从 JIT 编译看 Runtime 的过去与未来
作者简介
常开颜
中国科学院计算技术研究所直博生,研究方向为硬件编程语言、编译技术。
如果读者想了解更多有关 Runtime 相关的技术内容,欢迎加入编程语言社区 SIG-Runtime。
加入方式:文末有小助手微信,添加并备注加入 SIG-Runtime。
# 编译器是什么 #
编程语言处理器可以分为三类,它们之间的关系用一句著名的话说就是:编译器是特化的解释器(a compiler is a specialized interpreter)[1]。
-
编译器 Compiler 能够给定一种语言的程序,输出另一种语言里的等价程序(编译过程会生成新的程序)
-
解释器 Interpreter 能够给定一个程序和程序的输入,计算程序的结果(解释过程不生成新的程序)
-
特化器 Specializer 能够给定一个程序一些提前知道的输入,创建一个仅需要剩下输入的等价(但更高效)的程序
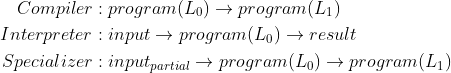
注:![]() :即计算机实际执行的语言
:即计算机实际执行的语言
作为一篇科普性质的综述类文章,本文不打算挖掘深度,而是注重广度,聚焦于提供一个 Runtime 的领域蓝图。就像 J.R.R.Tolkien 所说:"你必须有一张地图,不管多么粗糙。否则你会四处游荡。(You must have a map, no matter how rough. Otherwise you wander all over the place.)"
# Runtime 是什么 #
Runtime 包括了 动态程序的相关理论 和 程序运行时的支持系统:
-
动态程序的相关理论 指程序动态特性相关的编程语言理论,比如动态程序验证,运行时并发程序的动态验证等;
-
运行时支持系统 runtime system 指保障程序在运行时正确执行的支持系统,比如垃圾回收系统、即时编译系统、处理器系统等。
由于编程语言的运行不仅需要软件系统的支撑,也需要硬件系统的支撑,因此 Runtime 涉及了软件和硬件层次的许多交叉方面。此外,Runtime 不仅与通用编程语言有关,也与领域特定语言有关。在近来兴起的深度学习编译器中,许多框架都用到了即时编译系统,比如 PyTorch。在云计算兴起的时代,在可编程网络领域也广泛用到了编程语言作为接口对设备进行配置,比如阿里云太玄 OS 的跨平台编程语言和编译器 Lyra [2]。
考虑到 Runtime 是一个涉及编程语言理论、体系结构、程序分析等的综合领域,本文按照应用领域把相关的研究大致分为以下六个领域(如下图所示),下面对每一个领域做说明。

Runtime 应用领域概览
编译器运行时
编译器运行时属于传统的程序运行时支持系统,包括了通用语言虚拟机及其 JIT 编译,比如:JVM、V8 等。
在传统的编译器运行时中,一个很大的部分是 垃圾回收技术(Garbage Collection),由此衍生出了 三色标记法、标记清扫法、引用计数法 等不同的垃圾回收方法。
其他和编程语言特性相关的特性还包括了反射、虚函数等。
涉及到的其他程序运行时的行为还有 并发 和 事务。
同时编译器运行时也涵盖了领域特定语言(Domain Specific Language)及其 JIT 编译。领域特定语言是专用于某一个领域的编程语言,分为嵌入式领域特定语言和外部领域特定语言,嵌入式领域特定语言包括 Halide、TVM、Tensorflow、JAX 等,外部领域特定语言包括:云原生编程语言 Ballerina,硬件描述语言 Verilog、VHDL。
动态程序验证
动态程序验证与静态验证基于不同的系统。静态程序的验证一般是从作用域、类型等抽象特性上验证程序的语义是否符合规范,而动态验证则更为灵活。
从理论上讲,可以归结为 动态语义的验证,比如采用 霍尔逻辑(Hoare Logic) 验证数据结构的正确性,验证循环的正确性;还可以使用 混合符号执行(Concolic Testing) 来测试程序,缩减符号执行造成的搜索空间爆炸的问题,比如使用混合符号执行 fuzzing。
从实践上讲,在 JVM 中,类的加载阶段需要进行验证,比如采用变量类型执行的方式,把变量的类型压入虚拟机栈,在类型执行时判断栈顶类型是否匹配。
动态程序分析
动态程序分析是对程序的动态行为进行分析,从而定位程序故障、进行调试或是进行更为激进的优化。在调试模式中,LLVM 采用 程序插桩 的方法,在局部变量的前后插桩方便调试时查看它们的值。LLVM 也采用了其他方法来加快程序的运行速度,比如收集性能制导优化的 profile,在每个分支指令后标注类似 !prof !0 的标识插入分支相对可能执行次数的元信息来辅助提高程序执行速度。还可以在程序运行时分析存储的读写序列发现访存冲突问题。
动态程序合成
动态程序的合成可以分为两类,一种是 交互式程序合成,比如微软在 Excel 中的自动填充技术,可以根据已经存在的单元格数据提取相关信息,与用户输入的数据进行对比,填充空白的单元格。第二种是收集运行时信息的 程序合成 技术,比如 TVM 的自动调度方案,采用运行时的性能模型合成高效率的代码调度 [3]。
体系结构优化
编程语言与体系结构的交互伴随运行过程始终,在动态编译、并行编程和存储系统方面都有体现。动态二进制指令翻译是一种与此相关的研究,把一种形式的二进制指令翻译为另一种形式的二进制指令,比如使用动态二进制翻译的 CPU 模拟器 Qemu。还有用于并行编程的推测调度和多线程技术,比如软件流水技术、超标量技术。近来兴起的 非易失性存储器(Non-Volatile Memory) 成为数据存储领域新的研究载体,有研究在 Java 语言中加入与 NVM 相关的关键字,从编程语言的设计上方便操作新型存储器。
集成电路设计
硬件是编程语言运行时的核心部分,向上提供指令集作为接口。领域特定语言(DSL)需要领域特定硬件(DSA)来作为实际载体加速。DSL 加速软件开发,DSA 加速领域特定语言的运行速度是深度学习出现以来的新的趋势。电子设计自动化工具作为硬件设计的重要组成部分一直是重要的组成部分。无论是传统上的集成电路设计用的 Verilog、VHDL,还是后来为了方便编程演变出的 HLS 和 Pynq [4],都是为了加速芯片设计而产生的。但是近来兴起的 Circt 和 XLS 沿袭了 LLVM 的思路,采用了复杂系统模块化的思路,希望能够对传统集成电路设计工具解耦。
