进入下一个阶段就会基于更多
的展现机会,否则进行淘汰。经过第二个阶段的商品通常会已经进行了一段时间的曝光,排序分也有了一定的提升,可以正常的纳入到常规排序模型。形式表现
在图墙上面对一小部分用户做a/b,让其看到的部分商品中包含一定的新品数量。这个过程我们需要标记哪些商品是新品,需要将标记传递到各个行为,收集完成
针对性的训练。
案例b
在某些查询条件下,广告数量有限为了不影响广告的收入,我们需要将展现过的商品重新展现。但是首次看到商品点击意愿度和第二次看到点击的意愿度是不一
样的,此时不能用相同的分析策略去处理两类点击行为。为了分析这种场景下的用户行为,我们需要对广告出现的次数进行标记。
ACM需要注意的问题
1、acm格式的定义需要在扩展性上有足够的考虑。从整个方案中可以看出acm字段格式虽然由acmSDK统一管控,但是分布面很广,因此升级acm字段的格式代价是很大的,从在线部分的改动升级,到线上多个版本共存离线部分处理的兼容,工作量都很大,稍不注意就会带来大面积的ACM问题
2、ACM的稳定性需要得到很好的保障,在ACM前期上线后,经常出现数据问题,导致算法训练是数据不可用
3、自定义值的管控,一是ACM使用者众多,缺少自定义值的管控是非常危险的,很容易导致acm字段值的长度暴增,二是各个层级之间的扩展参数名可能会存在重复的情况,不妥善管理则会存在覆盖问题,导致字段值丢失
4、在线部分埋点需要进行监控,能及时发现以及定位问题(对于跨多级的长链路中,缺少必要信息的情况下查询问题是一件苦恼的事)
5、acm字段最好能记录整个后端到前端所经过的链路,对后续问题查询很有帮助