学习!学习!!学习!!!学习之外目的到此为止!
上东东的时候,突然给我弹了一个充气娃娃的广告,于是就点进去就看了一下评论,全是神评论啊。所以我就想着把大神们的评论们扒拉下来仔细瞅瞅,于是这篇文章就诞生了 ,纯属学习啊,不要想入非非啊,还有,不喜勿喷!

首先我先找了某东最火娃娃,里面评论8w+条,这里面神评论一定不少。所以决定从这个里面扒拉我们想要获取的数据

因为一些网站不喜欢外界的爬虫消耗自己的服务器的大量资源,因此它们会有自己反爬虫程序。如果不使用代理的话,他们就能识别出你是爬虫,从而给你进行重定向无数次,导致你的爬虫报错。所以我们要对我们的爬虫进行伪装。
那就需要带上我们的防爬header三兄弟了。当然这只是最基本的防爬措施。更多的反爬措施和技巧可以参考曾经它让我恼怒抓狂,但是现在我对它是赞不绝口!
cookie - 侧重于用户的类型,这里具体指的就是登录的用户呢还是游客
refer - 指的是用户从哪个页面发出网络的访问和数据的请求
user-agent 指的是访问后台服务器的是哪一个浏览器
首先找到咱们防止反爬的必须参数。
在获取数据的时候把它们加在header里面就可以获取到非空数据了。
接下来咱们先试试。
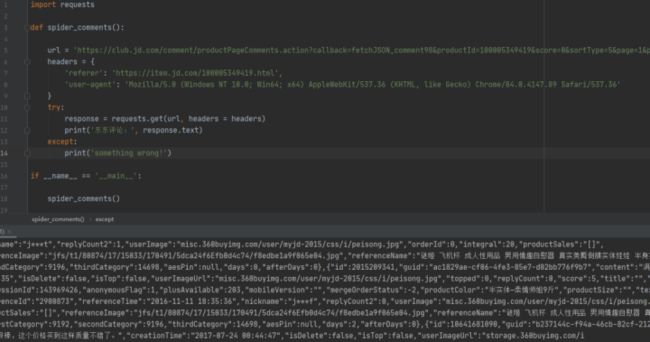
可以看到我们已经成功地获取到数据了。但是数据格式还需要进一步的处理。首先咱们来分析一下获取到的数据。
获取到的数据前面多了20位的'fetchJSON_comment98(',后面多了四位的']}'。所以我们首先要去掉这些多余的修饰符使之成为完成的json格式的数据。
json_data = response.text[20:-2]
再来看看运行结果:

好了,已经初步实现了我们的目标。因为在咱们的目标只是评论而无需其他的参数。所以现在去网页分析一下这些评论所在的位置。
可以看到我们想要的评论内容是在comments下面的content中,所以我们首先定位到comments中然后循环获取content里面的内容。
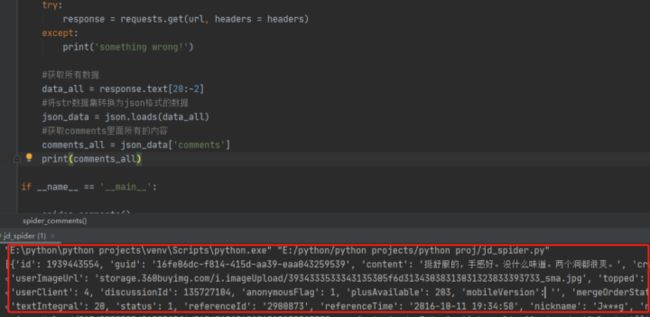
for comment in comments_all:
print(comment['content'])
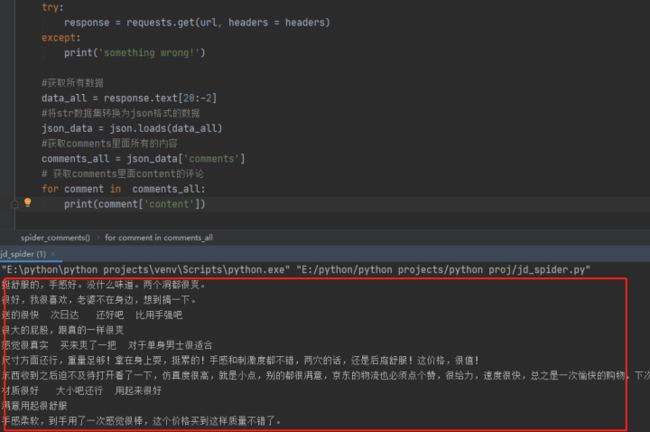
好了我们现在已经成功的获取到了第一页的内容,后面的评论需要进行翻页操作,所以我们多翻几页找规律。
pageSize=10每页固定显示10条记录。
不同之处就在于这个参数page,所以可以确定页数是由它来控制的。所谓以我们可以设置一个变量来控制它,从而获取到全部页数的评论。
对get_spider_comments方法加入变量page,当我们指定page的值时,它就可以获取固定页面的评论。
在batch_spider_comments方法中sleep方法,用来模拟用户浏览,防止因为爬取太频繁导致ip被封。
for i in range(100):
print('正在爬取' + str(i+1) + '页数据....')
get_spider_comments(i) #批量获取评论方法
print('爬虫结束!')
可以成功的获取到所要爬取的页数的全部数据!

接下来咱们爬取数据的任务已经结束了。现在呢我想通过词云可视化分析一下它火的原因。
for comment in comments_all:
with open(comments_file_path, 'a+', encoding='utf-8') as f:
f.write(comment['content'] + '\n')
接下来看一下我们写入到文件的内容
需要通过词云分析时就需要数据,所以我们需要把获取到的评论先放存入文档,这里为了方便我就直接放入txt文档了。
首先需要我们对jieba和wordcloud进行了解,使用pip install jieba对jieba库进行安装。然后用jieba对获取到的评论进行分词。
with open(comments_file_path, encoding = 'utf-8') as fin:
comment_text = fin.read()
word_list = jieba.lcut_for_search(comment_text)
new_word_list = ' '.join(word_list)
来看效果

然后使用pip install wordcloud再安装wordcloud。最后用generate方法生成词云图。
好了接下来我们就需要找一张自己心仪的图片来做分词操作了。
所以之后大家可以按照自己的意愿来设置图片的形状。
我选了一张萌萌哒的小狗的图片。我在这里引入了imageio的 imread方法 以获取原始图片dog.jpg的参数
然后使用mask=mask 传递形状参数,所以最后我们获取到的就是一张圆形的词云图
def create_word_cloud():
mask = imread('dog.jpg')
wordcloud = WordCloud(font_path='msyh.ttc', mask = mask).generate(cut_words())
wordcloud.to_file('dog.png')
来看看实现词云效果之后的小狗图


好了目标已经实现。源码尚在整理中,想要学习的可以直接找我哦!