# Runtime 的过去 #
笔者在 Charles N. Fischer 所著的 Crafting a Compiler [5] 中了解到 Runtime 的发展历史。
编程语言设计的演变导致越来越复杂的运行时存储组织方法的产生。举例来说,数组可以被分配一个单一的固定大小的内存块,而现在有一些新的编程语言,允许数组的大小在程序执行时指定,甚至能够根据程序的需要动态扩展。
最初,所有的数据都是全局的,其生命周期跨越了整个程序。相应地,所有的存储分配也是静态的。在翻译过程中,一个数据对象或指令序列在程序的整个执行过程中被简单地放在一个固定的内存地址上。
在 1960 年代,Lisp 和 Algol 60 语言引入了局部变量,这些局部变量(local variables)仅仅能够在子程序(subprogram)的执行的时候被访问。这种特性导致了 栈式分配(stack allocation) 的产生。当过程或者方法被调用时,新的 栈帧(frame) 被压入运行时栈。栈帧由为所有特定过程中的局部变量分配的空间组成。随着过程的返回,它的栈帧被弹出,同时被局部变量占据的空间被取回。因此,仅仅是正在执行的过程被分配了空间,而不活跃的过程不需要数据空间。这使得相比早期使用静态分配翻译的空间效率更高。而且,递归的过程会由于同一个过程不相关嵌套的活动而请求多个栈帧。
Lisp 和随后的像 C、C++、C# 和 Java 一类的语言,使得动态分配数据能够在运行期间的任何时候被创建或者释放。动态的数据请求堆分配(heap allocation),这使得内存块在程序执行的任何时间以任何顺序被分配和释放。使用动态分配,数据对象的数目和大小不需要提前固定。每个程序的执行能够定制它所需要的存储分配。
所有的存储分配技术利用数据区域(data area)这个符号。一个数据区域是一块被编译器知道的存储,这个区域具有统一的存储分配的必要条件。也就是说,所有在这个数据区域上的对象共享相同的数据分配策略。一个程序的全局变量能够组成一个数据区域。当程序开始运行时,所有变量的空间被分配,并且变量仍然再分配直到执行结束。
这里给一个关于内存布局的问题,C++ 语言里给定一个 char * 的变量指针,如何判断这个变量是 new 动态分配的还是在栈中呢?如下面的代码所示,我们只需要根据栈是在程序虚拟空间的顶端自顶向下生长,而堆是在栈的下方自底向下生长这一规律就可以判断。ch 变量是局部变量,分配在栈中,故其地址一定大于堆中的变量地址。

C 语言运行时空间分配
bool if_malloc(char *p) {
char ch{};
char *ch_p{&ch};
if (ch_p> p) {
return true;
}
else {
return false;
}
}C 语言没有垃圾回收等运行时机制,而 C++ 语言有虚方法调用的运行时机制,比如下面的例子中,如果传给 fun() 的参数是 Rectangle 的指针,那么最终调用的是 Rectangle 类中的 print() 方法,而不是 Shape 类中的方法。
class Shape {
public:
virtual void print() {
...
}
}
class Rectangle:public Shape {
public:
virtual void print() override{
...
}
}
void fun(Shape* rec) {
rec->print();
}再以 Python 为例举一个和垃圾回收有关的例子。Python 采用了 引用计数 作为主要的垃圾回收算法,同时结合了 分代收集(Generational Collection)算法。这是因为引用计数在循环引用的情况下,无法分辨出是否应该销毁对象,从而导致内存泄漏。这时就需要显式地调用 GC 模块,如下所示。
import gc
class Base():
def __init__(self):
pass
c = Base()
d = Base()
# 出现循环引用
c.p = d
d.p = c
# 显式执行回收
gc.collect()# 谈谈 JIT 编译 #
John Aycock 发表过一篇 A Brief History of Just-In-Time [6] 的文章,对 JIT 的历史做了比较详尽的讲解,本文对此文进行了解读。
编译器的设计涉及到很多领域,比如正则表达式、有限自动机等。传统上,翻译一个程序大体上可以分成两种方法:编译 和 解释。编译执行指的是把一个程序翻译成汇编语言,最终翻译为更适合执行的机器代码。解释执行消除了中间的步骤,可以立即执行。对比来讲,编译执行的效率更高,而解释执行的灵活度更高。
那么 JIT 编译 指的是什么呢?JIT 编译(即 Just-In-Time Compile)是指程序开始执行后的动态编译,用以同时获得静态编译执行和动态解释执行的收益。
我们从几个方面比较 JIT、编译执行和解释执行。
执行时间上 对于直接被编译为目标机器可执行的指令流而言,编译的程序运行更快。静态编译的最大优势就是能够耗费任意时间来做程序分析与优化。而 JIT 系统不能引起程序执行的暂停,因此对于 JIT 来说,编译时间也成为了约束 JIT 最主要的因素。
程序体积上 当语言的表示离机器代码越高时,就意味着能够携带更多的语义信息解释执行平均来说更小。这也是为什么解释执行的程序平均来说更小。
可移植性上 解释执行的程序还有更便携的特性。对于像高层次的源码或者虚拟机器码这种机器独立的表示而言,只有解释器需要提供在不同机器上的实现,而被解释的程序不用考虑这些。
信息获取上 解释器能够访问输入参数,控制流和目标机器特性这一类运行时的信息。每次运行时程序的信息都会发生变化;这些信息只有在运行时才能够访问。此外,解释器也可以收集一些在静态分析时不好判定的程序的类型信息。
