工具篇
tensorboard的使用
graph的可视化, 以及获取必要的运行时的统计数据, 请参考: 官方教程, 通过对graph以及运行时的统计数据的可视化,我们可以看看了解更多的更加直观的信息. 下图是一个例子:
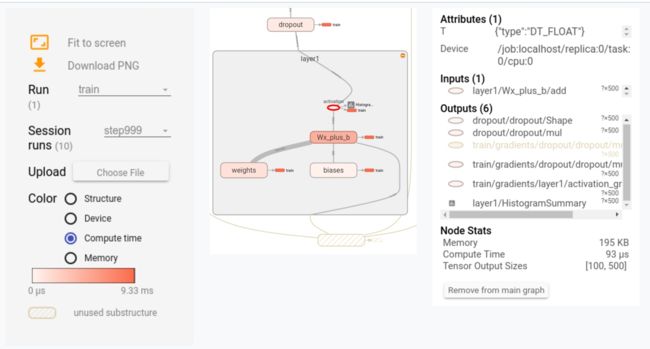
运行时的统计信息统计的是每一个step(或者一次运行)过程中, 每个op的耗时. 结合compute time 图, 我们可以分析一个图中不同的op大概的耗时是什么样子的, 这样可以定位出热点, 针对性的优化. 通过结合device图, 观察在不同的device上op是怎么分布的, tensor是怎么在不同device上流动的, 是否有跨设备的大的tensor流动. 结合memory图, 我们可以看看内存/显存的使用情况.
这个图可以给出一个定性的观察, 让你确定真实的model和你心目中的model没有太大的差别. 如果发现了一些预料之外的数据流动, 或者预料之外的耗时的点, 又或是一些op的device不如所期望, 那么, 你可能发现了一个优化的点.
这个图的问题在于, 不够细致和全面. 比如, 这个图里面就没有体现不同设备之间的数据的send/recv的op和耗时, 不同设备的带宽不同, 所以仅仅从tensor大小并不足以体现时间的消耗. 也没有办法分辨出哪些op是并行的. 在这种情况下, 去找整个运行的关键路径比较麻烦. 如果想要知道这些op在不同设备上是怎么依次执行的, 就需要timeline的帮助.
timeline的使用
timeline是一个时序图, 将每个op的运行开始时间, 结束时间, 运行设备, op的前置op, 后置op都在图上列举出来了. 怎样在代码里面生成timeline信息, 请参考HowTo profile TensorFlow.
下面以单机的一个timeline的例子来说明怎么看timeline图:

从上图可以看出, 这个step耗时约为1400ms. 其中,gpu的利用率比较低, 因为gpu只有一小段时间在运行计算. cpu的主要的一个耗时的操作为一个叫InTopK的op, 这个op消耗了大部分的时间. 里面还有一些Recv op, 这些op的意思是从别的设备(不同的机器/同一台机器不同的设备, 在这里是从内存)接收数据, 这种op虽然显示耗时很长, 但是因为这些op都是从step的一开始就运行, 然后等待数据ready, 所以在timeline上的耗时并不一定是真实的接收数据的耗时, 而是 等待+接收数据 的耗时. 另一个需要注意的是名为:/job:localhost/replica:0/task:0/gpu:0 compute的信息, 这个部分虽然标记了gpu, 它实际上是运行在cpu上, 作用是把运算发送到gpu上计算. 真是的gpu计算在/gpu:0/stream:all compute部分.
点击一个op, 比如图中的QueueDequeueManyV2, 我们可以得到这个op的信息(注意下图和上面的图不是同一个timeline). 见下图.

