centernet: objects as points
轻松掌握 MMDetection 中常用算法(七):CenterNet - 知乎文@ 0000070 摘要 在大家的千呼万唤中,MMDetection 支持 CenterNet 了!! CenterNet 全称为 Objects as Points,因其极其简单优雅的设计、任务扩展性强、高速的推理速度、有竞争力的精度以及无需 NMS 后处理等优… https://zhuanlan.zhihu.com/p/374891478扔掉anchor!真正的CenterNet——Objects as Points论文解读 - 知乎前言anchor-free目标检测属于anchor-free系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于one-stage和two-stage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet…https://zhuanlan.zhihu.com/p/66048276《目标检测》-第10章-anchor-free之CenterNet的浅析与实现 - 知乎更新:2021-7-4 近来,在这个CenterNet的工作基础上,我又实现了一版新的CenterNet,是一次增量式的改进,命名为CenterNet-plus,依旧没有DCN,同时也将原先的Deconv替换成了“插值+1x1卷积”的简单模块。具体结构…https://zhuanlan.zhihu.com/p/157134580说点Cornernet/Centernet代码里面GT heatmap里面如何应用高斯散射核 - 知乎最近在看anchor-free的论文,可能是以前anchor-base的论文看多了,有了思维定势,一下还不是很好理解anchor-free,一度怀疑人生,于是打开源码开始分析。不得不说光看论文而不源码简直就是浪费作者的心血,因为很…https://zhuanlan.zhihu.com/p/96856635CenterNet算法笔记_AI之路-CSDN博客_centernet论文:Objects as Points论文链接:https://arxiv.org/abs/1904.07850代码链接:https://github.com/xingyizhou/CenterNet这篇CenterNet算法也是anchor-free类型的目标检测算法,基于点的思想和CornerNet是相似的,方法上做了较大的调整,整体上给人一种非常清爽的感觉,算法思想很朴素、直接,而且...https://blog.csdn.net/u014380165/article/details/92801206Centernet相关---尤其有关heatmap相关解释 - 知乎本人现在工作在阿里云数据智能事业部工农业研发,对工作应聘感兴趣的欢迎私信。 前言最近anchor free的工作层出不穷,趁着工作闲暇时间,精读了论文以及相关代码。其中以CenterNet最为简洁,整体思路最为清晰,代…https://zhuanlan.zhihu.com/p/85194783
https://zhuanlan.zhihu.com/p/374891478扔掉anchor!真正的CenterNet——Objects as Points论文解读 - 知乎前言anchor-free目标检测属于anchor-free系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于one-stage和two-stage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet…https://zhuanlan.zhihu.com/p/66048276《目标检测》-第10章-anchor-free之CenterNet的浅析与实现 - 知乎更新:2021-7-4 近来,在这个CenterNet的工作基础上,我又实现了一版新的CenterNet,是一次增量式的改进,命名为CenterNet-plus,依旧没有DCN,同时也将原先的Deconv替换成了“插值+1x1卷积”的简单模块。具体结构…https://zhuanlan.zhihu.com/p/157134580说点Cornernet/Centernet代码里面GT heatmap里面如何应用高斯散射核 - 知乎最近在看anchor-free的论文,可能是以前anchor-base的论文看多了,有了思维定势,一下还不是很好理解anchor-free,一度怀疑人生,于是打开源码开始分析。不得不说光看论文而不源码简直就是浪费作者的心血,因为很…https://zhuanlan.zhihu.com/p/96856635CenterNet算法笔记_AI之路-CSDN博客_centernet论文:Objects as Points论文链接:https://arxiv.org/abs/1904.07850代码链接:https://github.com/xingyizhou/CenterNet这篇CenterNet算法也是anchor-free类型的目标检测算法,基于点的思想和CornerNet是相似的,方法上做了较大的调整,整体上给人一种非常清爽的感觉,算法思想很朴素、直接,而且...https://blog.csdn.net/u014380165/article/details/92801206Centernet相关---尤其有关heatmap相关解释 - 知乎本人现在工作在阿里云数据智能事业部工农业研发,对工作应聘感兴趣的欢迎私信。 前言最近anchor free的工作层出不穷,趁着工作闲暇时间,精读了论文以及相关代码。其中以CenterNet最为简洁,整体思路最为清晰,代…https://zhuanlan.zhihu.com/p/85194783