如果一个程序的表示能够被 JIT 系统以包括编译为机器码或者解释的任何方式执行,就可以说这个程序是可执行的。需要注意的是,JIT 系统不仅包括了翻译的功能,也包括了加载的功能,这一点和传统的编译器有很大不同。JIT 编译器运行的时刻也很重要,当基于热点计数探测时,如果设定在方法的开始点进入 JIT 后的代码,则在方法出现某段时间特别长的循环时,JIT 编译器始终无法执行,就会是一个问题。
JIT 编译是一种提高解释程序性能的方法,也被称为动态编译。相比静态编译,动态编译有很多优势 [7]。当运行 Java 或者 C# 应用程序时,运行时环境在程序运行时能够生成利于编译器优化性能的配置文件,即 PGO(Profile Guided Optimization)。这就可以产生更多的优化代码。关于 JIT 编译的一些缺点包括启动时的延迟和运行时的编译开销。因此很多编译器仅仅编译那些频繁使用的代码。
# JIT 编译的历史
我们讨论的内容不包括 自修改代码(self-modifying code)(即程序在运行期间(Runtime)会修改自身指令的代码),因为基本上没有编译或者解释的优化会把这个考虑进去。也就是说被编译的程序自己并不知道编译后自己的样子。
可能进行 JIT 编译的点 [8]
## LISP
最早的 JIT 实现可以追溯到 John McCarthy 于 1960 年编写的 LISP。他在 《符号表达式的递归函数及其机器计算》 [9] 一书中提出了 把函数编译为机器语言 的方法,从而无需将编译器的工作输出到打孔卡上。另外一个关于 JIT 早期的工作可以追溯到 1966 年,密西根大学为 IBM 7090 设计的 执行系统(Executive System)明确指出 汇编器(assembler)[10] 和 加载器(loader)[11] 能够在程序执行时被用来翻译和加载。Thompson 在 1968 年发表在 ACM 通讯的论文 [12] 开创了正则表达式,可以在 QED 文本编辑器中搜索子字符串。为了加速算法,Thompson 将正则表达式编译到 IBM 7094 机器码。

The time-space tradeoff.
在运行时间和空间的权衡总是 JIT 要考虑的最主要因素,如上图所示。此外,一项 1971 年基于经验的研究数据表明,大多数程序会花费大量的时间执行很少的一段代码。基于这两种情况,出现了两种解决方法:混合代码(Mixed Code) 和 抛弃型编译(Throw-Away Compiling)。
## APL: Drag-along and Beating
APL [13](全称是 A Programming Language 或 Array Processing Langauge),是由 Kenneth E. Iverson 在 1962 年设计的一门面向数组计算的编程语言。Kenneth 后来因对数学表达式和编程语言理论的贡献而获得了 1979 年的图灵奖。
由于 APL 语言的动态特性,大多数 APL 的实现都是解释性的。Abrams 在 1970 年提出 [14] 了 拖动(Drag-along) 和 跳动(Beating) 两种 APL 实现的优化策略,这两个策略都提高了数组作为操作数的速度,其中 拖动 是从时间上优化,跳动 是从空间上优化。
拖动 Drag-along
拖动 Drag-along 的策略是,通过收集上下文的信息,寄希望于未来会有一个更为高效的求值方法,因此 尽可能地推迟表达式求值(expression evaluation)。这种方法又被称为 惰性求值(lazy evaluation)。
为了更直观地表示惰性求值,下面给出一段伪代码。直观来讲,我们只有到 print() 语句执行时才能够看到程序的状况。如果是解释执行就需要 c d e 三个临时存储才能够计算。懒惰求值是指并不立即计算 c d e,而是直到 print() 执行时才开始进行上面的计算,这样做的好处就是既优化了信息又不影响用户的观察。当执行到 print(e) 时,惰性求值编译器会发现 e=a+b+a+b+a=3*a+2*b=3*a+(b<<1),这就极大地削弱了运算的强度和访存的数量。
let c = a + b
let d = c + a + b
let e = d + a
print(e)跳动 Beating
跳动 Beating 通过代码变换降低表达式求值时涉及到的数据操纵(data manipulation)的次数。具体来讲,即通过将标准形式的代码变换应用于数组的存储访问函数上,将原本直接访问的变量替换为那些可以在无需操作数组值的情况下求值的表达式。
这么说有点抽象,接下来我用更详细地例子解释 beating。假设,在 C 语言里访问数组都是用 A[i] 这种方式,并且我们已经知道了数组的数据布局。但如果想要从二维数组 A 得到它的转置数组 B,就需要做一次拷贝。Beating 的思想是,不直接使用存储(storage)来描述,而是增加一个中间层 数据描述子(data-descriptor),用来表示数据访问的顺序和范围等。在加入数据描述子后,对数组的转置等操作就不需要数据移动(Data movement)了。如果需要新的变换,只需要在数据描述子上变换,而不需要在存储上变换,从而新的描述子和原来的描述子共享原始的数据 owner。
为了更清楚地说明中间层数据描述子,给出下面针对整数数组描述子的伪代码描述。假设我们需要反转线性表,我们无需逐个读取线性表中的数据,这会耗费 O(N) 的时间复杂度,而只需要在数据描述子上重新赋值 begin 和 end,这样时间复杂度仅需 O(1)。
/* 转置数据描述 */
struct reverse_manipulator {
int* data_array;
int length;
iterator begin; // 初始化为 data_array + length - 1
iterator end; // 初始化为 data_array
}
/* 正向数据描述 */
struct data_manipulator {
int* data_array;
int length;
iterator begin; // 初始化为 data_array
iterator end; // 初始化为 data_array + length - 1
}APL 实现
