本文主要总结了《Java8实战》,适用于学习 Java8 的同学,也可以作为一个 API 手册文档适用,平时使用时可能由于不熟练,忘记 API 或者语法。
Java8 新特性:
- Lambda 表达式 − Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
- 方法引用 − 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 默认方法 − 默认方法就是一个在接口里面有了一个实现的方法。
新工具 − 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。 - Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
- Date Time API − 加强对日期与时间的处理。
- Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
- Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
Lambda 表达式
Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。
以下是lambda表达式的重要特征:
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
方法引用
- 方法引用通过方法的名字来指向一个方法。
- 方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
- 方法引用使用一对冒号 :: 。
// jdk1.8接口
@FunctionalInterface
public interface Supplier {
T get();
}
public class Car {
//Supplier是jdk1.8的接口,这里和lamda一起使用了
public static Car create(final Supplier supplier) {
return supplier.get();
}
}
构造器引用
它的语法是Class::new,或者更一般的Class< T >::new实例如下:
final Car car = Car.create(Car::new);
final List cars = Arrays.asList(car);
无参构造
Supplier c1 = Apple::new;
Apple a1 = c1.get();
一个参数构造
Function c2 = Apple::new;
Apple a2 = c2.apply(110);
两个参数构造
BiFunction c3 = Apple::new;
Apple c3 = c3.apply("green", 110);
多个参数构造
可自定义Function实现,如
public interface TriFunction {
R apply(T t, U u, V v);
}
静态方法引用
它的语法是Class::static_method,实例如下:
cars.forEach(Car::collide);
特定类的任意对象的方法引用
它的语法是Class::method实例如下:
cars.forEach(Car::repair);
特定对象的方法引用
它的语法是instance::method实例如下:
final Car police = Car.create(Car::new);
cars.forEach(police::follow);
函数式接口
函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
函数式接口可以被隐式转换为lambda表达式。
函数式接口可以现有的函数友好地支持 lambda。
JDK 1.8之前已有的函数式接口:
- java.lang.Runnable
- java.util.concurrent.Callable
- java.security.PrivilegedAction
- java.util.Comparator
- java.io.FileFilter
- java.nio.file.PathMatcher
- java.lang.reflect.InvocationHandler
- java.beans.PropertyChangeListener
- java.awt.event.ActionListener
- javax.swing.event.ChangeListener
JDK 1.8 新增加的函数接口: - java.util.function
java.util.function 它包含了很多类,用来支持 Java的 函数式编程,该包中的函数式接口有:
| 接口名 | 参数 | 返回值 | 用途 |
|---|---|---|---|
| Predicate | T | boolean | 断言 |
| Consumer | T | void | 消费 |
| Function |
T | R | 函数 |
| Supplier | None | T | 工厂方法 |
| UnaryOperator | T | T | 逻辑非 |
| BinaryOperator | (T,T) | T | 二元操作 |
函数式接口各类介绍:
| 接口 | 描述 |
|---|---|
| BiConsumer |
代表了一个接受两个输入参数的操作,并且不返回任何结果 |
| BiFunction |
代表了一个接受两个输入参数的方法,并且返回一个结果 |
| BinaryOperator |
代表了一个作用于于两个同类型操作符的操作,并且返回了操作符同类型的结果 |
| BiPredicate |
代表了一个两个参数的boolean值方法 |
| BooleanSupplier | 代表了boolean值结果的提供方 |
| Consumer |
代表了接受一个输入参数并且无返回的操作 |
| DoubleBinaryOperator | 代表了作用于两个double值操作符的操作,并且返回了一个double值的结果 |
| DoubleConsumer | 代表一个接受double值参数的操作,并且不返回结果 |
| DoubleFunction |
代表接受一个double值参数的方法,并且返回结果 |
