python每周一练
每周五发布python需求,所有需求都来自实际企业。下周五发布参考答案。
2018-06-25 用递归的方式实现阶乘
Return n! = 123...n
参考答案
2018-06-22 字符串和正则表达式小练习
试题1:
下面哪个个字符串定义有错误?
A,r'C:\Program Files\foo\bar'
B,r'C:\Program Files\foo\bar'
C, r'C:\Program Files\foo\bar\'
D,r'C:\Program Files\foo\bar\\'
参考答案:B
试题2:
现有 类似'python3快速入门教程2数值与序列3列表'的字符串,字符规则如下:
1,行首有英文或数字组合,中间有中文,后面又有英文或数字组合
2, 要求用正则表达式提取第一个中文字段,比如上面的“快速入门教程”
参考答案
#!python
In [1]: import re
In [2]: t = 'python3快速入门教程2数值与序列3列表'
In [3]: re.findall('^\w+(..*?)\w+',t, re.ASCII)
Out[3]: ['快速入门教程']
2018-06-15 睁闭眼数据分析
现有如下睁闭眼数据
#!python
$ head data.csv
# 左眼睁闭眼分数 左眼有效分数 右眼睁闭眼分数 右眼有效分数 图片名称
0.123603 9.835913 9.470212 9.889045,/home/andrew/code/data/common/Eyestate/ocular_base/close/1.jpg
0.179463 9.816979 2.074970 9.901421,/home/andrew/code/data/common/Eyestate/ocular_base/close/10.jpg
0.673736 9.925372 0.001438 9.968187,/home/andrew/code/data/common/Eyestate/ocular_base/close/11.jpg
0.593570 9.905622 0.001385 9.986063,/home/andrew/code/data/common/Eyestate/ocular_base/close/12.jpg
0.222101 9.974337 0.005272 9.985535,/home/andrew/code/data/common/Eyestate/ocular_base/close/13.jpg
1.105360 9.978926 0.007232 9.986403,/home/andrew/code/data/common/Eyestate/ocular_base/close/14.jpg
5.622934 9.955227 5.909572 9.969641,/home/andrew/code/data/common/Eyestate/ocular_base/close/15.jpg
0.010507 9.965939 0.005150 9.990325,/home/andrew/code/data/common/Eyestate/ocular_base/close/16.jpg
0.043546 9.986520 0.014031 9.982257,/home/andrew/code/data/common/Eyestate/ocular_base/close/17.jpg
6.176013 9.848222 4.293341 9.929223,/home/andrew/code/data/common/Eyestate/ocular_base/close/18.jpg
要求:
- 筛选出未识别到人脸的数据(左眼睁闭眼分数值为-1)
- 筛选出图片格式错误的数据(左眼睁闭眼分数值为-2)
- 筛选出闭眼识别为睁眼的数据(图片名包含close,但是睁闭眼有一个大于9.5)
- 筛选出睁眼识别为闭眼的数据(图片名包含open,但是睁闭眼都小于9.5)
- 筛选出无效识别为有效的数据(图片名包含invalid,但是有效分有一个大于9.5)
- 筛选出有效识别为无效的数据(图片名包含valid,但是有效分都小于9.5)
代码和参考代码地址
2018-06-14 创建三色图片
创建如下的三色图片,像素600*400

python图像处理参考库
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# Author: xurongzhong#126.com wechat:pythontesting qq:37391319
# 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入)
# qq群:144081101 591302926 567351477
# CreateDate: 2018-6-12
# dutchflag.py
from PIL import Image
def dutchflag(width, height):
"""Return new image of Dutch flag."""