timeline还有一些其他的操作, 比如不同的模式下的操作,比如选择一个区间看这个区间的总的op耗时等等. 这些大家可以点击timeline窗口右上角的问号查看帮助, 慢慢探索.
对于一个timeline:
- 我们可以先看看整个timeline的时间消耗, 这个时间应该和我们通过代码测量出的时间差不多, 如果这个时间和代码中测量的每个step的平均时间差得比较远, 那说明这个step里面可能包括了一些普通的step里面没有的东西. 比如我们每隔一些step会做summary和evaluation, 如果timeline的step正好是这种step, 测量出的时间就会偏差较大. 一般的,尽量让timeline所在的step和普通step的是一样的, 便于发现问题.
- 查看看看cpu和gpu的使用情况. 在整个step中, 了解cpu和gpu的运算大概运行了多少时间. 因为gpu的高效性, 一般情况下, 尽可能的优先利用gpu, 提高gpu的使用率. 下面是一个好的例子, gpu的利用率很高, cpu完成必要的操作, 数据io和计算并行良好.
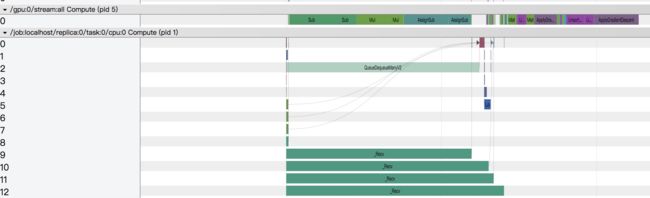
在cpu或者gpu上, 因为会存在op并行的情况, 我们可以大概看一下哪些op是关键路径, 哪些op的耗时比较多. 对于常规的任务而言, 大体可以分为io和计算两部分. io包括数据io和网络通信等, 而计算部分则是各种计算操作. 可以先了解这两部分的耗时, 做到心里有数.
单机优化例子
这个部分, 记录了我们借助timeline, 对于一个单机的模型进行优化的情况.
优化IO
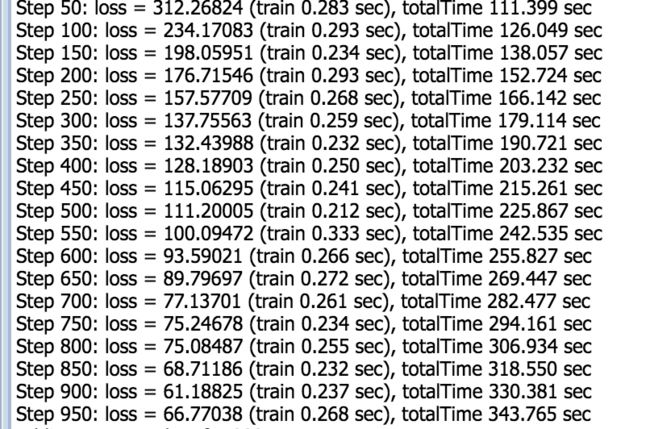
下图是模型的初始timeline.

从上图可以看出, 一个step的耗时约为300ms.这个和我们代码测量出的是一致的. 说明这个timeline可以反映普遍的情况.
观察timeline可以看到:
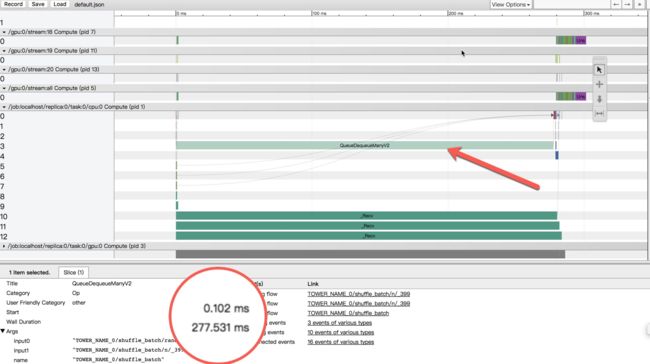
QueueDequeueMany耗时占比超过90%(277/300, 近似计算). 而gpu和gpu上的计算在这个op完成之后才开始进行. QueueDequeueMany可以近似的认为是io读取数据, 所以在这个timeline中, 实际的cpu的计算和gpu的计算耗时比较少, io是一个瓶颈. 针对这个问题, 我们进行了数据读取的优化. 优化后的timeline如下:

虽然QueueDequeueMany看起来在timeline中的占比还是很大, 但是整体的耗时变成了约100ms, QueueDequeueMany操作时间优化到了77ms. timeline的结果和代码测量是结果也是相符的.