| DoublePredicate | 代表一个拥有double值参数的boolean值方法 |
| DoubleSupplier | 代表一个double值结构的提供方 |
| DoubleToIntFunction | 接受一个double类型输入,返回一个int类型结果 |
| DoubleToLongFunction | 接受一个double类型输入,返回一个long类型结果 |
| DoubleUnaryOperator | 接受一个参数同为类型double,返回值类型也为double |
| Function |
接受一个输入参数,返回一个结果 |
| IntBinaryOperator | 接受两个参数同为类型int,返回值类型也为int |
| IntConsumer | 接受一个int类型的输入参数,无返回值 |
| IntFunction |
接受一个int类型输入参数,返回一个结果 |
| IntPredicate | 接受一个int输入参数,返回一个布尔值的结果 |
| IntSupplier | 无参数,返回一个int类型结果 |
| IntToDoubleFunction | 接受一个int类型输入,返回一个double类型结果 |
| IntToLongFunction | 接受一个int类型输入,返回一个long类型结果 |
| IntUnaryOperator | 接受一个参数同为类型int,返回值类型也为int |
| LongBinaryOperator | 接受两个参数同为类型long,返回值类型也为long |
| LongConsumer | 接受一个long类型的输入参数,无返回值 |
| LongFunction |
接受一个long类型输入参数,返回一个结果 |
| LongPredicate | R接受一个long输入参数,返回一个布尔值类型结果 |
| LongSupplier | 无参数,返回一个结果long类型的值 |
| LongToDoubleFunction | 接受一个long类型输入,返回一个double类型结果 |
| LongToIntFunction | 接受一个long类型输入,返回一个int类型结果 |
| LongUnaryOperator | 接受一个参数同为类型long,返回值类型也为long |
| ObjDoubleConsumer |
接受一个object类型和一个double类型的输入参数,无返回值 |
| ObjIntConsumer |
接受一个object类型和一个int类型的输入参数,无返回值 |
| ObjLongConsumer |
接受一个object类型和一个long类型的输入参数,无返回值。 |
| Predicate |
接受一个输入参数,返回一个布尔值结果 |
| Supplier |
无参数,返回一个结果 |
| ToDoubleBiFunction |
接受两个输入参数,返回一个double类型结果 |
| ToDoubleFunction |
接受一个输入参数,返回一个double类型结果 |
| ToIntBiFunction |
接受两个输入参数,返回一个int类型结果 |
| ToIntFunction |
接受一个输入参数,返回一个int类型结果 |
| ToLongBiFunction |
接受两个输入参数,返回一个long类型结果 |
| ToLongFunction |
接受一个输入参数,返回一个long类型结果 |
| UnaryOperator |
接受一个参数为类型T,返回值类型也为T |
函数式接口实例
@FunctionalInterface
这个标注用于表示该接口会设计成一个函数式接口。如果你用 @FunctionalInterface 定义了一个接口,而它却不是函数式接口的话,编译器将返回一个提示原因的错误。例如,错误消息可能是“Multiple non-overriding abstract methods found in interface Foo” , 表明存在多个抽象方法。 请注意, @FunctionalInterface 不是必需的, 但对于为此设计的接口而言, 使用它是比较好的做法。 它就像是 @Override标注表示方法被重写了。
// 定义函数式接口
@FunctionalInterface
public interface BufferedReaderProcessor {
String process(BufferedReader b) throws IOException;
}
// 定义方法
public static String processFile(BufferedReaderProcessor p) throws
IOException {
try (BufferedReader br =
new BufferedReader(new FileReader("data.txt"))) {
return p.process(br);
}
}
// 调用
String result = processFile(br -> br.readLine() + br.readLine());
Predicate
Predicate
该接口包含多种默认方法来将Predicate组合成其他复杂的逻辑(比如:与,或,非)。
该接口用于测试对象是 true 或 false。
与:predicate.and()
或:predicate.or()
非:predicate.negate()
a.or(b).and(c) 可以看作 (a || b) && c
我们可以通过以下实例(Java8Tester.java)来了解函数式接口 Predicate
public class Java8Tester {
public static void main(String args[]) {
List < Integer > list = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
// Predicate predicate = n -> true
// n 是一个参数传递到 Predicate 接口的 test 方法
// n 如果存在则 test 方法返回 true
System.out.println("输出所有数据:");
// 传递参数 n
eval(list, n -> true);
// Predicate predicate1 = n -> n%2 == 0