img = Image.new("RGB", (width, height))
for j in range(height):
for i in range(width):
if j < height/3:
img.putpixel((i, j), (255, 0, 0))
elif j < 2*height/3:
img.putpixel((i, j), (0, 255, 0))
else:
img.putpixel((i, j), (0, 0, 255))
return img
def main():
img = dutchflag(600, 400)
img.save("dutchflag.jpg")
main()
2018-06-12 数据分析:筛选列B包含列A内容的列
来自群python数据分析人工智能 521070358的提问
有类似如下结构的大量数据
#!python
{'A':['Ford', 'Toyota', 'Ford','Audi'],
'B':['Ford F-Series pickup', 'Camry', 'Ford Taurus/Taurus X', 'Audi test']}
现在想:
1,输出列B包含列A内容的记录
2,输出列A为Ford或Toyota的记录
参考代码:
#!python
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Author: xurongzhong#126.com wechat:pythontesting qq:37391319
# 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入)
# qq群:144081101 591302926 567351477
# CreateDate: 2018-6-012
import pandas as pd
def test(x):
if x['A'] in x['B']:
return True
else:
return False
df = pd.DataFrame( {'A':['Ford', 'Toyota', 'Ford','Audi'],
'B':['Ford F-Series pickup', 'Camry', 'Ford Taurus/Taurus X', 'Audi test']} )
print(df)
# 输出列B包含列A内容的记录
print(df[df.apply(test, axis=1)])
# lambda 方式
print(df[df.apply(lambda x: x['A'] in x['B'], axis=1)])
# 输出列A为Ford或Toyota的记录
print(df[df['A'].str.match('Ford|Toyota')])
执行结果:
#!python
A B
0 Ford Ford F-Series pickup
1 Toyota Camry
2 Ford Ford Taurus/Taurus X
3 Audi Audi test
A B
0 Ford Ford F-Series pickup
2 Ford Ford Taurus/Taurus X
3 Audi Audi test
A B
0 Ford Ford F-Series pickup
2 Ford Ford Taurus/Taurus X
3 Audi Audi test
A B
0 Ford Ford F-Series pickup
1 Toyota Camry
2 Ford Ford Taurus/Taurus X
本节代码地址
2018-06-11 python数据机构基础面试题
生成
#!python
[-0.1, 0. , 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9,
1. , 1.1]
参考:
#!python
import numpy as np
[x / 10.0 for x in range(-1, 11)]
np.arange(-0.1, 1.1, 0.1)
2018-06-08 用turtle绘制长度为10像素的正方形(初级)
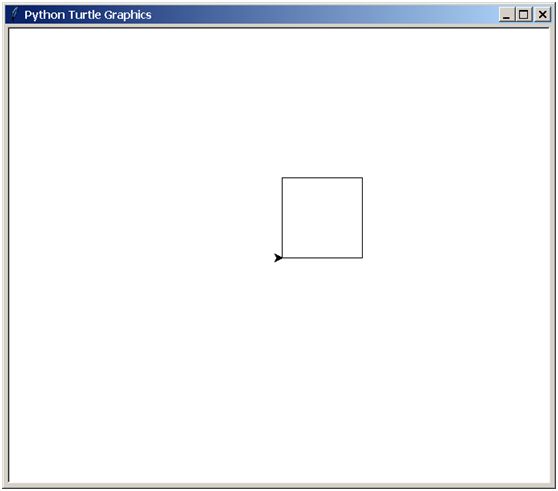
参考代码:
#!python
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Author: xurongzhong#126.com wechat:pythontesting qq:37391319
# 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入)
# qq群:144081101 591302926 567351477
# CreateDate: 2018-6-07
from turtle import *
forward(100)
left(90)
forward(100)
left(90)
forward(100)
left(90)
forward(100)
left(90)
exitonclick()
注意用使用python3.6.0或更高版本, 命令行执行比较好。
延伸学习

参考代码:
#!python
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Author: xurongzhong#126.com wechat:pythontesting qq:37391319
# 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入)
# qq群:144081101 591302926 567351477
# CreateDate: 2018-6-07
from turtle import *
pensize(7)
penup()
goto(-200, -100)
pendown()
fillcolor("red")
begin_fill()
goto(-200, 100)
goto(200, -100)
goto(200, 100)
goto(-200, -100)
end_fill()
exitonclick()
2018-06-07 计算不同版本人脸识别框的重合面积
现有某图片,版本1识别的坐标为:(60, 188, 260, 387),版本2识别的坐标为(106, 291, 340, 530)))。格式为left, top, right, buttom。
请计算:公共的像素总数,版本1的像素总数,版本2的像素总数,版本1的重合面积比例,版本2的重合面积比例.