Abrams 设计的 APL Machine 由两个共享相同内存和寄存器的独立 JIT 编译器组成。D-machine 应用跳动和拖动来推迟程序的求值,然后由 E-machine 进行求值。主要的机器寄存器是栈区(stacks),程序会被组织为逻辑段。Abrams 的工作使得为高级语言提供硬件支持变得流行。对 APL 语言有兴趣的可以访问 TryAPL:https://tryapl.org/
由于 Abrams 设计的 APL Machine 动态性很强,其类型和数据对象的属性直到运行时才能得知,因此这两种方法与 JIT 编译相关。懒惰求值技术在一些编译器里得到了应用,比如清华的即时编译深度学习框架 Jittor、函数式语言 Haskell 等。然而跳动(beating)技术现在还没有得到大规模的应用,当前业界与这种思想比较相似的就是为了降低显存而设计的 重计算方法。
后来,Ronald L. Johnston 基于 Abrams 的 Drag-along 和 Beating 为 APL 实现了一个动态增量编译器 APL\3000 [15],是 JIT 编译的一个早期例子。APL 实现的设计思想对今天的编译器设计,尤其是数据密集型的编译器设计仍然有很大的启发性意义。
## Mixed Code, Throw-Away Code, and BASIC
混合代码 Mixed Code 即把程序实现为 本地代码(Native code)和 解释代码(Interpreted code)的混合形式。这种方法在 1973 年被 Dakin 和 Poole [16] 以及 Dawson [17] 分别提出。程序中被频繁执行的代码会被实现为本地代码,而不频繁执行的部分会被解释执行,以此希望在产生很少内存占用的同时对速度几乎不产生影响。这种实现方式考虑的都是细粒度的混合(举个反例,程序是解释执行,而使用的库是本地代码,这种就不算 Mixed Code)。
为了更直观地表示混合代码执行,下面写一段伪代码。
if (current_method.can_jit == true) {
native_code = load_native_code(current_method);
native_code(param);
}
else {
virtual_pc = current_method.getEntry();
run(virtual_pc);
}伪代码的第一段 if 语句表明如果虚拟机判断这个方法可以 JIT 执行,它会动态加载已经编译好的代码,然后执行这一段本地代码。否则就进行解释执行,获得要执行方法的首指令位置,然后解释执行。
混合代码方法自 Pittman 1987 年提出了 自定义解释器(Customizing the interpreter) [18] 后迎来了重要转折。与原本在程序中混合本地代码不同的是,自定义解释器将本地代码表示为一种特殊的虚拟机器指令,然后程序整体被编译成这种虚拟机器指令。
混合代码的基本思想(即在不同类型的可执行代码间切换)仍然在后来的 JIT 系统中被广泛使用。但在当时的年代,同时将编译器和解释器保留在内存中成本太高。除此之外,即使假设大多数代码会在解释器和编译器之间共享,仍然会需要维护两部分行为上等价但完全不相关的代码(即解释器与编译器的代码生成器)。
一部分人认为 部分求值(Partial Evaluation) 或 程序特化(Program Specialization) 从某种程度上讲是似是而非的,因为一个编译器可以被看作是一个特殊的解释器 [19]。然而部分求值技术现在没有广泛传播。部分求值 / 程序特化 [20],即在编译时预先对一部分代码进行计算,在运行时对代码做特化(specialize),从而生成运行速度比原始程序更快的新程序。
下面以一段伪代码为例解释(运行时)程序特化。原始代码在运行时会发现 d 是不变量,因此会被特化为下面的代码。鉴于在运行时我们可以获得更多的信息,因此可以对程序进行更多的优化。运行时的特化与模板中编译时特化在形式上相似,针对的阶段不同。
/* 原始的函数 */
void func(int a, int b, int c, int d) {
...
}
/* 运行时,如果发现不变量,经过特化的函数 */
void func(int a, int b, int c, 5) {
...
}因此,抛弃型编译 [21] 作为一个纯粹的空间优化技术被提出。与静态编译不同,抛弃型编译只在有需要的时候对部分程序动态编译。当内存耗尽时,一些或者所有已被编译好的代码可能被扔掉,如果有必要,这些代码将在之后重新生成。
下面使用伪代码解释抛弃型编译的异步过程。当方法被调用时,检查是否已经 JIT 编译好了,如果没有编译好,就先进行 JIT 编译,然后执行本地代码。如果内存用尽,就先删除本地代码。
method.on_call((param)=>{
if(method.has_jit == false) {
method.native_code = jit_compile(method);
}
method.native_code(param);
})
method.on_memory_runout(()=>{
method.native_code.delete();
method.has_jit = false;
}))BASIC 语言可以说是抛弃型编译的试验场。Brown [21] 将抛弃型编译看作是解决时间和空间权衡的好方法。Hammond [22] 更为坚定,他认为除非内存紧张,使用抛弃型编译会更有收益。
## HotSpot and FORTRAN
有关程序在运行时自动优化 热点(hot spots) 的动态编译最早是由 Gilbert Joseph Hansen 于 1974 年提出 [23],他解决了三个重要的问题:
哪些代码应该被优化?
Hansen 选择了一个简单并且低开销的模型,为每个(通用意义上的)代码块维护一个执行频率计数器(frequency-of-execution counter)。
这些代码在什么时候优化?
Hansen 设定了一个执行次数的阈值。当计数器达到阈值后,就会把关联的代码块作为下一层优化的候选队列中。Supervisor 代码会在两个代码块间被调用,评估计数器是否达到阈值,如果达到了就做优化,然后将控制权转移到下一个代码块中。
代码应该被怎样优化?