// n 是一个参数传递到 Predicate 接口的 test 方法
// 如果 n%2 为 0 test 方法返回 true
System.out.println("输出所有偶数:");
eval(list, n -> n % 2 == 0);
// Predicate predicate2 = n -> n > 3
// n 是一个参数传递到 Predicate 接口的 test 方法
// 如果 n 大于 3 test 方法返回 true
System.out.println("输出大于 3 的所有数字:");
eval(list, n -> n > 3);
}
public static void eval(List < Integer > list, Predicate < Integer > predicate) {
for (Integer n: list) {
if (predicate.test(n)) {
System.out.println(n + " ");
}
}
}
}
Consumer
java.util.function.Consumer
public static void forEach(List list, Consumer c) {
for (T i: list) {
c.accept(i);
}
}
forEach(Arrays.asList(1, 2, 3, 4, 5), System.out::println);
Function
java.util.function.Function
public static List map(List list,
Function f) {
List result = new ArrayList < > ();
for (T s: list) {
result.add(f.apply(s));
}
return result;
}
// [7, 2, 6]
List l = map(Arrays.asList("lambdas", "in", "action"), String::length);
Function 接口所代表的Lambda表达式复合起来。 Function 接口为此配了 andThen 和 compose 两个默认方法,它们都会返回 Function 的一个实例。
andThen 方法会返回一个函数,它先对输入应用一个给定函数,再对输出应用另一个函数。
比如,假设有一个函数 f 给数字加1 (x -> x + 1) ,另一个函数 g 给数字乘2,你可以将它们组合成一个函数 h ,先给数字加1,再给结果乘2:
Function f = x -> x + 1;
Function g = x -> x * 2;
Function h = f.andThen(g);
int result = h.apply(1); // 4
数学上会写作 g(f(x)) 或(g o f)(x)
compose 方法
Function < Integer, Integer > f = x -> x + 1;
Function < Integer, Integer > g = x -> x * 2;
Function < Integer, Integer > h = f.compose(g);
int result = h.apply(1); // 3
数学上会写作 f(g(x)) 或 (f o g)(x)
Stream
Stream主要用于操作集合,更方便的去处理数据。
java.util.stream.Stream 中的 Stream 接口定义了许多操作。它们可以分为两大类:可以连接起来的流操作称为中间操作,关闭流的操作称为终端操作。可以理解为有返回值是Stream的方法是中间操作,返回值非Stream的方法是终端操作。
中间操作会返回另一个流,但是如果没有终端操作,中间操作不会执行任何处理。
Stream调用了终端操作之后,如果再调用,抛出以下异常:
java.lang.IllegalStateException: stream has already been operated upon or closed
Stream只能被消费一次!!!
外部迭代与内部迭代
使用 Collection 接口需要用户去做迭代(比如用 for-each ) ,这称为外部迭代。 相反,Streams库使用内部迭代。
外部迭代:外部迭代实际是使用Iterator对象。
开发中如何选择两种迭代方式:
- 如果循环体需要引用外部变量,或者需要抛Checked Exception,并不可try catch的情况下,推荐使用外部迭代,否则,随意。
- 如果对循环结果无顺序要求,循环之间没有使用操作共同数据,并对执行效率有要求,可以使用
内部迭代-parallelStream。 - 如果需要对集合数据进行处理、分组、过滤等操作,可以使用内部迭代-stream。
流的使用一般包括三件事
- 一个数据源(如集合)来执行一个查询;
- 一个中间操作链,形成一条流的流水线;
- 一个终端操作,执行流水线,并能生成结果。
筛选(filter)
该方法会接受一个谓词(Predicate)(一个返回boolean 的函数)作为参数,并返回一个包括所有符合谓词(Predicate)的元素的流。
List vegetarianMenu = menu.stream().filter(Dish::isVegetarian).collect(toList());
切片(limit)
该方法会返回一个不超过给定长度的流。所需的长度作为参数传递给 limit 。如果流是有序的,则最多会返回前 n 个元素。如果流是无序的,limit的结果不会以任务顺序排列。
List dishes = menu.stream().filter(d -> d.getCalories() > 300).limit(3).collect(toList());
去重(distinct )
该方法会返回一个元素各异(根据流所生成元素的hashCode 和equals 方法实现)的流。
List numbers = Arrays.asList(1, 2, 1, 3, 3, 2, 4);
numbers.stream().filter(i -> i % 2 == 0).distinct() .forEach(System.out::println);
跳过元素(skip)
返回一个扔掉了前 n 个元素的流。如果流中元素不足 n 个,则返回一个空流。请注意, limit(n) 和 skip(n) 是互补的!
