鸢尾花预测:如何创建机器学习Web应用程序?
全文共2485字,预计学习时长12分钟

图源:unsplash
数据科学的生命周期主要包括数据收集、数据清理、探索性数据分析、模型构建和模型部署。作为数据科学家或机器学习工程师,能够部署数据科学项目非常重要,这有助于完成数据科学生命周期。通过既有框架(如Django或Flask)对传统机器学习模型进行部署,可能是一项艰巨耗时的任务。
本文就将展示如何在Python库中使用streamlit,用不到50行的代码构建一个简单的基于机器学习的数据科学web应用程序。

数据科学生命周期

鸢尾花预测应用程序概述
我们将构建一个简单的机器学习web应用程序,用于预测鸢尾花的类标签,包括setosa、versicolor和virginica。这需要用到三个Python库,即streamlit、pandas和scikitlearn。
应用程序的概念流程主要由两个部分组成:前端和后端。

图源:unsplash
在前端,左侧栏将接受与鸢尾花特征(如花瓣长度、花瓣宽度、萼片长度和萼片宽度)相关的输入参数。这些特性会被传送到后端,后端的训练模型将预测类标签作为输入参数的函数,预测结果再发回前端显示。
在后端,用户输入的参数将被保存到一个数据帧中作为测试数据。同时,利用scikit-learn库中的随机森林算法建立分类模型。最后,将该模型应用于预测用户输入的数据,并将预测的类标签返回到三种花卉类型:setosa、versicolor或virginica。此外,该模型还能够预测概率,从而辨别预测类标签的相对可信度。
安装必备库
本教程使用到的三个Python库——streamlit, pandas 和 scikit-learn,可以通过pip install命令进行安装。
安装streamlit:
pip install streamlit
安装pandas:
pip install pandas安装scikit-learn:
pip install -U scikit-learn
web应用程序代码
现在就来一探究竟吧!我们要构建的应用程序只需不到50行代码(确切地说是48行),如果删除空行和注释(占12行),就可以降至36行。
import streamlit as st
import pandas as pd
from sklearn import datasets
from sklearn.ensemble importRandomForestClassifier
st.write("""
# Simple Iris Flower Prediction App
This app predicts the **Iris flower** type!
""")
st.sidebar.header('User InputParameters')
defuser_input_features():
sepal_length = st.sidebar.slider('Sepal length', 4.3, 7.9, 5.4)
sepal_width = st.sidebar.slider('Sepal width', 2.0, 4.4, 3.4)
petal_length = st.sidebar.slider('Petal length', 1.0, 6.9, 1.3)
petal_width = st.sidebar.slider('Petal width', 0.1, 2.5, 0.2)
data = {'sepal_length': sepal_length,
'sepal_width': sepal_width,
'petal_length': petal_length,
'petal_width': petal_width}
features = pd.DataFrame(data, index=[0])
return features
df =user_input_features()
st.subheader('User Inputparameters')
st.write(df)
iris = datasets.load_iris()
X= iris.data
Y= iris.target
clf =RandomForestClassifier()
clf.fit(X, Y)
prediction = clf.predict(df)
prediction_proba= clf.predict_proba(df)
st.subheader('Class labels andtheir corresponding index number')
st.write(iris.target_names)
st.subheader('Prediction')
st.write(iris.target_names[prediction])
#st.write(prediction)
st.subheader('PredictionProbability')
st.write(prediction_proba)
逐行解读代码
来看看每一行(或代码块)的作用:
导入库
· 第1-4行:导入streamlit 和 pandas库,分别称为st和pd。具体来说,从scikitlearn库中(sklearn)导入datasets软件包,然后使用loader函数加载鸢尾花数据集(第30行)。最后将专门从sklearn.ensemble软件包中导入RandomForestClassifier()函数。
侧栏面板
· 第11行:通过使用st.sidebar.header()函数来添加侧栏的标题文本。请注意,在st和header之间使用sidebar(所以是st.sidebar.header()函数)可以向streamlit库传达信息,把标题文本放在侧栏面板中。
· 第13-23行:此处创建一个名为user_input_features()的自定义函数,该函数主要是将用户输入的参数进行整合(即4个花的特征,可以通过滑动条接受用户指定的值),并以数据帧的形式返回结果。
值得注意的是,每个输入参数都将通过滑动按钮接受用户指定的值,如st.sidebar.slider(‘Sepal length’, 4.3, 7.9, 5.4)表示萼片长度。四个输入参数中的首个参数对应于在滑动按钮上方指定的标签文本,在本例中为“萼片长度”,而接下来的两个值对应于滑动条的最小值和最大值。最后,末尾输入参数表示加载web应用程序时选择的默认值,该值设置为5.4。
模型建立
· 第25行:如上所述,以数据帧形式整合的用户输入参数信息将分配到df变量中。
· 第30-38行:该代码块适用于实际模型构建阶段。
第30行—从sklearn.datasets软件包中加载鸢尾花数据集,并将其分配给iris变量;
第31行—创建X变量,包含iris.data中提供的4个花的特征(即萼片长度,萼片宽度,花瓣长度和花瓣宽度);
第32行—创建Y变量,与iris.target中提供的鸢尾花类标签相关;
第34行—将随机森林分类器(特别是RandomForestClassifier()函数)分配给clf变量;
第35行—通过clf.fit()函数使用X和Y变量作为输入参数来训练模型。这本质上意味着通过使用4个花的特征(X)和类标签(Y)训练,来建立分类模型。

