1. CRNN算法结构
文字识别是对序列的预测方法,所以采用了对序列预测的RNN网络。通过CNN将图片的特征提取出来后采用RNN对序列进行预测,最后通过一个CTC的翻译层得到最终结果。
所以CRNN算法主要采用的是CNN+RNN+CTC三层网络结构,从下到上,依次为:
(1)卷积层,使用CNN,从输入图像中提取特征序列;
(2)循环层,使用RNN,预测从卷积层获取的特征序列的标签(真实值)分布;
(3)转录层,使用CTC,把从循环层获取的标签分布通过去重整合等操作转换成最终的识别结果。


2. CNN(即卷积层)
卷积层共包含7层卷积神经网络,基础结构采用的是VGC的结构,其中输入是把灰度图缩放到尺寸为W*32,即固定高。在第三个和第四个池化层的时候,为了追求真实的高宽比例,采用的核尺寸为1*2(并非2*2)。为了加速收敛并引入了BN层。把CNN提取到的特征图按列切分,每一列的512维特征,输入到两层各256单元的双向LSTM进行分类。在训练过程中,通过CTC损失函数的指导,实现字符位置与类标的近似软对齐。
如图:

现在需要从CNN模型产生的特征图中提取特征向量序列,每一个特征向量(红色框)在特征图上按列从左到右生成,每一列包含512维特征,这意味着第i个特征向量是所有的特征图第i列像素的连接,这些特征向量就构成一个序列。
由于卷积层,最大池化层和激活函数在局部区域上执行,因此它们是平移不变的。因此特征图的每列(即一个特征向量)对应于原始图像的一个矩形区域(成为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。特征序列中的每个向量关联一个感受野。
提取的特征序列中的向量是从特征图上从左到右按照顺序生成的,每个特征向量表示了图像上一定宽度上的特征,论文中使用的这个宽度是1,就是单个像素。

如果一张包含10个字符的图片大小为100×32,经过上述的CNN网络得到的特征尺度为25×1(这里忽略通道数),这样得到一个序列,每一列特征对应原图的一个矩形区域(如下图所示),这样就很方便作为RNN的输入进行下一步的计算了,而且每个特征与输入有一个一对一的对应关系。

从上图可以看出,对VGG的调整如下:
1.为了能将CNN提取的特征作为输入,输入到RNN网络中,文章将第三和第四个maxpooling的核尺度从2×2改为了1×2
2.为了加速网络的训练,在第五和第六个卷积层后面加上了BN层。
为什么将第三和第四个maxpooling的核尺度从2×2改为1×2是为了方便的将CNN的提取特征作为RNN的输入.首先要注意的是这个网络的输入为W×32,也就是说该网络对输入图片的宽没有特殊的要求,但是高都必须resize到32。
假设现在输入有个图像,为了将特征输入到Recurrent Layers,做如下处理:
- 首先会将图像缩放到 32×W×1 大小
- 然后经过CNN后变为 1×(W/4)× 512。
- 接着针对LSTM,设置 T=(W/4) , D=512 ,即可将特征输入LSTM
- LSTM有256个隐藏节点,经过LSTM后变为长度为T × nclass的向量,再经过softmax处理,列向量每个元素代表对应的字符预测概率,最后再将这个T的预测结果去冗余合并成一个完整识别结果即可。
关于CNN原理详解,具体可以参考:https://www.jianshu.com/writer#/notebooks/46006121/notes/71156459
3.RNN(即循环层)
因为 RNN 有梯度消失的问题,不能获取更多上下文信息,所以 CRNN 中使用的是 LSTM,LSTM 的特殊设计允许它捕获长距离依赖。
RNN网络是对于CNN输出的特征序列x=x1,⋯⋯,xt,每一个输入xt,都有一个输出yt, 为了防止训练时梯度的消失,文章采用了LSTM神经单元作为RNN的单元。文章认为对于序列的预测,序列的前向信息和后向信息都有助于序列的预测,所以文章采用了双向RNN网络。LSTM神经元的结构和双向RNN结构如下图所示。
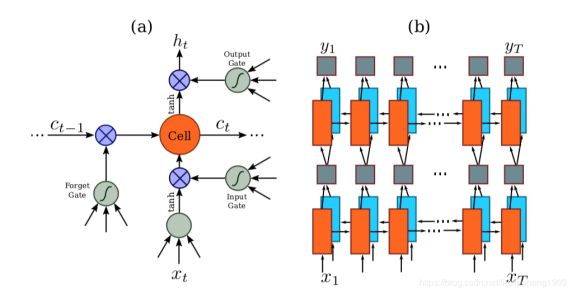
示例:
通过上面一步,我们得到了40个特征向量,每个特征向量长度为512,在 LSTM 中一个时间步就传入一个特征向量进行分类,这里一共有40个时间步。
我们知道一个特征向量就相当于原图中的一个小矩形区域,RNN 的目标就是预测这个矩形区域为哪个字符,即根据输入的特征向量,进行预测,得到所有字符的softmax概率分布,这是一个长度为字符类别数的向量,作为CTC层的输入。
因为每个时间步都会有一个输入特征向量 ,输出一个所有字符的概率分布 ,所以输出为 40 个长度为字符类别数的向量构成的后验概率矩阵,然后将这个后验概率矩阵传入转录层。
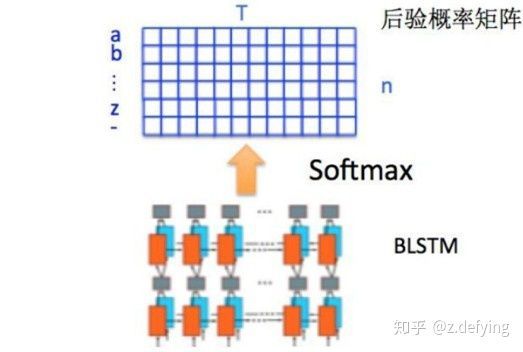
4.CTC(即转录层或翻译层)
测试时,翻译分为两种,一种是带字典的,一种是没有字典的。
带字典的就是在测试的时候,测试集是有字典的,测试的输出结果计算出所有字典的概率,取最大的即为最终的预测字符串
不带字典的,是指测试集没有给出测试集包含哪些字符串,预测时就选取输出概率最大的作为最终的预测字符串。
端到端OCR识别的难点在于怎么处理不定长序列对齐的问题!(因为是不定长序列,按照以前的方法我们很难去计算loss,如果是定长的话容易造成信息的丢失,而且局限性太大!)
转录是将 RNN 对每个特征向量所做的预测转换成标签序列的过程。数学上,转录是根据每帧预测找到具有最高概率组合的标签序列。
具体可以参考:https://www.jianshu.com/writer#/notebooks/46006121/notes/71156474
该笔记为学习时总结,参考了很多网络资料,如有侵权请及时联系告知
原文链接:https://blog.csdn.net/Jeremy_lf/article/details/104809208