List dishes = menu.stream().filter(d -> d.getCalories() > 300).skip(2).collect(toList());
映射(map和flatMap)
map:
一个非常常见的数据处理套路就是从某些对象中选择信息。比如在SQL里,你可以从表中选择一列。
可以改变原有流的类型,重新返回一个新的类型集合。
List dishNames = menu.stream().map(Dish::getName).collect(toList());
flatMap:
一个用于把 Stream
Arrays.stream() 的方法可以接受一个数组并产生一个流。
如果需要把一个String[] arrayOfWords = {"Hello", "World"};转换成[G, o, o, d, b, y, e, W, o, r, l, d]
String[] arrayOfWords = {"Hello", "World"};
Stream streamOfwords = Arrays.stream(arrayOfWords);
streamOfwords.map(word -> word.split("")).flatMap(Arrays::stream).collect(Collectors.toList());
匹配( allMatch和anyMatch和noneMatch )
检查是否至少匹配一个元素(anyMatch ):
boolean isVegetarian = menu.stream().anyMatch(Dish::isVegetarian);
检查是否匹配所有元素(allMatch):
boolean isHealthy = menu.stream().allMatch(d -> d.getCalories() < 1000);
检查是否所有元素不匹配(noneMatch ):
boolean isHealthy = menu.stream().noneMatch(d -> d.getCalories() >= 1000);
查找(findFirst和findAny)
返回当前流中的任意元素(findAny):
Optional dish = menu.stream().filter(Dish::isVegetarian).findAny();
获取集合中第一个元素(findFirst):
Optional dish = menu.stream().filter(Dish::isVegetarian).findFirst();
何时使用 findFirst 和 findAny
你可能会想,为什么会同时有 findFirst 和 findAny 呢?答案是并行。找到第一个元素在并行上限制更多。如果你不关心返回的元素是哪个,请使用 findAny ,因为它在使用并行流时限制较少。
归约(reduce)
reduce 接受两个参数:
- 一个初始值,这里是0;
- 一个 BinaryOperator
来将两个元素结合起来产生一个新值,这里我们用的是lambda (a, b) -> a + b 。
求和
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
等同于
int sum = numbers.stream().mapToInt(n -> n).sum();
最大值
Optional max = numbers.stream().reduce(Integer::max);
等同于
int max = numbers.stream().mapToInt(n -> n).max();
最小值
Optional min = numbers.stream().reduce(Integer::min);
等同于
int min = numbers.stream().mapToInt(n -> n).min();
执行原理:
0 作为Lambda( a )的第一个参数,从流中获得 4 作为第二个参数( b ) 。 0 + 4 得到 4 ,它成了新的累积值。然后再用累积值和流中下一个元素 5 调用Lambda,产生新的累积值 9 。接下来,再用累积值和下一个元素 3调用Lambda,得到 12 。最后,用 12 和流中最后一个元素 9 调Lambda,得到最终结果 21 。
ps:reduce如果不设置初始值,会返回一个 Optional 对象。
流操作:无状态和有状态
无状态:操作集合数据时,每一个元素之间数据不相互影响,如map或者filter等操作。
有状态:操作集合数据时,元素之间数据有影响,如sort或者distinct等操作,需要知道每个元素值才能执行处理。
| 操 作 | 类 型 | 返回类型 | 使用的类型/函数式接口 | 函数描述符 |
|---|---|---|---|---|
| filter | 中间 | Stream |
Predicate |
T -> boolean |
| distinct | 中间 (有状态-无界) | Stream |
||
| skip | 中间 (有状态-有界) | Stream |
long | |
| limit | 中间 (有状态-有界) | Stream |
long | |
| map | 中间 | Stream |
Function |
T -> R |
| flatMap | 中间 | Stream |
Function |
T -> Stream |
| sorted | 中间 (有状态-无界) | Stream |