Hansen 采用了分次优化的方法,即将一系列机器相关和机器无关的优化分到不同的集合中,比如,一个代码块可能会先进行常量折叠(constant folding)的优化,在第二次优化时执行公共子表达式消除(common subexpression elimination)优化,第三次优化再执行代码移动(code motion)优化。
Apply in Fortran
Hansen 将这种编译优化方式应用在 Fortran 的编译器中,优化器会对执行频次不同的程序进行迭代式的优化,若一段代码执行的足够频繁,最终会被编译为机器码。Hansen 的研究结果表明,针对 “hot spots” 做解释和迭代优化,其执行成本往往远低于传统的编译器优化(即对整个程序做优化)。这种优化方式较好地限制 JIT 系统在任何给定优化点的时间开销,同时允许我们在 JIT 编译器中做增量优化。
## Smalltalk
Smalltalk 是一种动态类型、反射式、面向对象编程语言 [24]。当新的方法被动态地添加到一个类时,Smalltalk 源代码会被编译为虚拟机代码 [25]。Smalltalk 的动态更新和反射功能在四十年前都已远远领先与如今的许多主流语言。然而,Smalltalk 语言的运行十分慢,而且运行开销极大,这是影响 Smalltalk 发展的主要原因之一。
为了提高 Smalltalk 的运行性能,Deutsch 和 Schiffman 从软件层面做出了关键的优化。他们发现,只要表示之间的转换对于用户是自动的且透明的,那么就可以为信息选择最有效的表示。这个思想放到现代编译器中,可以引申为 IR 的转换在不影响用户行为的情况下可以选择更高效的实现。
他们的系统使用了 虚拟机代码到本地代码的 JIT 编译,并将该优化技术比作 宏扩展(macro-expansion)。有特色的地方在于,当开始执行时,程序会被 lazily compile 为本地代码,并由系统缓存起来以供之后使用。该编译系统与操作系统中的内存管理相关联,编译出的本地代码永远不会被操作系统的页面兑换机制换到外存中(paged out),只会被丢弃然后在必要时重新生成。
## Self
Self 是一种基于原型的面向对象的程序设计语言 [26][27],在一段时间内 Self 是 Smalltalk 最快的实现,并且仅比 C 慢两倍,完全面向对象。
与本文中提到的许多其他语言相比,Self 更像是一种研究工具。Self 在很多方面受到 Smalltalk 的影响,两者都是纯粹的面向对象的语言。不同的是,Self 摒弃了类而采用了对象的概念,并试图以其他方式统一一些概念,比如每一个动作都是动态的和可改变的,即使是基本的操作(如局部变量访问)也需要调用一个方法。
Self 语言的复杂设计,激发了大家对 JIT 编译和优化的开创和改进。Self 的大部分开发工作是在 Sun Microsystem 上进行的,因此后来很多技术被直接用在了 Java 的 HotSpot VM 上。在设计 JIT 的过程中,有研究者发现触发机制比选择机制重要得多。这也和不同的编码风格有关,比如面向对象编程风格倾向于短的方法。
在 Self 编程语言中,可以在方法正在执行的时候修改,这个修改依赖于修改方法的运行堆栈。Self 编译器的 JIT 优化还引入了 类型反馈(type feedback) [28][29],即程序执行时的类型信息由运行时系统收集,当下一次运行时可以根据这个类型信息进行更为激进的优化。下面分别是已知类型信息和未知类型信息时解释器的动作,已知类型信息时判断的条件更少,运行得更快。
def func(A, B):
return A + B
func(0, 1)
# 未知类型信息的目标伪代码
if A.typeid == int:
if B.typeid == int:
return A.getintdata() + B.getintdata()
# 已知类型信息的目标伪代码
return A + BSelf 后来被 Sun 抛弃了,但对 Java 语言的研究仍在继续。
## Slim Binaries and Oberon
在上个世纪,将软件部署到不同的机器上是个大问题,因为不同的机器具有不同的体系结构。Franz 使用 瘦二进制文件(slim binaries) [30][31] 来解决这个问题。
瘦二进制文件 包含一个高级的、独立于机器表示的程序模块。当模块被加载时,会迅速生成会根据运行时的环境动态调整的可执行的代码。至于为什么叫 “瘦”,可以考虑一个高层次的 IR 通常会比低层次的 IR 在单位空间上蕴含的信息更多,因此占用空间更小。
Franz 认为,就目标代码的性能而言,一次生成整个模块的代码通常会优于 Smalltalk 和 Self 用的一次生成整个方法代码的策略。因此对于瘦二进制文件方法而言,快速的代码生成很关键。如果之后需要,生成的代码可以被记录下来而不是重新生成。
Franz 为 Oberon(一种通用编程语言,由 Niklaus Emil Wirth 在 1987 年推出)[32] 实现了一个动态代码生成系统 Juice(https://github.com/berkus/Juice)。Juice 系统实现了瘦二进制文件,允许动态模块(Module)的加载。加载和产生瘦二进制的代码要比加载传统二进制文件慢一些。从瘦二进制文件发明开始,Kistler 开始研究如何连续地进行运行时优化,也就是不断地优化正在执行中程序的某一部分。
## Templates, ML, and C
这一部分介绍模板的相关内容,ML(Meta Language)语言相对较早,如今大家也不是很熟悉,但是 C 系的语言大家都很熟悉。ML 和 C 都采用了分阶段编译的方法。单个程序的编译分为两个阶段:静态编译阶段和动态编译阶段。在运行时之前,静态编译器编译 “模板(templates)”,这些模板的本质是运行时由动态编译器拼接在一起的构建块(building blocks),里面会有一些值在运行时填充。模板在执行之前需要运行时翻译,也就是特化,动态编译器在连接模板之后会做运行时优化。需要注意的是,这里的模板不是现在 C++ 里的模板。这一个部分现在用的少,只看上面的概念也有点难懂,所以下面举个例子,源自文献 [33], 这个例子里 x 是静态的,而 y 是动态的,是只有运行时才知道的。
// 源程序
int f(int x,int y) {
int l;
l = 2 * x;
if(l==2)
l=l+y;
else
l=y*x;
return l;
}上面是 C 语言的源程序,因为提取模板的方法有很多,下面选择一种方案提取模板。
/*--t1-begin---*/
int f_t(int y) {
int l;
/*--t1-end-----*/
/*--t2-begin-----*/
l=[h1]+y;
