one-stage-anchor-free CenterNet:Objects as Points
paper:https://arxiv.org/pdf/1904.07850.pdf
官方代码:https://github.com/xingyizhou/CenterNet
我的代码:https://github.com/panchengl/centernet_prune
首先提一下我的代码复现(torch),官方代码支持包括2d目标检测、3d检测、姿态估计任务,我移除了其他的任务,并简单的重构了代码,使得代码更加易读,然后基于我改后的代码完成了模型压缩(剪枝方案),并添加使用了VOC的测试方法(ap50),然后在自己的数据集(复杂场景上)上完成了测试,模型压缩力度还是比较大,而且精度损失很小,有兴趣的同学可以基于我的代码进行二次开发。
总体印象:
我认为结构最优雅的anchor-free算法,没有太多的tricks,效果却很惊艳,可能也是由于模型的原理特点,在误检方面控制得很好,速度跑起来飞快,而且在结构上扩展性好,各种backbone、deformconv、其实都可以随便加,主要精髓就在于特征提取+points回归,并且可以应用到其他任务,相当优秀了,就是落地有点麻烦(至芯片端),后处理不太好做,只能将后处理重写,将其封装在onnx里面,据我所知,有芯片厂商是已经支持该算法的了。
文章解决的问题:
1、cornernet、extremenet检测关键点,但是需要一个grouping的阶段,降低速度,且会导致一个匹配错误等类型的误检
作者依次提出了直接检测每个目标的中心点来处理,避免grouping,端到端,速度快,不需要nms(但是作者源码是使用了nms的(可选),多尺度检测的时候必须要使用)。
文章思路(侧重于2d检测的分析):
构建模型时,使用backbone来获取目标的热力图,找到目标的中心点(关键点),热力图峰值点即为关键点,并根据中心点,回归出中心点到边界的距离(宽高信息),连fpn的多级预测都没有使用,2d回归的是中心点到两个边界的距离,3dbbox检测回归bbox尺寸和深度信息、朝向,人体姿态估计回归中心点到关节点的偏移量。
方法创新点:
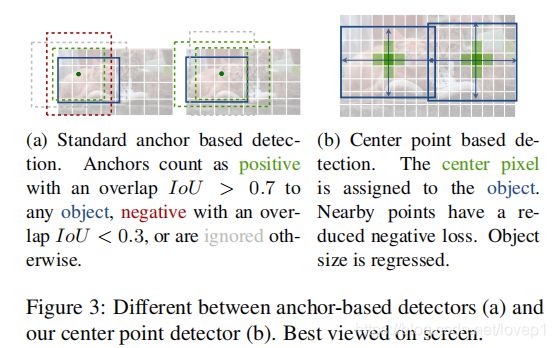
1、关键点-中心点可以看成是一个形状未知的anchor,但没有尺寸框,没有手动设置的阈值做分类,如下图所示。
2、每个目标仅有一个正的中心点,不会用到nms,直接提取关键点特征图的局部峰值点,且训练样本可以认为positive examples多。
3、使用更大的分辨率输出特征图,但总体而言只下采样了4倍,无需用到多级预测关键点
文章思路-Preliminary-如何预测关键点:
令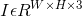 为输入图像,目标是生成关键点热力图
为输入图像,目标是生成关键点热力图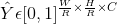 ,其中W、H是输入图像的宽和高,R是输出stride(尺寸缩放比例)
,其中W、H是输入图像的宽和高,R是输出stride(尺寸缩放比例)
,C是关键点类型数(特征图的通道数),其中,C根据任务不一致定义不同,2d目标检测为类别数,人体姿态估计为17-人体关节点数。默认下采样为4,由于大分辨率,下采样比例小,认为可以不需要多级预测,也不需要nms。 表示检测到的关键点,
表示检测到的关键点,
表示背景。使用了多个backbone来预测图像的得到  ,包括dla34、resnet+dcn、hourglass
,包括dla34、resnet+dcn、hourglass
对于GT的关键点c,其位置为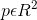 ,计算得到低分辨率上对应的关键点
,计算得到低分辨率上对应的关键点 ,然后我们利用高斯核
,然后我们利用高斯核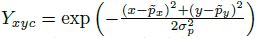 ,将关键点离散到热力图
,将关键点离散到热力图 上,其中