【Anchor Free】CenterNet的详细解析 - 知乎1 前言本文接着上一讲对CornerNet的网络结构和损失函数的解析,链接如下 周威:【Anchor free】CornerNet 网络结构深度解析(全网最详细!)周威:【Anchor free】CornerNet损失函数深度解析(全网最详细!)本文来…https://zhuanlan.zhihu.com/p/212305649 centernet这篇论文很好,我在文本检测中用过来检测固定的篡改稽查字段,唯一的问题可能就是对倾斜的框处理不了,只能检测水平框,不过这块也有改动的算法,centernet就是直接对中心点进行监督,回归wh和offset,有点像east,最后装配成bounding box。我觉得centernet核心的几个点,1.标签如何制作的?因为是对中心点,wh以及offset进行监督,那么标签就和之前anchor-based的方法不一样,中心点heatmap对应的高斯heatmap怎么制作?这块有不少疑问,我看到mmdet中目前都采用比较合理的gaussian radius生成,2.gaussian focal loss?3.网络生成的降采样feature map的decode和标签的encode?4.前向推理的一些操作。挂在arixv的论文我感觉写的不太行,很多细节都没写到,过于言简意赅了,有点yolo那味。后续等看yolov1时再来比对两种方式的异同,要理解一波。
1.Introduction
我们在对象的bounding box中心用一个点表示object。其他的属性,例如宽高可以通过直接从图像特征的中心位置回归出来。我们将图像送入fcn中生成heatmap,heatmap中的峰值对应图像中心,每个峰值处的图像特征预测对象的边界框高和宽。前向时不用nms。

上图中传统的anchor是存在正负样本划分的,anchor和gt的IOU阈值大于0.7为正样本,anchor和gt的IOU阈值小于0.3为负样本,在centernet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的,此外观察到是一个以中心绿点向四周衰减的核,在yolo中只考虑中心点位positive samples,其他的点均视为负样本,在centernet中并没有直接抛弃周围点,它是由一个高斯核函数生成的0-1之间的值,这样的分布配合gaussian focal loss对周围的点进行监督学习。
2.objects as points
下面这一节我们来解决几个核心问题。就是一开始提出的,损失函数,标签制作,监督的encode和decode和前向。
要注意几个点:1.centernet中所有的粒度都是基于点的,点即是anchor,回归的三个支路,heatmap(80),offset(2),wh(2)都是基于一个点。2.分类粒度是图片,但多标签都是图片,检测的粒度是对象,是object,xml也是一个一个object读出来检测。
2.1 网络生成的降采样feature map的decode和标签的encode?
和之前的检测网络不同的是backbone是有上采样的,例如resnet18,最终的输出是对32倍降采样的图做了3次上采样,最后输出的是相对于原图4倍降采样的图,stride=4,上采样这块mmdet把它写到了neck中,CTResNetNeck,注意的是上采样模块中用了可变性卷积(从26.0提到29.5),并且上采样是可学习的转置卷积,而非常用的双线性上采样模块,经过neck之后到CenterNetHead,会有一个conv+relu+conv结构,这里会接三个支路,分别是heatmap和wh,offset的回归支路,三个支路不共享,如下:
self.heatmap_head = self._build_head(in_channel, feat_channel,
num_classes)
self.wh_head = self._build_head(in_channel, feat_channel, 2)
self.offset_head = self._build_head(in_channel, feat_channel, 2)
def _build_head(self, in_channel, feat_channel, out_channel):
"""Build head for each branch."""