/*--t2-end-----*/
/*--t3-begin-----*/
l=y*[h2];
/*--t3-end-----*/
/*--t4-begin-----*/
return l;
}
/*--t4-end-----*/上面的代码总共被划分成了 4 个模板。因为参数 x 是原始过程声明为静态的,所以他们可以确定,但是我们不知道程序的调用者现在给它什么值。因此它作为运行时特化器的一个参数出现,运行时的值被转换成了洞,使用 [h1] 和 [h2] 来表示。
下面是动态编译器如何特化函数 f 的过程,此时模板使用运行时的值实例化。
void rt_spec_f(int x) {
int l;
dump_template(t1);
l=2*x;
if(l==2) {
dump_template(t2);
instantiate_hole(t2,l);
}
else {
dump_template(t3);
instantiate_hole(t3,x);
}
dump_template(t4);
}局部变量 l 既在静态运算中,也在动态运算中。运行时特化器的第一个运算是 dump 模板 t1。原始过程的第一个指令能够被执行是因为它是纯静态的。然后条件语句被执行。条件测试结果决定 dump 模板 t2 还是 dump 模板 t3。dump 后的模板使用运行时的值实例化。最后模板 t4 被实例化。
## Erlang
Erlang 是一种通用的并发的、函数式、分布式的编程语言,用于设计大型软实时(soft real-time)系统。Erlang 官方实现的虚拟机 BEAM,可以解释执行;还有编译为二进制的高性能编译器 HiPE(High Performance Erlang,由 Uppsala University 开发 [34]);也支持脚本的方式来执行。
Erlang 的 HiPE 实现旨在解决性能问题。通常情况下,HiPE 编译器会比 BEAM 编译器生成更快的代码。作为一个没有设计历史包袱的系统,HiPE 的突出之处在于用户必须显式调用 JIT 编译器,这样做可以在混合代码执行上提供的性能与代码空间权衡之上提供给用户更好的控制度。HiPE 在本地代码和解释代码之间来回执行 “模式切换” 时非常小心,在明显的调用和返回位置、以及抛出异常时可能需要模式切换。它们的调用使用调用者的模式。
## Specialization and O’Caml
O'Caml 是另外一种函数式编程语言,可以看做是 ML 的一种方言 [35]。O'Caml 的解释器一直致力于 运行时特化(run-time specilization)的工作。
Piumarta 和 Riccardi 把解释器的指令特化为正在运行的程序 [36]。他们首先把解释的字节码动态翻译到直接线程代码,然后把指令块动态组合成为新的 “宏操作码”,修改代码以使用新指令。这减少了指令分派的开销,并为宏操作码中的优化提供了机会。如果指令是分开的,那么这种优化是不可能的。他们的技术没有考虑动态执行路径,但是指出了它最适合分派时间是影响性能相对较大因素的低级指令集。
## Prolog
Prolog [37] 是一个面向逻辑、动态编译的编程语言。Prolog 基于谓词逻辑,具有很强的声明性特征。最初被运用于自然语言等研究领域,现在被广泛应用在人工智能的研究中,比如建造专家系统、自然语言理解等。
为了让 Prolog 程序的解释执行更加高效,Prolog 代码会被编译为 WAM(Warren Abstract Machine,沃伦抽象机)指令。SICStus 作为 Prolog 编译器的最大供应商,提供了一系列基于 WAM 的 Prolog 实现。Haygood 与 SICStus 团队一起,开发了一种新的 Prolog 实现,能够被调用并且动态加载输出 [38],既具备一定的可移植性,又一定程度上提高了性能。(SICStus Prolog 官网:https://sicstus.sics.se,更多介绍可以阅读:SICStus Prolog -- the first 25 years.[39])
## Java and JIT
Java 是一门通用的面向对象的编程语言,于 1995 年由 Sun 正式发布后,伴随着互联网的迅猛发展而发展,逐渐成为重要的网络编程语言。
不同于当时的其他编译型语言或解释型语言,Java 先将源码静态编译为虚拟机字节码指令,然后再依赖不同平台的 Java 虚拟机(JVM)来解释执行字节码,从而具备跨平台的特性。早期的 JVM 只是解释器,解释字节码很慢,这一定程度上影响了 Java 的运行效率。因此,提高 Java 的运行效率又重新激发了研究者们对 JIT 的兴趣。而加快 Java 程序运行速度的核心方法就是对 Java 字节码的 Just in Time Compile(即 JIT 编译)。
Cramer 等 Sun 研发人员观察到 [40],JIT 编译带来的速度提升是有上限的,在他们运行的一个配置文件中,适当的解释仅占执行时间的 68%。他们主张直接使用 JVM 字节码(堆栈机指令集,stack-based)作为 JIT 编译和优化的中间表示。但是只有从字节码到本地代码的翻译是不够的,还需要代码优化,而传统的优化技术是昂贵的。因此,大家寻找对优化算法的改进,尽可能在算法的执行速度和编译速度之间取得平衡。
Burke 等人提出了只编译的策略 [41],没有任何解释器。他们的系统也是用 Java 实现的,对 JIT 的改进直接使他们的系统受益。
Agesen [42] 将 JVM 字节码翻译成 Self 代码,以利用 Self 编译器的优化。
Azevedo 等人 [43] 尝试用注释将代码优化的工作转移到运行时间之前,高效的 JIT 优化所需的信息被预先计算并作为注释标记到字节码上,然后由 JIT 系统使用以协助其工作。
Plezbert 和 Cytron [44] 提出并评估了 Java 的 “连续编译” (continuous compilation)的想法,其中解释器和编译器将同时执行,最好是在不同的处理器上执行。
# JIT 系统的分类
Aycock 将 JIT 分为四类:
触发方式 Invocation
如果用户必须明确地采取一些行为来调用运行时的编译,那么 JIT 编译器就是显式调用的(explicitly invoked)。一个隐式调用的 JIT 编译器对用户来说是透明的。
执行方式 Executability
若 JIT 的源语言和目标语言是相同的,则 JIT 是单一执行(monoexecutable)的。否则,该系统就是多执行的(polyexecutable)。
即使 JIT 是单一执行的,JIT 系统仍然会做 on-the-fly 的优化。(on-the-fly 是指执行过程中伴随的过程,并不打断执行,或者说 on-the-fly 是一种无缝的切换。) 这种优化是单一执行的优势,它并不翻译代码到新的语言,只是做运行时的 JIT 优化。