Comparator |
(T, T) -> int |
| anyMatch | 终端 | boolean | Predicate |
T -> boolean |
| noneMatch | 终端 | boolean | Predicate |
T -> boolean |
| allMatch | 终端 | boolean | Predicate |
T -> boolean |
| findAny | 终端 | Optional |
||
| findFirst | 终端 | Optional |
||
| forEach | 终端 | void | Consumer |
T -> void |
| collect | 终端 | R | Collector |
|
| reduce | 终端 (有状态-有界) | Optional |
BinaryOperator |
(T, T) -> T |
| count | 终端 | long |
原始类型流转换
IntStream 、 DoubleStream 和 LongStream ,分别将流中的元素特化为 int 、 long 和 double,从而避免了暗含的装箱成本。转换的原因并不在于流的复杂性,而是装箱造成的复杂性——即类似 int 和 Integer 之间的效率差异。将流转换为转换的常用方法是 mapToInt 、 mapToDouble 和 mapToLong 。
转换回对象流:
要把原始流转换成一般流(每个 int 都会装箱成一个Integer ) ,可以使用 boxed 方法。
IntStream intStream = menu.stream().mapToInt(Dish::getCalories);
Stream stream = intStream.boxed();
默认值 OptionalInt:
Optional 可以用Integer 、 String 等参考类型来参数化。对于三种原始流特化,也分别有一个 Optional 原始类型特化版本: OptionalInt 、 OptionalDouble 和 OptionalLong 。
OptionalInt maxCalories = menu.stream().mapToInt(Dish::getCalories).max();
int max = maxCalories.orElse(1);
数值范围(range 和 rangeClosed):
range 和 rangeClosed这两个方法都是第一个参数接受起始值,第二个参数接受结束值。但
range 是不包含结束值的,而 rangeClosed 则包含结束值。
由值创建流(Stream.of):
Stream.of 通过显式值创建一个流,它可以接受任意数量的参数。
Stream stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action");
也可以创建一个空流:
Stream emptyStream = Stream.empty();
由数组创建流(Arrays.stream):
Arrays.stream 从数组创建一个流,它接受一个数组作为参数。
int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();
由文件生成流:
Java中用于处理文件等I/O操作的NIO API(非阻塞 I/O)已更新,以便利用Stream API。
java.nio.file.Files 中的很多静态方法都会返回一个流。例如,一个很有用的方法是Files.lines ,它会返回一个由指定文件中的各行构成的字符串流。
long uniqueWords = 0;
try (Stream lines =Files.lines(Paths.get("data.txt"), Charset.defaultCharset())) {
uniqueWords = lines.flatMap(line - > Arrays.stream(line.split(" "))) .distinct().count();
} catch (IOException e) {}
由函数生成流:创建无限流:
Stream API提供了两个静态方法来从函数生成流: Stream.iterate 和 Stream.generate 。这两个操作可以创建所谓的无限流:不像从固定集合创建的流那样有固定大小的流。由 iterate和 generate 产生的流会用给定的函数按需创建值,因此可以无穷无尽地计算下去!一般来说,应该使用 limit(n) 来对这种流加以限制,以避免打印无穷多个值。
Stream.iterate:
Stream.iterate(0, n -> n + 2).limit(10).forEach(System.out::println);
Stream.generate:
Stream.generate(Math::random).limit(5).forEach(System.out::println);
收集器
汇总(Collectors.counting 、 Collectors.summingInt、 Collectors.summingLong 、Collectors.summingDouble、 Collectors.averagingInt、 Collectors.averagingLong 、Collectors.averagingDouble、Collectors.summarizingInt、Collectors.summarizingLong、Collectors.summarizingDouble):