layer = nn.Sequential(
nn.Conv2d(in_channel, feat_channel, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(feat_channel, out_channel, kernel_size=1))
return layer对于coco数据集而言,heatmap是(w/4,h/4,80),wh是(w/4,h/4,2),offset是(w/4,h/4,2),注意centernet的粒度是点(anchor),heatmap,wh,offset都是相对于一个点而言的,虽然coco看起来是多标签,一次按道理是80中可能有多个类,80个feature map中的多个feature map可能都存在中心点,是不可能的,因为只想对于一个点而言,因此也只有wh,offset都是2,这三条支路的输出要和做出来的标签做监督学习,这里不想之前的faster rcnn对xywh有编码,gt_bbox,gt_target会做一下设计,然后直接监督,如下代码所示,heatmap会进行一个sigmoid的输出,产生0-1之间的预测值,wh和offset没做sigmoid处理,标签的decode即是标签制作,后面说。centernet中的loss操作是在stride=4的特征图上进行的,如果输入是512,512,那么就是在128,128的图上进行。
def forward_single(self, feat):
center_heatmap_pred = self.heatmap_head(feat).sigmoid()
wh_pred = self.wh_head(feat)
offset_pred = self.offset_head(feat)
return center_heatmap_pred, wh_pred, offset_pred2.2 gaussian focal loss

centernet的正负样本定义很简单,不用考虑iou,因为一个中心点就是一个anchor,因此正样本就是某个gt bbox中心落在哪个位置上,那么这个位置就是正样本,其余位置全部都是负样本,不像faster rcnn中分配完anchor的正负后还有一个正负样本的采样来保证正负样本的均衡,在centernet中正负样本是严重失衡的。loss的设计就非常重要。
alpha,beta分别是2,4,gaussian focal loss是由focal loss改进而来,注意式中标黄Yxyc的是标签,带标的Yxyc是预测结果,即heatmap的sigmoid后的值在0-1之间,注意Yxyc也是0-1之间的值,它是由高斯核产生的,即中心点为1,正样本,中心点往外逐渐降为0.这个式子当Yxyc时也是有标签乘在里面的,只是因为标签为1,所以不用标出了,我们来讨论一下上面这个式子:
当Yxyc=1时,带标Yxyc若接近1,说明这是一个比较容易检测出来的中心点,(1-带标Yxyc)^α就相应降低了,log函数接近0,则loss也是接近0的是比较低,说明是容易样本;若带标Yxyc接近0,说明此时中心点并没有被学到,(1-带标Yxyc)^α 就相应的增大了,log函数不接近0,此时loss函数变大了,要加大其训练的比重,说明这个中心很难学,是个难例。
当otherwise时,带标的Yxyc理论上应该接近0,不考虑(1-Yxyc)^β,若带标的Yxyc接近0,后面项整体接近0,则说明这是个很好学的负样本,但是Yxyc实际上不是一个非0即1的数,他是一个0-1之间的值,因此第一项实际上是考虑了和中心点靠的越近的点,其Yxyc是比较高的一个值,对其的惩罚是降低的,为什么越靠近中心点?其惩罚还降低了呢?按道理说,越靠近中心点,难道不是误检越高吗,为什么还要降低这种情况出现的loss呢?(实际上是由于与中心点足够接近的点构成的预测框也能够达到较好的预测效果,所以哪怕这些点对应的值本应回归为0,也通过(1-Yxyc)^β项削弱了对其的惩罚,实际上网络并不十分关心这些与center很接近的点网络究竟是预估为0还是预估为1,预估为0自然很好,但是哪怕预估为1,也影响不大)。我们来协同看一下(1-Yxyc)^β和(带标Yxyc)^α 是如何一起发挥作用的。
对于距离实际中心点近的点,Yxyc接近1,例如Yxyc=0.9,若带标Yxyc接近1,是有问题的,它应该被预测为0,因此用(带标Yxyc)^α惩罚一下,使其loss加大,但是(1-Yxyc)^β是减小的,也就是说这个点虽然预测错了,它的出框不一定差,但是也不希望它的loss很大,要抑制一下。
对于距离实际中心点远的点,Yxyc接近0,例如Yxyc=0.1,如果带标Yxyc接近1,肯定不对,因此用(带标Yxyc)^α来惩罚,加大loss,(1-Yxyc)^β则变大,增加loss,如果带标Yxyc接近0,则loss接近0。