还有一种 JIT 系统是多执行(polyexecutable)的,这样的 JIT 系统(注意不是编译器)能够执行多于一种的语言。多执行的 JIT 系统可以决定何时需要调用编译器。例如,JVM 是一个典型的多执行的 JIT 系统,其中的 Java 字节码在 JIT 执行时会被编译为机器代码,JVM 能够执行 Java 字节码(解释执行)和机器代码(JIT 后执行)这两种语言。
并发方式 Concurrency
如果程序需要暂停从而运行 JIT 编译器,这个 JIT 系统就不是并发的。如果 JIT 编译器能够在单独的线程或者进程甚至处理器上,与程序并发地执行,则该 JIT 系统是个并发的 JIT 系统。
实时性 Real-time
即,如果 JIT 系统能够提供实时的保证,也就是说 JIT 编译器能够保证在多长时间内完成任务,就说这个 JIT 系统是实时保证的。
# JIT 编译的挑战
随着 JIT 编译的发展,一些问题和挑战也随之出现:
二进制代码生成
事实上,二进制代码的动态生成充满了挑战。比如,有些程序中会包含一些在最开始代码生成阶段无法获取的信息,比如前向分支的目标(可以参考《编译原理》紫龙书对于 if 语句翻译为 goto 回填的问题),我们需要知道后面的代码块后才能回填(Backpatch)到合适的位置上。
缓存
在缓存问题上,缓存一致性问题已经有协议来保证,那么最重要的是提高 JIT 代码加载的速度。能够在执行之前把 JIT 代码从内存载入 Cache 加快执行速度,并且能够合理划分需要 JIT 部分的大小,不要使得 JIT 生成后的二进制代码被频繁地换入换出 Cache。
除此之外,JVM 等现代 JIT 系统在内存中开辟了代码缓存,这个区域负责存储编译为本机代码的字节码,代码缓存具有固定的大小。如果这个区域满,JVM 会停止编译。而对于每个编译的方法,JVM 提供一个热度计数器,如果计数器的值小于阈值,JVM 就释放这段预编译代码 [45]。
执行
可执行的代码存放的位置可能会被操作系统所限制。比如,生成的 JIT 代码如果存放在数据区还要显式地声明数据区的可执行属性,这时的代码区和数据区的界限就变得不明晰。举例来说,在安全领域经常使用的 shellcode 就是放在数据区的一段可执行代码,用来发送到服务器利用特定漏洞的代码,一般可以获取权限。
# Runtime 的未来 #
由于程序静态分析和优化的局限性,JIT 编译兼具静态编译和动态优化的优势就更加明显。在深度学习等技术催生的各种领域特定语言涌现的当下,如果拓宽传统 JIT 编译的应用范围,适配更多不同的语言也是一个重要的问题。GraalVM [46] 是一个把传统的编译技术与云环境结合起来的项目,给云原生编译器也开了一扇新的天窗。
参 考
[1] The magic mix: interpreter, compiler, specializer. https://www.cs.dartmouth.edu/~doug/cs118/mix.html
[2] Jiaqi Gao, Ennan Zhai, Hongqiang Harry Liu, Rui Miao, Yu Zhou, Bingchuan Tian, Chen Sun, Dennis Cai, Ming Zhang, and Minlan Yu. 2020. Lyra: A Cross-Platform Language and Compiler for Data Plane Programming on Heterogeneous ASICs. In Proceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications, technologies, architectures, and protocols for computer communication (SIGCOMM '20). Association for Computing Machinery, New York, NY, USA, 435–450. DOI: https://doi.org/10.1145/3387514.3405879
[3] Interactive Program Synthesis by Augmented Examples https://tianyi-zhang.github.io/files/uist2020-interactive-program-synthesis.pdf
[4] PYNQ - Python productivity for Zynq - Home http://www.pynq.io/
[5] Charles N. Fischer, Ronald K. Cytron, and Richard J. LeBlanc. 2009. Crafting A Compiler (1st. ed.). Addison-Wesley Publishing Company, USA.
[6] John Aycock. 2003. A brief history of just-in-time. ACM Comput. Surv. 35, 2 (June 2003), 97–113. DOI: https://doi.org/10.1145/857076.857077
[7] Just in Time Compilation Explained https://www.freecodecamp.org/news/just-in-time-compilation-explained/
[8] Hiroshi Inoue etc. Adaptive Multi-Level Compilation in a Trace-based Java JIT Compiler.
[9] MCCARTHY, J. 1960. Recursive functions of symbolic expressions and their computation by machine, part I. Commun. ACM 3, 4, 184–195. http://www-formal.stanford.edu/jmc/recursive.pdf
[10] UNIVERSITY OF MICHIGAN. 1966b. The “University of Michigan Assembly Program” (“UMAP”). In University of Michigan Executive System for the IBM 7090 Computer, Vol. 2. University of Michigan, Ann Arbor, MI.