图源:unsplash
主面板
· 第6-9行:使用st.write()函数输出文本,在本示例中使用该函数,以标记格式输出此应用程序的标题。使用#符号表示标题文本(第7行),而后一行(第8行)提供应用程序的正常描述性文本。
· 第27-28行:第一部分将给出“User Input parameters”的子标题文本(使用st.subheader函数进行分配)。下一行将通过使用st.write()函数来显示df数据帧的内容。
· 第40-41行:在主面板的第二部分中,输出类标签(即setosa、versicolor和virginica)及其相应索引号(即0、1和2)。
· 第43-44行:主面板的第三部分显示的是预测类标签。此处需要注意的是,prediction变量的内容(第45行)是预测的类索引号,如果要显示类标签(即setosa、versicolor和virginica),则需在iris.target_names[prediction]的括号内使用prediction变量作为参数。
· 第47-48行:主面板的第四部分也就是最后一部分显示了预测概率。该概率值能够识别预测类标签的相对可信度(概率值越高,该预测的可信度就越高)。
运行web应用程序
因此,web应用程序的代码被保存到iris-ml-app.py文件中,现在准备运行。可以在命令提示符(终端窗口)中输入以下命令来运行该应用程序:
streamlit run iris-ml-app.py
之后会看到以下消息:
> streamlit run iris-ml-app.pyYou can now view yourStreamlit app in your browser.Local URL: http://localhost:8501
Network URL: http://10.0.0.11:8501
几秒钟会弹出一个互联网浏览器窗口,通过网址http://localhost:8501引导用户进入创建的web应用程序 ,如下所示:
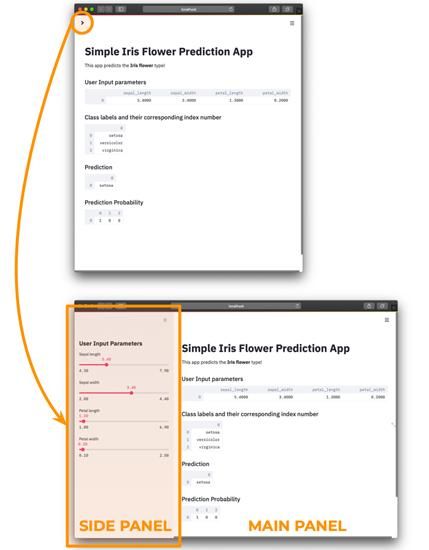
鸢尾花预测应用程序截图。点击左上角按钮(顶部窗口)可以显示侧面板(底部窗口)。
大功告成!用Python创建了机器学习web应用程序就是这么简单,快去亲自操作一下吧。

一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)