总数:
Collectors.counting:
long howManyDishes = menu.stream().collect(Collectors.counting());
等同于
long howManyDishes = menu.stream().count();
求和:
Collectors.summingInt:
int totalCalories = menu.stream().collect(Collectors.summingInt(Dish::getCalories));
等同于
int sum = menu.stream().mapToInt(Dish::getCalories).sum();
Collectors.summingLong:
long totalCalories = menu.stream().collect(Collectors.summingLong(Dish::getCalories));
等同于
long sum = menu.stream().mapToLong(Dish::getCalories).sum();
Collectors.summingDouble:
double totalCalories = menu.stream().collect(Collectors.summingDouble(Dish::getCalories));
等同于
double sum = menu.stream().mapToDouble(Dish::getCalories).sum();
平均数:
Collectors.averagingInt:
int avgCalories = menu.stream().collect(Collectors.averagingInt(Dish::getCalories));
Collectors.averagingLong:
long avgCalories = menu.stream().collect(Collectors.averagingLong(Dish::getCalories));
Collectors.averagingDouble:
double avgCalories = menu.stream().collect(Collectors.averagingDouble(Dish::getCalories));
汇总(总和、平均值、最大值和最小值):
Collectors.summarizingInt:
IntSummaryStatistics menuStatistics = menu.stream().collect(Collectors.summarizingInt(Dish::getCalories));
Collectors.summarizingLong:
LongSummaryStatistics menuStatistics = menu.stream().collect(Collectors.summarizingLong(Dish::getCalories));
Collectors.summarizingDouble:
DoubleSummaryStatistics menuStatistics = menu.stream().collect(Collectors.summarizingDouble(Dish::getCalories));
查找流中的最大值和最小值(Collectors.maxBy 和 Collectors.minBy):
Collectors.maxBy :
Comparator dishCaloriesComparator = Comparator.comparingInt(Dish::getCalories);
Optional mostCalorieDish = menu.stream().collect(Collectors.maxBy(dishCaloriesComparator));
连接字符串(Collectors.joining):
joining 工厂方法返回的收集器会把对流中每一个对象应用 toString 方法得到的所有字符串连接成一个字符串。 joining 在内部使用了 StringBuilder 来把生成的字符串逐个追加起来。 joining 工厂方法有一个重载版本可以接受元素之间的分界符。
String shortMenu = menu.stream().map(Dish::getName).collect(Collectors.joining());
分隔符:
String shortMenu = menu.stream().map(Dish::getName).collect(Collectors.joining(","));
分组(Collectors.groupingBy):
普通的单参数 groupingBy(f) (其中 f 是分类函数)实际上是 groupingBy(f, toList()) 的简便写法。
第一个参数是指定以什么分组
第二个参数是指定使用的Map
第三个参数是指定Collector
Map > dishesByType = menu.stream().collect(Collectors.groupingBy(Dish::getType));
多级分组:
Map>> dishesByTypeCaloricLevel = menu.stream().collect(Collectors.groupingBy(Dish::getType, Collectors.groupingBy(Dish::getCalories)));
分组汇总:
Map typesCount = menu.stream().collect(Collectors.groupingBy(Dish::getType, counting()));
分组汇总最大值:
Map Dish.Type, Optional > mostCaloricByType = menu.stream().collect(Collectors.groupingBy(Dish::getType, Collectors.maxBy(Comparator.comparingInt(Dish::getCalories))));
分组结果包装Optional转换具体值(Collectors.collectingAndThen)
Map mostCaloricByType = menu.stream().collect(Collectors.groupingBy(Dish::getType,Collectors.collectingAndThen(Collectors.maxBy(Comparator.comparingInt(Dish::getCalories)), Optional::get)));
分组类型转换(Collectors.mapping):
这个方法接受两个参数:一个函数对流中的元素做变换,另一个则将变换的结果对象收集起来。
Map > caloricLevelsByType = menu.stream().collect(Collectors.groupingBy(Dish::getType, Collectors.mapping(
dish - > {
if (dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}, Collectors.toSet())));
分区(Collectors.partitioningBy)
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函数。分区函数返回一个布尔值,这意味着得到的分组 Map 的键类型是 Boolean ,于是它最多可以分为两组—— true 是一组, false 是一组。
Map > partitionedMenu = menu.stream().collect(Collectors.partitioningBy(Dish::isVegetarian));
排序(Comparator )
Comparator 接口现在同时包含了默认方法和静态方法。可以使用静态方法 Comparator.comparing 返回一个 Comparator 对象,该对象提供了一个函数可以提取排序关键字。
- reversed —— 对当前的 Comparator 对象进行逆序排序,并返回排序之后新的Comparator 对象。
- thenComparing —— 当两个对象相同时,返回使用另一个 Comparator 进行比较的Comparator 对象。
- thenComparingInt 、 thenComparingDouble 、 thenComparingLong —— 这些方法的工作方式和 thenComparing 方法类似,不过它们的处理函数是特别针对某些基本数据类型(分别对应于 ToIntFunction 、 ToDoubleFunction 和 ToLongFunction )的。
- comparingInt 、 comparingDouble 、 comparingLong —— 它们的工作方式和 comparing 类似,但接受的函数特别针对某些基本数据类型(分别对应于 ToIntFunction 、ToDoubleFunction 和 ToLongFunction ) 。
- naturalOrder —— 对 Comparable 对象进行自然排序,返回一个 Comparator 对象。
- nullsFirst 、 nullsLast —— 对空对象和非空对象进行比较,你可以指定空对象(null)比非空对象(non-null)小或者比非空对象大,返回值是一个 Comparator 对象。
- reverseOrder —— 倒序,和 naturalOrder().reversed() 方法类似。
并行流
使用并行流可以通过parallelStream或者parallel方法。对顺序流调用 parallel 方法并不意味着流本身有任何实际的变化。它在内部实际上就是设了一个 boolean 标志,表示你想让调用 parallel 之后进行的所有操作都并行执行。并行流转换成顺序流使用sequential方法。
并行化并不是没有代价的。并行化过程本身需要对流做递归划分,把每个子流的归纳操作分配到不同的线程,然后把这些操作的结果合并成一个值。但在多个内核之间移动数据的代价也可能比你想的要大, 所以很重要的一点是要保证在内核中并行执行工作的时间比在内核之间传输数据的时间长。总而言之,很多情况下不可能或不方便并行化。然而,在使用并行 Stream 加速代码之前,你必须确保用得对;如果结果错了,算得快就毫无意义了。让我们来看一个常见的陷阱。
分支/合并框架
分支/合并框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。它是 ExecutorService 接口的一个实现,它把子任务分配给线程池(称为 ForkJoinPool )中的工作线程。首先来看看如何定义任务和子任务。