我看有的解释说alpha次方限制easy example导致的gradient被easy example dominant的问题,就是说限制loss中的梯度大多被简单样本占据的问题,和focal loss是一致的,beta次方,因为对距离中心点不同的点施加的loss比重不同,比如对远的点,(1-Yxyc)肯定是小了,反之大了,就是说对远的点给了小的权重,对近的点给了大的权重,其实越近的点的Y值是不一样的,只有中心点是正样本,其余都是负样本,其实有处理样本不均衡的意思,在我看来,还是一开始那个解释好一点,距离中心点近的点给一个小的权重,其实是觉得中心点预测点的出框不一定比中心点出框要差,还是要削弱其loss。代码如下:
def gaussian_focal_loss(pred, gaussian_target, alpha=2.0, gamma=4.0):
eps = 1e-12
pos_weights = gaussian_target.eq(1)
neg_weights = (1 - gaussian_target).pow(gamma)
pos_loss = -(pred + eps).log() * (1 - pred).pow(alpha) * pos_weights
neg_loss = -(1 - pred + eps).log() * pred.pow(alpha) * neg_weights
return pos_loss + neg_loss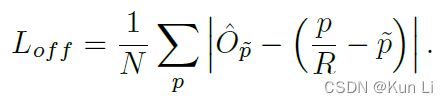
这是中心offset的损失,R是下采样的步长,为4,p是中心点的坐标位置,p是原始图下采样得到的,centernet中的输入尺寸是固定的,一般取512*512,图片可以像yolo一样,等比放缩再padding,保证尺寸大小一致,centernet的计算都是在下采样图上的,例如都是在128*128的特征图上,p是原始下采样的128*128图上的中心点坐标,相应的对原始的标签我们也需要同步转化,但是标签坐标是float型的,即使转化后也是浮点型的,假设计算出来的中心点是(98.97667,2.356666),带标p是前向推理的中心点,比如我们读入图像(640,320),统一处理成(512,512),下采样4倍成(128,128),最终计算loss的采样的图像大小是(128,128),每个预测出来的heatmap中心点,假设我们预测出实际标记的中心点(98.97667,2.356666)对应的点是(98,2),坐标是(x,y),类别是c,则带标Yxyc=1,(p/R-带标p)是可以直接计算的,这一点很重要,带标p是取决于heatmap分支,Op是offset的预测值,这里用l1监督offset。
宽高和offset的监督仅仅在gt bbox中心位置,其余位置全部是忽略区域。这种做法其实很不鲁棒,也就是说bbox性能其实完全靠分类分支,如果分类分支学习的关键点有偏差,那么由于宽高的特殊监督特性,可能会导致由于中心点定位不准而带来宽高不准的情况(特别的如果中心点预测丢失了,那么宽高预测再准也没有用),不过这个offset也不是必须,我同事做文档作为纠正的时候,就没有用offset这个分支对heatmap预测重点进行矫正,效果也不错。
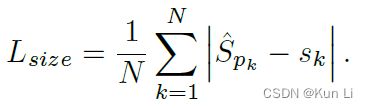
sk是原始图中心点经过下采样计算的得到的对象的wh,带标Spk预测的中心点对应的wh
整体损失如下所示:

论文中λsize=0.1,λoff=1,使用的backbone有3个head,分别产生(bs,80,128,128),(bs,2,128,128),(bs,2,128,129),每个坐标点产生C+4个数据,分别是类别,长段和偏移。
2.3 标签如何制作?
centernet的标签制作核心在于高斯核的中心点图如何生成,首先制作标签有3个,1.center_heatmap_target,2.wh_target,3.offset_target,中心点制作在gaussian_radius和gen_gaussian_target,前者是生成高斯核的半径,这块原始论文是有点问题,它是照抄cornernet,目前在mmdet中我看到已经更正了,gen_gaussian_target是生成半径为r的高斯heatmap为监督的。这里在我上面的材料里面有一个很详细的描述。
def get_targets(self, gt_bboxes, gt_labels, feat_shape, img_shape):
"""Compute regression and classification targets in multiple images.
