1.向数据集添加交互式特征
在实际应用中,常常会遇到数据集的特征不足的情况,要解决这个问题,就需要对数据集的特征进行扩充。这里我们介绍两种在统计建模中常用的方法---交互式特征(Interaction Features)和多项式特征(Polynomial Features)。现在这两种方法在机器学习领域也非常普遍。
1.交互式特征的定义:
顾名思义,交互式特征是在原始数据特征添加交互项,使特征数量增加。
在python中,我们可以通过Numpy的hstack函数来对数据集添加交互项,下面我们先通过一段代码了解一下hstack函数的原理,输入代码如下:
array_1 = [1,2,3,4,5]
array_2 = [6,7,8,9,0]
array_3 = np.hstack((array_1, array_2))
print('将数组2添加到数据1中后得到:{}'.format(array_3))
运行代码如下:
将数组2添加到数据1中后得到:[1 2 3 4 5 6 7 8 9 0]
结果分析:从结果中看到,原来两个5维数组被堆叠到一起,形成了一个新的10维数组,也就是说我们使array_1和array_2产生了交互。假如array_1和array_2分别代表两个数据点的特征,那么我们生成的array_3就是他们的交互特征。
接下来我们继续用之前生成的数据集来进行实验,看对特征进行交互式操作会对模型产生什么样的影响,输入代码如下:
X_stack = np.hstack([X, X_in_bin])
X_stack.shape
运行代码,得到如下结果:
(50, 11)
从结果可以看到,X_stack的数量仍然是50个,而特征数量变成了11.下面我们要用新的特征X_stack来训练模型,输入代码如下:
line_stack = np.hstack([line, new_line])
mlpr_interact = MLPRegressor().fit(X_stack, y)
plt.plot(line, mlpr_interact.predict(line_stack),
label='MLP for interaction')
plt.ylim(-4,4)
for vline in bins:
plt.plot([vline,vline],[-5,5],':',c='k')
plt.legend(loc='lower right')
plt.plot(X, y,'o',c='r')
plt.show()
运行代码,如下图所示:
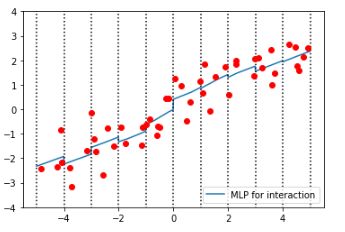
结果分析:
首先拿出上一节的经过装箱的数据拟合的模型的图形来和这一次拟合经过特征交互的数据的模型图进行比较:
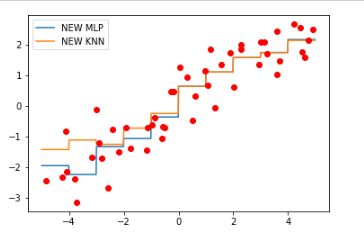
发现上个图的模型的斜率是水平的,这一次的模型斜率是倾斜的。也就是说,在添加了交互式特征之后,在每个数据所在的装箱体中,MLP模型增加了斜率,复杂度有所提高。
但是,发现每个箱体中模型的斜率都是一样的,这还不是我们想要的结果,我们希望达到的效果是,每个箱体中都有各自的截距和斜率。所以要换一种数据处理的方式,输入一下代码:
#使用心得堆叠方式处理数据
X_multi = np.hstack([X_in_bin, X*X_in_bin])
print(X_multi.shape)
print(X_multi[0])
运行代码,结果如下:

结果分析:从结果中可以看到,经过以上的处理,心得数据集特征X_mulit变成了有20个特征值的形态。试着打印出第一个样本,发现20个特征中大部分数值都是0,而在之前的X_in_bin中数值为1的特征,与原始数据中X的第一个特征值-1.522688保留了下来。
下面用处理过的数据集训练神经网络,看看模型会有什么不同,输入代码如下:
mlpr_multi = MLPRegressor().fit(X_multi, y)
line_multi = np.hstack([new_line, line * new_line])
plt.plot(line, mlpr_multi.predict(line_multi), label = 'MLP Regressor')
for vline in bins:
plt.plot([vline,vline],[-5,5],':',c='gray')
plt.plot(X, y, 'o', c='r')
plt.legend(loc='lower right')
plt.show()
运行代码,得到如下图所示的结果:
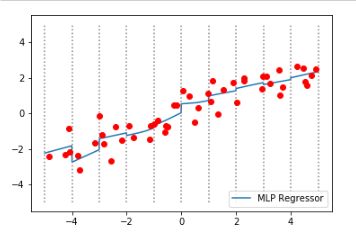
结果分析:每个箱子中模型的截距和斜率都不一样了。而这种数据处理的目的,主要是为了让比较容易出现欠拟合现象的模型能有更好的表现。
例如:线性模型在高维数据集中有良好的表现,但是在低维数据集中表现却一般,因此需要用上面的方法来进行特征扩充,以便给数据集“升维”,从而提高线性模型的准确率。
2.向数据集添加多项式特征
首先回顾一下什么是多项式,在数学中,多项式指的是多个单项式相加所组成的代数式。当然如果是减号的话,可以看作是这个单项式的相反数。下面是一个典型的多项式:
而其中的和e都是单项式。在机器学习当中,常用的扩展样本特征的方式就是将特征X进行乘方,如等。你可能觉得这有点儿麻烦,不过没有关系,scikit-learn中内置了一个功能,称为PolynomialFeatures,使用这个功能就可以轻松地将原始数据及的特征进行扩展,下面来看代码:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=20, include_bias = False)
X_poly = poly.fit_transform(X)
print (X_poly.shape)
这段代码中,首先指定了PolynomialFeatures的degree参数为20,这样可以生成20个特征,include_bias设定为False,如果为True,PolynomialFeatures只会为数据集添加数值为1的特征
运行代码,如下:
(50, 20)
结果分析:
从结果中可以看到,仍然是50个样本,但每个样本的特征数变成了20个。
那么PolynomialFeatures对数据进行了怎样的调整呢?我们用下面的代码打印一个样本的特征看一下:
print('原始数据集中的第一个样本特征:\n{}'.format(X[0]))
print('\n处理后的数据集中第一个样本特征:\n{}'.format(X_poly[0]))
运行代码,得到如下图所示结果:
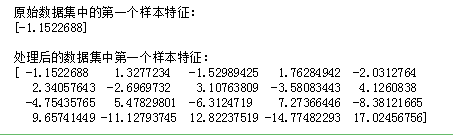
结果分析:从结果可看到,原始数据及的样本只有一个特征,而处理后的数据集有20个特征。如果你口算能力很强的话,大概可以看出样本的第一个特征是原始特征,第二个特征是原始特征的2次方,第三个特征是原始特征的3次方,以此类推。
下面我们用线性模型回归来实验一下这样处理的数据集,输入代码如下:
from sklearn.linear_model import LinearRegression
LNR_poly = LinearRegression().fit(X_poly, y)
line_poly = poly.transform(line)
plt.plot(line,LNR_poly.predict(line_poly), label='Linear Regressor')
plt.xlim(np.min(X)-0.5,np.max(X)+0.5)
plt.ylim(np.min(y)-0.5,np.max(y)+0.5)
plt.plot(X,y,'o',c='r')
plt.legend(loc='lower right')
plt.show()
运行代码,得到如下图:

结果分析:从图中可以看出,这条线变得分外妖娆,从而得出结论:对于低维数据集,线性模型常常出现欠拟合的问题,而将数据集进行多项式特征扩展后,可以在一定程度上解决线性模型欠拟合的问题。