RecursiveTask:
要把任务提交到这个池, 必须创建 RecursiveTask
protected abstract R compute();
这个方法同时定义了将任务拆分成子任务的逻辑,以及无法再拆分或不方便再拆分时,生成单个子任务结果的逻辑。正由于此,这个方法的实现类似于下面的伪代码:
if (任务足够小或不可分) {
顺序计算该任务
} else {
将任务分成两个子任务
递归调用本方法,拆分每个子任务,等待所有子任务完成
合并每个子任务的结果
}
使用分支/合并框架的最佳做法:
虽然分支/合并框架还算简单易用,不幸的是它也很容易被误用。以下是几个有效使用它的最佳做法。
- 对一个任务调用 join 方法会阻塞调用方,直到该任务做出结果。因此,有必要在两个子任务的计算都开始之后再调用它。否则,你得到的版本会比原始的顺序算法更慢更复杂,因为每个子任务都必须等待另一个子任务完成才能启动。
- 不应该在 RecursiveTask 内部使用 ForkJoinPool 的 invoke 方法。相反,你应该始终直接调用 compute 或 fork 方法,只有顺序代码才应该用 invoke 来启动并行计算。
- 对子任务调用 fork 方法可以把它排进 ForkJoinPool 。同时对左边和右边的子任务调用它似乎很自然,但这样做的效率要比直接对其中一个调用 compute 低。这样做你可以为其中一个子任务重用同一线程,从而避免在线程池中多分配一个任务造成的开销。
- 调试使用分支/合并框架的并行计算可能有点棘手。特别是你平常都在你喜欢的IDE里面看栈跟踪(stack trace)来找问题,但放在分支合并计算上就不行了,因为调用 compute的线程并不是概念上的调用方,后者是调用 fork 的那个。
- 和并行流一样,你不应理所当然地认为在多核处理器上使用分支/合并框架就比顺序计算快。我们已经说过,一个任务可以分解成多个独立的子任务,才能让性能在并行化时有所提升。所有这些子任务的运行时间都应该比分出新任务所花的时间长;一个惯用方法是把输入/输出放在一个子任务里,计算放在另一个里,这样计算就可以和输入/输出同时进行。此外,在比较同一算法的顺序和并行版本的性能时还有别的因素要考虑。就像任何其他Java代码一样,分支/合并框架需要“预热”或者说要执行几遍才会被JIT编译器优化。这就是为什么在测量性能之前跑几遍程序很重要,我们的测试框架就是这么做的。同时还要知道,编译器内置的优化可能会为顺序版本带来一些优势(例如执行死码分析——删去从未被使用的计算) 。
Spliterator:
Spliterator 是Java 8中加入的另一个新接口;这个名字代表“可分迭代器” (splitable iterator) 。和 Iterator 一样, Spliterator 也用于遍历数据源中的元素,但它是为了并行执行而设计的。虽然在实践中可能用不着自己开发 Spliterator ,但了解一下它的实现方式会让你对并行流的工作原理有更深入的了解。Java 8已经为集合框架中包含的所有数据结构提供了一个默认的 Spliterator 实现。 集合实现了 Spliterator 接口, 接口提供了一个 spliterator 方法。
public interface Spliterator {
boolean tryAdvance(Consumer action);
Spliterator trySplit();
long estimateSize();
int characteristics();
}
与往常一样, T 是 Spliterator 遍历的元素的类型。 tryAdvance 方法的行为类似于普通的Iterator ,因为它会按顺序一个一个使用 Spliterator 中的元素,并且如果还有其他元素要遍历就返回 true 。 但 trySplit 是专为 Spliterator 接口设计的, 因为它可以把一些元素划出去分给第二个 Spliterator (由该方法返回) ,让它们两个并行处理。 Spliterator 还可通过estimateSize 方法估计还剩下多少元素要遍历,因为即使不那么确切,能快速算出来是一个值也有助于让拆分均匀一点。
流拆分过程:
将 Stream 拆分成多个部分的算法是一个递归过程,第一步是对第一个Spliterator 调用 trySplit ,生成第二个 Spliterator 。第二步对这两个 Spliterator 调用trySplit ,这样总共就有了四个 Spliterator 。这个框架不断对 Spliterator 调用 trySplit直到它返回 null ,表明它处理的数据结构不能再分割,最后,这个递归拆分过程到第四步就终止了,这时所有的 Spliterator 在调用 trySplit 时都返回了 null 。
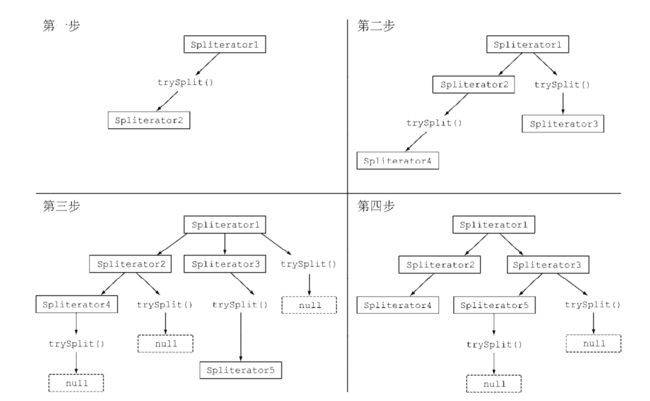
这个拆分过程也受 Spliterator 本身的特性影响,而特性是通过 characteristics 方法声明的,它将返回一个 int ,代表 Spliterator 本身特性集的编码。使用 Spliterator 的客户可以用这些特性来更好地控制和优化它的使用。
如果还想继续了解,可以继续看Java8使用(下)
部分内容引用于:https://www.runoob.com/java/java8-new-features.html