Args:
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box.
feat_shape (list[int]): feature map shape with value [B, _, H, W]
img_shape (list[int]): image shape in [h, w] format.
Returns:
tuple[dict,float]: The float value is mean avg_factor, the dict has
components below:
- center_heatmap_target (Tensor): targets of center heatmap, \
shape (B, num_classes, H, W).
- wh_target (Tensor): targets of wh predict, shape \
(B, 2, H, W).
- offset_target (Tensor): targets of offset predict, shape \
(B, 2, H, W).
- wh_offset_target_weight (Tensor): weights of wh and offset \
predict, shape (B, 2, H, W).
"""
img_h, img_w = img_shape[:2]
bs, _, feat_h, feat_w = feat_shape
width_ratio = float(feat_w / img_w)
height_ratio = float(feat_h / img_h)
center_heatmap_target = gt_bboxes[-1].new_zeros(
[bs, self.num_classes, feat_h, feat_w])
wh_target = gt_bboxes[-1].new_zeros([bs, 2, feat_h, feat_w])
offset_target = gt_bboxes[-1].new_zeros([bs, 2, feat_h, feat_w])
wh_offset_target_weight = gt_bboxes[-1].new_zeros(
[bs, 2, feat_h, feat_w])
for batch_id in range(bs):
gt_bbox = gt_bboxes[batch_id]
gt_label = gt_labels[batch_id]
center_x = (gt_bbox[:, [0]] + gt_bbox[:, [2]]) * width_ratio / 2
center_y = (gt_bbox[:, [1]] + gt_bbox[:, [3]]) * height_ratio / 2
gt_centers = torch.cat((center_x, center_y), dim=1)
for j, ct in enumerate(gt_centers):
ctx_int, cty_int = ct.int()
ctx, cty = ct
scale_box_h = (gt_bbox[j][3] - gt_bbox[j][1]) * height_ratio
scale_box_w = (gt_bbox[j][2] - gt_bbox[j][0]) * width_ratio
radius = gaussian_radius([scale_box_h, scale_box_w],
min_overlap=0.3)
radius = max(0, int(radius))
ind = gt_label[j]
gen_gaussian_target(center_heatmap_target[batch_id, ind],
[ctx_int, cty_int], radius)
wh_target[batch_id, 0, cty_int, ctx_int] = scale_box_w
wh_target[batch_id, 1, cty_int, ctx_int] = scale_box_h
offset_target[batch_id, 0, cty_int, ctx_int] = ctx - ctx_int
offset_target[batch_id, 1, cty_int, ctx_int] = cty - cty_int
wh_offset_target_weight[batch_id, :, cty_int, ctx_int] = 1
avg_factor = max(1, center_heatmap_target.eq(1).sum())
target_result = dict(
center_heatmap_target=center_heatmap_target,
wh_target=wh_target,
offset_target=offset_target,
wh_offset_target_weight=wh_offset_target_weight)
return target_result, avg_factor2.4 前向推理