参考代码:
#!python
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Author: xurongzhong#126.com wechat:pythontesting qq:37391319
# 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入)
# qq群:144081101 591302926 567351477
# CreateDate: 2018-6-07
def get_area(pos):
left, top, right, buttom = pos
left = max(0, left)
top = max(0, top)
width = right - left
height = buttom - top
return (width*height, left, top, right, buttom)
def overlap(pos1, pos2):
area1, left1, top1, right1, buttom1 = get_area(pos1)
area2, left2, top2, right2, buttom2 = get_area(pos2)
left = max(left1, left2)
top = max(top1, top2)
left = max(0, left)
top = max(0, top)
right = min(right1, right2)
buttom = min(buttom1, buttom2)
if right <= left or buttom <= top:
area = 0
else:
area = (right - left)*(buttom - top)
return (area, area1, area2, float(area)/area1, float(area)/area2)
print(overlap((60, 188, 260, 387), (106, 291, 340, 530)))
详细代码地址
执行
#!python
$ python3 overlap.py
(14784, 39800, 55926, 0.3714572864321608, 0.2643493187426242)
2018-06-06 json格式转换
现有 人脸标注的海量数据,部分参见:data
要求输出:
1,files.txt
#!python
image_1515229323784.ir
image_1515235832391.ir
image_1515208991161.ir
image_1515207265358.ir
image_1521802748625.ir
image_1515387191011.ir
...
2, 坐标信息 poses.txt
文件名、left, top, right, buttom,width,height
#!python
image_1515229323784.ir,4,227,234,497,230,270
image_1515235832391.ir,154,89,302,240,148,151
image_1515208991161.ir,76,369,309,576,233,207
image_1515207265358.ir,44,261,340,546,296,285
...
3,比对文件:
首先:# 后面的为序列号,从1开始递增
3 640 480 1及后面3行暂时视为固定。后面一行1 后面为4个坐标left, top, right, buttom。
#!python
# 1
image_1515229323784.ir
3 640 480 1
0
1
1 4 227 234 497
# 2
image_1515235832391.ir
3 640 480 1
0
1
1 154 89 302 240
# 3
...
参考代码:
#!python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import shutil
import os
import glob
import json
import pprint
import json
import data_common
directory = 'data'
files = data_common.find_files_by_type(directory,'json')
i = 1
file_list = []
results = []
poses = []
for filename in files:
d = json.load(open(filename))
name = d['image']['rawFilename'].strip('.jpg')
pos = d['objects']['face'][0]['position']
num = len(d['objects']['face'])
if num > 1:
print(filename)
print(name)
pprint.pprint(d['objects']['face'])
out = "# {}\n{}\n3 640 480 1\n0\n{}\n".format(i, name, num)
for face in d['objects']['face']:
pos = face['position']
top = round(pos['top'])
bottom = round(pos['bottom'])
left = round(pos['left'])
right = round(pos['right'])
out = out + "1 {} {} {} {}\n".format(left, top, right, bottom)
poses.append("{},{},{},{},{},{},{}".format(name,
left, top, right, bottom, right - left, bottom -top))
i = i + 1
#print(out)
file_list.append(name)
results.append(out.rstrip('\n'))
data_common.output_file("files.txt",file_list)
data_common.output_file("results.txt",results)
data_common.output_file("poses.txt",poses)
详细代码地址
2018-06-01 正则表达式及拼音排序
有某群的某段聊天记录
现在要求输出排序的qq名,结果类似如下:
#!python
[..., '本草隐士', 'jerryyu', '可怜的樱桃树', '叻风云', '欧阳-深圳白芒', ...]