[11] UNIVERSITY OF MICHIGAN. 1966a. The System Loader. In University of Michigan Executive System for the IBM 7090 Computer, Vol. 1. University of Michigan, Ann Arbor, MI.
[12] THOMPSON, K. 1968. Regular expression search algorithm. Commun. ACM 11, 6 (June), 419–422.
[13] APL - Wikipedia https://en.wikipedia.org/wiki/APL_(programming_language)
[14] ABRAMS, P. S. 1970. An APL machine. Ph.D. dissertation. Stanford University, Stanford, CA. Also, Stanford Linear Accelerator Center (SLAC) Rep. 114.
[15] THE DYNAMIC INCREMENTAL COMPILER OF APL\3000. http://www.softwarepreservation.org/projects/apl/Papers/DYNAMICINCREMENTAL
[16] DAKIN, R. J. AND POOLE, P. C. 1973. A mixed code approach. The Comput. J. 16, 3, 219–222.
[17] DAWSON, J. L. 1973. Combining interpretive code with machine code. The Comput. J. 16, 3, 216–219.
[18] PITTMAN, T. 1987. Two-level hybrid interpreter/native code execution for combined space-time program efficiency. In Proceedings of the SIGPLAN Symposium on Interpreters and Interpretive Techniques. ACM Press, New York, NY, 150–152.
[19] JONES, N. D., GOMARD, C. K., AND SESTOFT, P. 1993. Partial Evaluation and Automatic Program Generation. Prentice Hall, Englewood Cliffs, NJ.
[20] Partial Evaluation - Wikipedia https://en.wikipedia.org/wiki/Partial_evaluation
[21] BROWN, P. J. 1976. Throw-away compiling. Softw.—Pract. Exp. 6, 423–434. https://doi.org/10.1002/spe.4380060316
[22] HAMMOND, J. 1977. BASIC—an evaluation of processing methods and a study of some programs. Softw.—Pract. Exp. 7, 697–711.
[23] HANSEN, G. J. 1974. Adaptive systems for the dynamic run-time optimization of programs. Ph.D. dissertation. Carnegie-Mellon University, Pittsburgh, PA. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.376.3638&rep=rep1&type=pdf
[24] SmallTalk - Wikipedia https://en.wikipedia.org/wiki/Smalltalk
[25] GOLDBERG, A. AND ROBSON, D. 1985. Smalltalk-80:The Language and its Implementation. AddisonWesley, Reading, MA.
[26] UNGAR, D. AND SMITH, R. B. 1987. Self: The power of simplicity. In Proceedings of OOPSLA ’87. 227–242.
[27] SMITH, R. B. AND UNGAR, D. 1995. Programming as an experience: The inspiration for Self. In Proceedings of ECOOP ’95.
[28] HOLZLE, U. 1994. Adaptive optimization for Self: Reconciling high performance with exploratory programming. Ph.D. dissertation. CarnegieMellon University, Pittsburgh, PA.
[29] HOLZLE, U. AND UNGAR, D. 1994a. Optimizing dynamically-dispatched calls with run-time type feedback. In Proceedings of PLDI ’94. 326–336.
[30] FRANZ, M. 1994. Code-generation on-the-fly: A key to portable software. Ph.D. dissertation. ETH Zurich, Zurich, Switzerland.
[31] FRANZ, M. AND KISTLER, T. 1997. Slim binaries. Commun. ACM 40, 12 (Dec.), 87–94. https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.108.1711&rep=rep1&type=pdf
[32] Oberon - Wikipedia https://en.wikipedia.org/wiki/Oberon_(programming_language)
[33] Carles Consel. A General Approach for Run-Time Specialization and its Application to C.
[34] Erlang - HiPE http://erlang.org/documentation/doc-10.3/lib/hipe-3.18.3/doc/html/HiPE_app.html
[35] REMY, D., LEROY, X., AND WEIS, P. 1999. Objective Caml—a general purpose high-level programming language. ERCIM News 36, 29–30.
[36] PIUMARTA, I. AND RICCARDI, F. 1998. Optimizing direct threaded code by selective inlining. In Proceedings of PLDI ’98. 291–300.
[37] Prolog - Wikipedia https://en.wikipedia.org/wiki/Prolog
[38] HAYGOOD, R. C. 1994. Native code compilation in SICStus Prolog. In Proceedings of the Eleventh International Conference on Logic Programming. 190–204. https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.106.6147&rep=rep1&type=pdf
[39] Mats Carlsson, Per Mildner: SICStus Prolog -- the first 25 years. CoRR abs/1011.5640 (2010) https://arxiv.org/abs/1011.5640
[40] CRAMER, T., FRIEDMAN, R., MILLER, T., SEBERGER, D., WILSON, R., AND WOLCZKO, M. 1997. Compiling Java just in time. IEEE Micro 17, 3 (May/June), 36–43.
[41] BURKE, M. G., CHOI, J.-D., FINK, S., GROVE, D., HIND, M., SARKAR, V., SERRANO, M. J., SREEDHAR, V. C., AND SRINIVASAN, H. 1999. The Jalapeno dynamic optimizing compiler for Java. In Proceedings of JAVA ’99. 129–141.
[42] AGESEN, O. 1997. Design and implementation of Pep, a Java just-in-time translator. Theor. Prac. Obj. Syst. 3, 2, 127–155.
[43] AZEVEDO, A., NICOLAU, A., AND HUMMEL, J. 1999. Java annotation-aware just-in-time (AJIT) compilation system. In Proceedings of JAVA ’99. 142–151.
[44] PLEZBERT, M. P. AND CYTRON, R. K. 1997. Does “just in time” = “better late then never”? In Proceedings of POPL ’97. 120–131.
[45] jvm-code-cache https://www.baeldung.com/jvm-code-cache
[46] GraalVM - Wikipedia https://en.wikipedia.org/wiki/GraalVM
原文转载自 编程语言Lab-从 JIT 编译看 Runtime 的过去与未来