可以看到, 通过减少关键路径的耗时, 我们将性能提升了100%.
避免feeddict
一般的, 使用feeddict的方式, 会将所有的输入数据先全部读取到内存中, 然后在feed进去, 执行计算. 这样, 数据io和计算被完全分开了, 所有的计算都必须在数据读取完成之后才能进行. 但是如果全部交给tf调度, tf会尝试将各种op做一定程度的并行, 这会带来性能的提升, 也就是数据读取的操作和其他的操作其实可以有一定程度上的并行(尤其是有多种输入数据的时候). 从别人的经验来看, 不使用feeddict可以带来一定幅度的性能提升, 这是一个优化feedict带来30%+性能提升的例子. 在我们的实践中, 避免使用feeddict方式也会带来一些性能的提升, 但是幅度没有那么高.
注意summary的耗时
这也是新手常犯的一个错误, 因为新手对于tf不熟悉, 所以并不太清楚不同的函数会添加什么op. 而summary在对于一些变量做summary的时候, 会对相应的变量进行计算. 因为最后运行的时候一般会把所有的sumamry打包运行, 所以通过run的参数看不出你做了哪些summary. 你需要确保这些操作是你预料之中的. 比如在我们的情况中, 我们遇到了一个非常耗时的inTopK操作:

而这个InTopK操作只有在计算recall的时候才会有, 而我们无意中把recall加了summary. 因为我们在计算loss的时候会做summary, 所以每次都带上了计算recall. 在tf的程序中, 很多的地方都会加summary, 便于在tensorboard中做可视化, 但是稍微不注意, 就可能执行很多你意料之外的op.
根据应用量体裁衣优化
对于使用双gpu组成塔式结构, 一个常见的行为是将变量定义在cpu上, 然后在cpu上做梯度的Average. 很多的网上的代码都是这个套路. 但是实际上, 根据模型的不同, 这个经验并不一定是最优的. 在我们的模型中,我们发现,当模型的参数变大之后, 如果适度把一些变量和计算挪动到gpu上, 那么可以省下非常可观的时间. 下面是不同方案每个batch的时间.

下面两个分别是cpu方案和gpu方案的timeline.可以看到, 原来的方案中, 会在cpu上会做大量的运算.
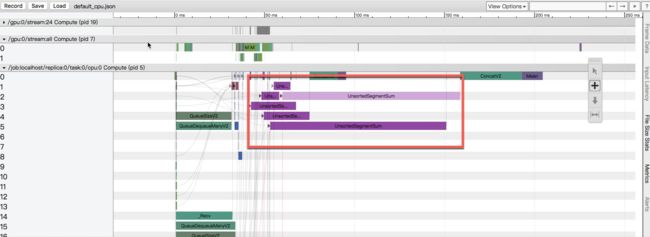
优化后, cpu上的运算被挪动到了gpu上, gpu的计算耗时远远小于gpu, 而整体的耗时也因此得到了优化.
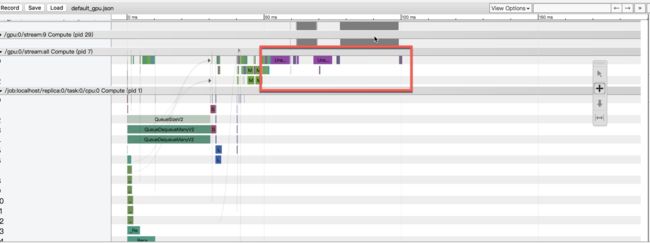
对特定的应用和模型, 需要识别出相应的热点, 合理安排运算的次序和位置. 对于网上的代码和经验,在使用的同时, 心里多带个问号.
分布式的优化例子
相对于单机的程序, 分布式的程序除了优化单机效率之外, 另外一个重点是优化分布式通信. tensorflow的grpc通信本身存在一定的性能上的问题,参看这个issue, 但是很多的应用的慢并不一定是因为这个原因导致的性能问题. 所以不要觉得分布式的性能慢是理所当然的, 除非你能确定问题是因为底层的grpc引起的(即使这样,也有优化的途径), 否则, 不要让这种成见影响了你对整体的理解和性能的追求.
在我们的实践中, 我们针对我们模型采用between-graph方式做了分布式, 这里, 我们把关注点放在了对于通信的优化. 通过控制通信,我们达到了和单机一样的性能和线性的加速比. 从下图可以看到,采用10个ps, 10个worker的情况下, 相比起单机获得了10倍的计算加速.