上,其中 是目标尺度自适应的标准方差。如果对于同类别c有两个高斯函数发生重叠,我们选择元素级最大的,训练时的目标函数如下,使用像素级别的focal-loss:
是目标尺度自适应的标准方差。如果对于同类别c有两个高斯函数发生重叠,我们选择元素级最大的,训练时的目标函数如下,使用像素级别的focal-loss:

由于图像下采样时,GT的关键点会因为数据是离散的而发生偏差,因此我们对每个中心点附加预测了局部偏移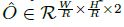 ,所有类别c共享同一个局部偏移,这个偏移使用L1 loss来训练,如下式:
,所有类别c共享同一个局部偏移,这个偏移使用L1 loss来训练,如下式:

只在关键点 做监督性学习。
做监督性学习。
难点1:
将关键点利用高斯核离散:code中考虑了3种情况对高斯核进行离散,具体可以参考github的issues,我记得有一个issues是作者回复的,亲自提到了这个问题,其实主要内容如下。
参考该博文:https://zhuanlan.zhihu.com/p/165313457
https://zhuanlan.zhihu.com/p/76378871 (该文章认为中心点直接离散成圆合适,应该离散成椭圆,我认为有一定的道理,但是据说效果反而没那么好。。。。。)
简单理解一下文章的意思(如果懒得看大佬的文章就直接看我这一段简介就好):
首先,centernet用了很多cornernet的祖传代码(这个词有点秀啊), 所以如何计算高斯半径也是用cornernet的方式。我们回头看看cornernet的计算方式,如下图左图所示,红色的是标注框,但绿色的其实也可以作为最终的检测结果保留下来。那么这个问题 可以转化为绿框在红框多大范围以内可以被接受。使用IOU来衡量红框和绿框的贴合程度,当两者IOU>0.7的时候,认为绿框也可以被接受,反之则不被接受。

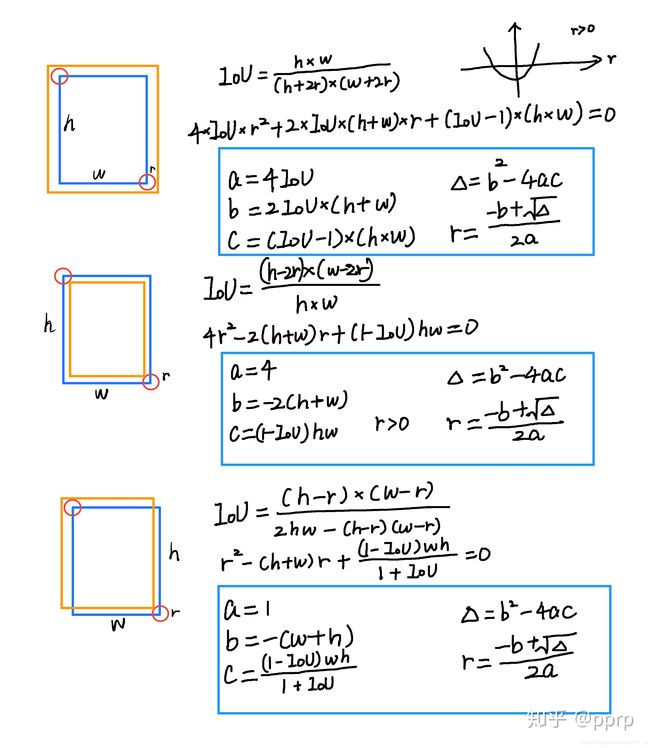
那如何确定半径r, 让红框和绿框的IOU大于0.7?如上图右图所示,有三种情况,其中蓝框代表标注框,橙色代表可能满足要求的框。这个问题最终变为了一个一元二次方程有解的问题,同时由于半径必须为正数,所以r的取值就可以通过求根公式获得。所以出现了gaussian_radius函数用来获取高斯半径(issue:https://github.com/princeton-vl/CornerNet/issues/110)。
同样,centernet也是用该函数获取高斯半径,也是求根公式,只不过高斯点在中心,所以同样适用,据我引用的大佬文章所说,cornernet和centernet还有bug,写错了公式,如果修改以后召回率还会提升一点。。。
code中利用gaussian_radius(如何获取高斯半径)和draw_msra_gaussian(如何将高斯分布分散到heatmap上)两个函数来create heatmap,简单来说,就是根据目标尺寸算一个自适应的高斯核半径,然后全图构造heatmap。
文章思路-Objects as Points:
1、如何利用关键点来做目标检测
令 是目标 k (其类别为
是目标 k (其类别为  )的bbox. 其中心位置为
)的bbox. 其中心位置为 
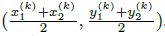 ,我们用 关键点估计
,我们用 关键点估计 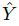 来得到所有的中心点,此外,为每个目标 k 回归出目标的尺寸
来得到所有的中心点,此外,为每个目标 k 回归出目标的尺寸  。为了减少计算负担,我们为每个目标种类使用单一的尺寸预测
。为了减少计算负担,我们为每个目标种类使用单一的尺寸预测  ,我们在中心点位置添加了 L1 loss:
,我们在中心点位置添加了 L1 loss:

我们不将scale进行归一化,直接使用原始像素坐标。为了调节该loss的影响,将其乘了个系数,整个训练的目标loss函数为:
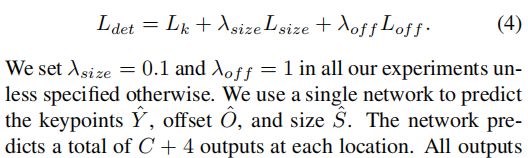