需求来源:有个想批量邀请某些qq群的活跃用户到自己的群。又不想铺天盖地去看聊天记录。
参考资料:python文本处理库
参考代码:
#!python
#!/usr/bin/python3
# -*- coding: utf-8 -*-
# Author: [email protected] wechat:pythontesting qq:37391319
# 技术支持 钉钉群:21745728(可以加钉钉pythontesting邀请加入)
# qq群:144081101 591302926 567351477
# CreateDate: 2018-6-1
import re
from pypinyin import lazy_pinyin
name = r'test.txt'
text = open(name,encoding='utf-8').read()
#print(text)
results = re.findall(r'(:\d+)\s(.*?)\(\d+', text)
names = set()
for item in results:
names.add(item[1])
keys = list(names)
keys = sorted(keys)
def compare(char):
try:
result = lazy_pinyin(char)[0][0]
except Exception as e:
result = char
return result
keys.sort(key=compare)
print(keys)
执行示例:
1,把qq群的聊天记录导出为txt格式,重命名为test.txt
2, 执行:
#!python
$ python3 qq.py
['Sally', '^^O^^', 'aa催乳师', 'bling', '本草隐士', '纯中药治疗阳痿早泄', '长夜无荒', '东方~慈航', '干金草', '广东-曾超庆', '红梅* 渝', 'jerryyu', '可怜的樱桃树', '叻风云', '欧阳-深圳白芒', '勝昔堂~元亨', '蜀中~眉豆。', '陕西渭南逸清阁*无为', '吴宁……任', '系统消息', '于立伟', '倚窗望岳', '烟霞霭霭', '燕子', '张强', '滋味', '✾买个罐头 吃西餐', '【大侠】好好', '【大侠】面向大海~纯中药治烫伤', '【宗师】吴宁……任', '【宗师】红梅* 渝', '【少侠】焚琴煮鹤', '【少侠】笨笨', '【掌门】溆浦☞山野人家']
上述代码地址
2018-05-25 旋转图片
把/home/andrew/code/tmp_photos2的jpg图片旋转270度,放在/home/andrew/code/tmp_photos3
参考资料:python图像处理库
要求实现的命令行界面如下:
#!sh
$ python3 rotate.py -h
usage: rotate.py [-h] [-t TYPE] [-a ANGLE] [--version] src dst
功能:旋转图片
示例: $ python3 rotate.py /home/andrew/code/tmp_photos2 /home/andrew/code/tmp_photos3 -a 270
把/home/andrew/code/tmp_photos2的jpg图片旋转270度,放在/home/andrew/code/tmp_photos3
positional arguments:
src 源目录
dst 目的目录
optional arguments:
-h, --help show this help message and exit
-t TYPE 文件扩展名, 默认为jpg
-a ANGLE 旋转角度,默认为90度,方向都为逆时针。
--version show program's version number and exit
旋转前:

旋转后

需求来源: 用户拍的图片人脸未必是头在上,下巴在下面,但是人脸识别的时扶正的识别效果比较好,为此...
参考代码:
#!python
import glob
import os
import argparse
from PIL import Image
import photos
import data_common
description = '''
功能:旋转图片
示例: $ python3 rotate.py /home/andrew/code/tmp_photos2 /home/andrew/code/tmp_photos3 -a 270
'''
parser = argparse.ArgumentParser(description=description,
formatter_class=argparse.RawTextHelpFormatter)
parser.add_argument('src', action="store", help=u'源目录')
parser.add_argument('dst', action="store", help=u'目的目录')
parser.add_argument('-t', action="store", dest="type", default="jpg",
help=u'文件扩展名, 默认为jpg')
parser.add_argument('-a', action="store", dest="angle", default=90, type=int,
help=u'旋转角度,默认为90度,方向都为逆时针。')
parser.add_argument('--version', action='version',
version='%(prog)s 1.0 Rongzhong xu 2018 04 26')
options = parser.parse_args()
data_common.check_directory(options.dst)
files = data_common.find_files_by_type(options.src, filetype=options.type)
photos.rotate(files, options.dst, options.angle)
参考资料
- 讨论qq群144081101 591302926 567351477 钉钉免费群21745728
- 本文最新版本地址
- 本文涉及的python测试开发库 谢谢点赞!
- 本文相关海量书籍下载