以下是实践中的一些经验.
每个worker使用多个GPU
为了减少通信, 如果每个机器上有多个个gpu, 因为gpu与cpu的带宽远远大于网络带宽, 所以让每个worker使用多个gpu有助于降低通信开销, 提升性能. 在我们的例子中, 每个机器有两个gpu, 所以我们采取了每个worker使用两个GPU的方式, 这样10个worker可以利用20张卡, 而机器之间的通信开销可以减少一半. 同时我们保持ps和worker的比例为1:1. 这样, 对worker和ps, 分布式带来的额外的通信的压力基本上是一样的, 避免出现瓶颈. 对于每个变量, 使用partitioner进行分片, 使得ps的负载更为均衡.
push和pull优化
每个step, 因为变量定义在ps上, 所以理论情况下, 每个worker需要将特定的变量从ps, pull到本地进行计算; 计算好的梯度需要push到ps上. 对于这个push和pull操作, 需要大概清楚它的通信量的大小, 做到心中有数. 你可以利用你的知识和你对模型的理解, 将这个通信量降低.
pull优化.
在下面的timeline中, 可以看到,ps和worker的耗时都非常长.

进一步细看可以发现, gpu的计算在数据io完成之后迟迟不能开始.

进一步结合ps上的数据发送和估计数据的大小, 可以发现, 时间消耗在从ps接受数据上.
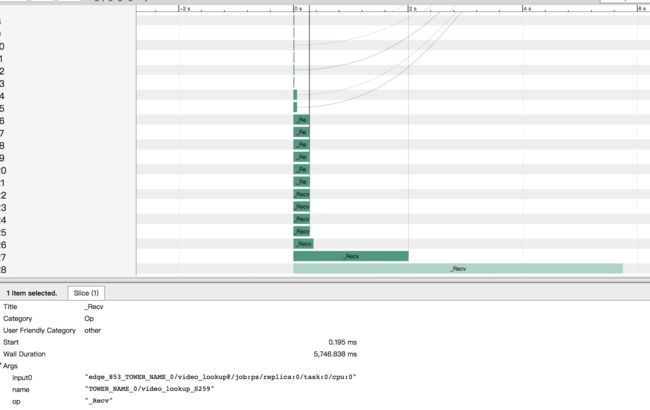
除此之外, 我们还发现一个现象, 就是我们观察到分布式每个step的worer和ps的通信耗时随着batchsize的变大而变大(这里需要一点计算和假设去分离各种时间), 而导致整个计算非常缓慢. 这个与直觉不相符, 因为每次通信应该获取的数据应该是常量才对, 就算batchsize变大也不应该剧烈变化.
我们查看了一下相关的实现源码, 发现在tf的一些函数中,比如embeding_lookup中,会要求一些op和变量定义到同样的device上, 这是tf的优化操作, 这个优化会无视外层的device placement. 这种优化导致每次从PS获取的数据量并不是固定的, 而是和batchsize相关.
在embedding_lookup函数, 它有一个params参数, 也就是我们的embedding tensor, 我们会从这个大的tensor中, 根据ids, 选出一部分tensor进行计算.
embedding_lookup(
params, # 我们的embedding tensor.
ids,
partition_strategy="mod",
name=None,
validate_indices=True, # pylint: disable=unused-argument
max_norm=None)
根据这个函数的实现代码, 它会要求params(embedding tensor)和相应的gather op定义到同一个device上.
在分布式情况下,也就是PS上. 这样做的目的是优化通信, 因为一般情况下, embedding tensor非常大, 但是每次需要lookup取出的tensor在一般情况下比较小, 所以这个操作放到PS上, 使得最后传输到worker上的数据量会变小很多.
但是我们发现在我们的模型中, 这个优化变成了一个负优化. 因为我们每次需要取出 $batchsize * 10$ 个向量, embedding tensor的大小和batchsize差不多(我们用了比较大的batchsize), 所以这个tf的优化操作导致通信的代价增加了10倍,而且会随着batchsize的增大而增大. 下面是相应的timeline.
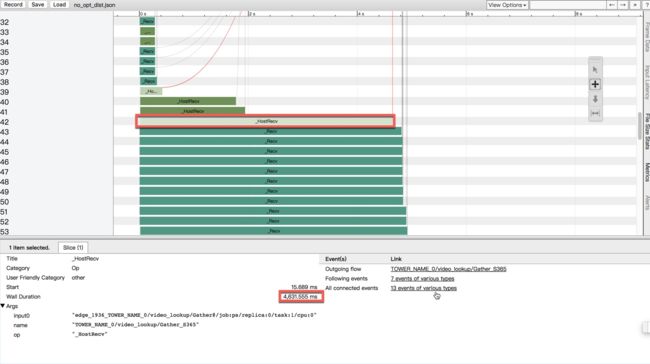
从这个图上可以看出,recv耗时较长. 但是因为recv在timeline上的耗时并不一定是是真实的耗时,有可能是在等待. 所以这个耗时长只是一个疑点, 沿着这个线索, 通过分析ps的send发生的时间, 结合我们模型的数据大小, 计算通信的开销之后我们发现, 这个Recv确实很耗时, 通信开销占了整个step的大头.
了解了问题的原因之后,对于这种情况,我们采取了将embedding pull到本地的方法:
#下面的一行identity将变量pull到本地. 这里的variable就是上面提到的的embedding tensor
variable_copy = tf.identity(variable)
x = tf.embedding_lookup(variable_copy)
identify读取variable, 产生一个等价tensor. 在分布式的情况下, 这个op定义在worker上, 相当于把variable从ps读取到本地. 通过这样的操作, 我们把通信量变成一个固定值, 优化了网络通信. 优化后的timeline如下:

可以看到, gpu上的计算在数据IO完成之后立即开始(说明一些变量已经在数据io的同时pull到本地了), 并且很快计算完成. 说明我们的pull优化起效果了.
push优化
通过观察pull优化之后的timeline, 我们发现worker计算完成之后, ps确迟迟不结束. 我们分析ps的timeline, 见下图:
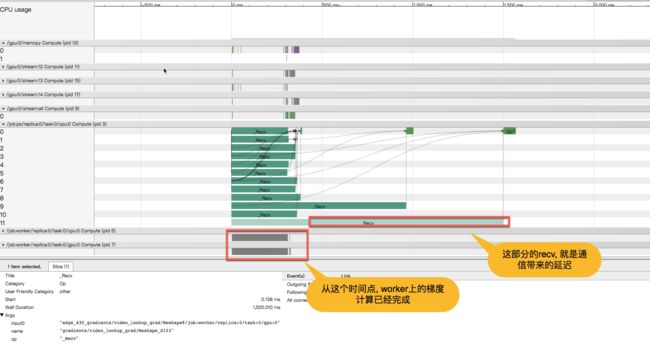
原因和pull的情况类似, 因为我们是从embedding_lookup中获取tensor进行计算, 所以tf将最后的梯度用IndexedSlices表示, 这种表示导致梯度的大小不仅和变量相关,而是和输入相关. 因为我们的batchsize比较大, 相比起所以带了了一些不必要的通信量, 从timeline看, 耗时较多. 所以我们采取了如下操作:
grads_and_vars = [(tf.multiply(grad, 1), var) for grad, var in grads_and_vars]
这个做的是将应用于同一个变量的梯度变成一个固定大小的tensor, 不使用稀疏表示 去控制通信.
最终优化了push和pull之后的pipeline如下:

可以看到, gpu的利用率大大提高, cpu中耗时的操作为数据io, 而gpu上的op在数据io完成后即开始, ps的时间消耗仅仅是略多于worker(因为最后需要在ps上做apply grandent).
后记
上述就是我们优化的过程.
单机的部分注意一下op和变量的placement, 手动控制的时候不要迷信经验, 要有充分的理由, 大部分情况下tensorflow的placement做的其实还不错, 在显存足够并且cpu上的op不多的时候, 都放到gpu上即可. 分布式的情况, tf会做一些性能优化, 但是tf的placement存在一定的问题, 算法其实可以比现在更加智能和数据驱动, 因为placement对通信影响很大, 如果发现tf犯了错误, 可以适度进行手工干预. 不管是单机还是分布式, 更快的io永远是值得追求的, 也有很多的优化的方法.
总结一下, 性能调优需要注意细节, 对每个操作的情况做到心中有数. 对于一些异常现象(比如我们上面碰到的因为colocation, 外层的device placement被无视),可以求诸源码. 对于可能存在的性能问题, 需要大胆假设, 小心求证. 在优化的时候, 注意投入产出, 随着优化的进行, 系统的瓶颈也会变化. 比如把数据io时间从1000ms优化到100ms可以带来性能提升2倍, 花更大的精力继续从100ms优化到5ms可能并不会带来整体性能的提升, 因为这个时候数据io可能已经不是瓶颈了.