整个网络输出C+4个值(即关键点类别C+偏移量x,y+尺寸w,h),所有输出共享一个全卷积的backbone, 这里提一点偏移损失的计算:作者code中使用的是原始目标中心点减去取整后的中心点,算得的值为off的gt(如果理解有错欢迎指出),原始代码如下:
![]()
但是这个偏移这一点是可选的,有没有作者认为关系不大,精度损失一点点。
2、 从点到bbox:
在推理的时候,我们分别提取热力图上每个类别的峰值点。如何得到这些峰值点呢?做法是将热力图上的所有响应点与其连接的8个临近点进行比较,如果该点响应值大于或等于其八个临近点值则保留,最后我们保留所有满足之前要求的前100个峰值点。令  是检测到的 c 类别的 n 个中心点的集合。
是检测到的 c 类别的 n 个中心点的集合。 每个关键点以整型坐标
每个关键点以整型坐标 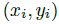 的形式给出。
的形式给出。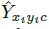 作为测量得到的检测置信度, 产生如下的bbox:
作为测量得到的检测置信度, 产生如下的bbox:
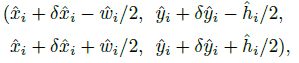
其中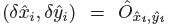 是偏移预测结果;
是偏移预测结果;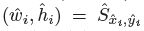 是尺度预测结果;所有的输出都直接从关键点估计得到,无需基于IOU的NMS或者其他后处理。
是尺度预测结果;所有的输出都直接从关键点估计得到,无需基于IOU的NMS或者其他后处理。
3D检测和人体姿态估计(略)
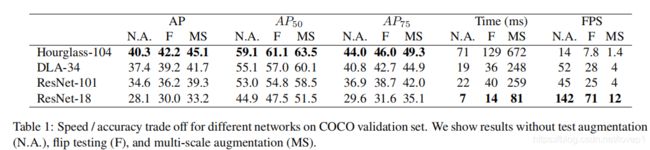
有个现象可能需要引起注意,我利用centernet在做自己的数据集训练和测试时,出现了3点与文章有差异的地方:
1、dla34的backbone与官方(paper:Deep Layer Aggregation )的dla34结构不一致,做了进一步的特征融合,但源码中也提供了官方结构的code,但paper没有测试,我也没有训练和测试过,改进的dla34的结构效果很好。
2、改进的dla34效果比resnet、houglass104效果更好?-在我自己的数据集上-这一点可能是超参数的问题,也有可能跟数据场景有关系,但我更怀疑是数据场景的差异
3、文中dla34的速度号称在2080Ti上可以做到超实时,我当时估算了一下在paper说的20ms左右,但实际测试差不多需要50ms,原因是复杂的后处理,paper极有可能说的是gpu端的前向推理时间(这个时间确实只需要20ms左右),此点也有可能是我测试错误
接下来给出paper官方提供的对网络改动描述(适应于centernet只输出一层feature-map的热图)
1、houglass
堆叠的Hourglass网络通过两个连续的hourglass 模块对输入进行了4倍的下采样,每个hourglass 模块是个对称的5层 下和上卷积网络,且带有skip连接。该网络较大,但通常会生成最好的关键点估计。
2、resnet
对标准的ResNet做了3个up-convolutional网络来得到更高的分辨率输出(最终stride为4)。为了节省计算量,我们改变这3个up-convolutional的输出通道数分别为256,128,64。up-convolutional核初始为双线性插值。
3、DLA
即Deep Layer Aggregation (DLA),是带多级跳跃连接的图像分类网络,我们采用全卷积上采样版的DLA,用deformable卷积来跳跃连接低层和输出层;将原来上采样层的卷积都替换成3x3的deformable卷积。在每个输出head前加了一个3x3x256的卷积,然后做1x1卷积得到期望输出(与原始paper是不一致的,这个地方我看了两周的代码,贼坑)。
参考:
https://zhuanlan.zhihu.com/p/66048276