论文中强调centernet是不需要nms操作的,假设测试输入是一张图像,默认配置下会先对图像做仿射变换,这一步重点在于将图像尺寸处理成512*512大小后作为网络的输入。执行网络的前向计算将得到3个输出:1、[1,80,128,128]大小的heatmap,2、[1,2,128,128]大小的尺寸预测,3、[1,2,128,128]大小的offset预测。heatmap会经过一个sigmoid函数使得范围为0到1,符合heatmap的定义,接下来对heatmap执行一个最大池化操作,kernel设置为3,stride设置为1,pad设置为1,这一步其实是在做重复框过滤,这也是为什么后续不再需要NMS操作的一个重要原因,毕竟这里3x3大小的kernel加上特征图和输入图像之间的stride=4,相当于输入图像中每12x12大小的区域都不会有重复的中心点,想法非常简单有效!然后再基于heatmap选择top K个得分最高的点(默认K=100),这样就确定了100个置信度最高的预测框的中心点位置了,这一步也会去掉一定的重复框。接下来就要确定预测框的大小了,通过输出的尺寸预测值和offset就可以得到。到目前位置,得到的预测框信息都是在128x128大小的特征图上,因此最后将预测框信息再映射到输入图像上就得到最终的预测结果了,显示预测结果时可以设定一个置信度阈值,高于阈值的才显示。
但是关于这个pooling的trick其实也是有问题的,如果图像中大目标比较多,12x12的感受野可能不够,造成top100集中在几个大物体上也是有可能的,
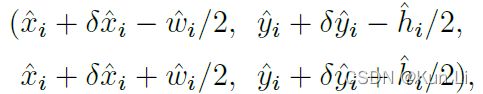
def decode_heatmap(self,
center_heatmap_pred,
wh_pred,
offset_pred,
img_shape,
k=100,
kernel=3):
height, width = center_heatmap_pred.shape[2:]
inp_h, inp_w = img_shape
center_heatmap_pred = get_local_maximum(
center_heatmap_pred, kernel=kernel)
*batch_dets, topk_ys, topk_xs = get_topk_from_heatmap(
center_heatmap_pred, k=k)
batch_scores, batch_index, batch_topk_labels = batch_dets
wh = transpose_and_gather_feat(wh_pred, batch_index)
offset = transpose_and_gather_feat(offset_pred, batch_index)
topk_xs = topk_xs + offset[..., 0]
topk_ys = topk_ys + offset[..., 1]
tl_x = (topk_xs - wh[..., 0] / 2) * (inp_w / width)
tl_y = (topk_ys - wh[..., 1] / 2) * (inp_h / height)
br_x = (topk_xs + wh[..., 0] / 2) * (inp_w / width)
br_y = (topk_ys + wh[..., 1] / 2) * (inp_h / height)
batch_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], dim=2)
batch_bboxes = torch.cat((batch_bboxes, batch_scores[..., None]),
dim=-1)
return batch_bboxes, batch_topk_labels2.5 核心疑问?
看完CenterNet算法,可能会有个疑问,那就是当不同目标框的中心点重合时,这种情况下怎么预测?这个问题和FCOS算法中遇到的问题类似,在FCOS中当多个目标框区域重叠时,重叠部分的点的监督信息就有多个,但模型训练时监督信息肯定只能有一个,因为这种情况占比23%,影响较大,因此通过引入FPN网络解决。CenterNet中的冲突是目标框的中心点重合(基于输出特征层计算的中心点),作者从COCO数据集的统计信息来看,这种重合框的比例非常少,不到0.1%,基本上不会对训练稳定产生太大影响,因此没有针对这个进行解决。这个正负样本分配的问题是个重要的线索,熟悉 anchor-free 算法的读者应该知道这类算法性能优异的核心就在于 bbox 正负样本分配,不同的 anchor-free 算法主要区别就在于此,或者说各类 anchor-free 算法最大创新点就在于此,读者在学习 anchor-free 算法时候要特别注意理解其 bbox 正负样本分配规则。

整体来看,centernet就是对中心点进行分类,然后回归wh,offset的方法,很简洁,如果中心点能够很好的预测出来,基本是很准的,我在篡改文本检测的稽查区域中用过centernet,通用文本检测中也用过centernet,确实是又快又准,主要是整个方法非常的完整,不需要做过多的前后处理,核心来看,感觉和east比较相近,其实点就是anchor,关键就是label制作,核心的就是高斯核半径确定生成,然后用loss对中心点分类进行监督,这里对中心点其实还是采用了像素级别的分类来做,wh,offset做回归,前向时用了pooling的小trick。