Redis-RDB-AOF持久化篇
以往的文章:
一、Redis-数据类型与其应用场景
二、Redis-通用指令篇
文章目录
- Redis-RDB-AOF持久化篇
-
- Redis简介
- 什么是持久化?
- Redis 的持久化方式 RDB 和 AOF
-
- RDB快照
-
- save 命令
- bgsave 命令
- AOF(Append Only File) 过程记录
-
- AOF写过程
- AOF 重写
- 在这里插入图片描述
-
- RDB 对比 AOF
- RDB 和 AOF 选择
Redis-RDB-AOF持久化篇
Redis简介
Redis是C语言开发的一个高性能键值对(key -value) 内存数据库,可以用作数据库,缓存和消息中间件等。
特点
-
作为内存数据库,它的性能非常优秀,数据存储在内存当中,读写速度非常快,支持并发10W QPS(每秒查询次数),单进程单线程,是线程安全的,采用IO多路复用机制。
-
丰富的数据类型,支持字符串,散列,列表,集合,有序集合等,支持数据持久化。可以将内存中数据保存在磁盘中,重启时加载。
-
主从复制,哨兵,高可用,可用作分布式锁。可以作为消息中间件使用,支持发布订阅。
什么是持久化?
举个例子:
有没有试过在写文件(如写论文时用的Word)的时候,突然遇到断电或者是软件崩溃之类的情况,但是我们在遇到文件崩溃的时候,软件往往有一个自动备份的机制,以致于我们在遇到突然断电或者软件崩溃,来不及保存的情况下提供的一个恢复的可能。

那么所谓的自动备份,自动恢复是怎么回事呢?其实就是将内存中的数据将硬盘中的数据做了一个关联,在一段时间以后,将内存中的数据保存到了硬盘上,等到万一数据丢失了,它会把硬盘的数据再读回到内存中,把数据恢复了,用这种形式来对数据起到一个保护的作用。
Redis作为一个内存数据库,数据如果丢失,会很麻烦,显然也需要这样一个机制来保存数据,需要经常同步内存中的数据到硬盘保证持久化。

===》所以:
持久化是将程序数据在持久状态和瞬时状态间转换的机制。通俗的讲,就是瞬时数据(比如内存中的数据,是不能永久保存的)持久化为持久数据(比如持久化至数据库中,能够长久保存)。
如:
应用层:如果关闭(shutdown)你的应用然后重新启动则先前的数据依然存在。
系统层:如果关闭(shutdown)你的系统(电脑)然后重新启动则先前的数据依然存在。
可见:持久化保存的是数据
Redis 的持久化方式 RDB 和 AOF
RDB快照
快照: 指的是在规定的时间间隔内将内存中的数据集写入到磁盘中,通俗地说就是像照相机一样,快门一闪,就可以将某一历史时刻的景象留在了照片上,不同的是拍照的对象是数据,而不是其他画面。所以我们可以快速地根据快照来查找到某一历史时刻的数据信息。
利用快照来对当前数据状态结果进行保存,格式简单,关注点在数据。但是快照时间点后面的数据都会丢失。
在Redis中我们可以每隔1分钟保存一次快照,这样就算遇到断电或者其他突发情况,我们损失的一小部分数据影响也不大。
RDB提供了两种指令来生成RDB文件,每执行一遍,就保存一遍快照
save 命令
因为 Redis 是单线程的,假定有几个客户端分别发送几条指令到服务器,实际上这几个指令发送过来是会有一定的执行顺序的,假如现在有大量执行指令(非save)已经在这个任务序列里面,等到某客户端发送了一个 save 指令过来,开始执行RDB,一旦时间过长,就会阻塞 Redis 服务器进程,且 Redis 服务器在阻塞过程中,不能处理任何其他命令,直到RDB文件创建过程完毕为止,才可以往下执行。这样子就影响了Redis的正常使用,所以线上环境不建议使用,有可能造成长时间阻塞,效率降低。
save // 返回 OK
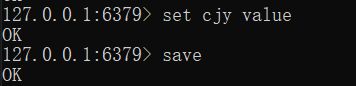
save 执行的日志信息:
[4928] 09 Jun 18:04:45.165 * DB saved on disk
bgsave 命令
解决前面的单线程执行方式造成阻塞问题,引入了bgsave这个命令,在执行这个命令的时候,服务器首先返回:Background saving started再在空闲时间调用fork函数派生出一个子进程,然后由子进程负责创建 RDB 文件,父进程继续处理其他命令请求,子进程创建完毕后,会在日志中返回这样一个信息Background saving terminated with success
bgsave // 返回 Background saving started
![]()
bgsave 执行的日志信息:
[4928] 09 Jun 17:11:42.834 * Background saving started by pid 9480 开始
[4928] 09 Jun 17:11:43.078 # fork operation complete
[4928] 09 Jun 17:11:43.080 * Background saving terminated with success 结束
注意:bgsave命令是针对save阻塞这个问题做的优化,。Redis内部所有涉及到RDB操作都采用bgsave方式进行,基本上可以不用save了![]()
执行成功后生成的文件:

打开文件,在RDB中保存的形式为二进制,大概就是些数据头+Redis版本号+数据内容

rdb文件数据:
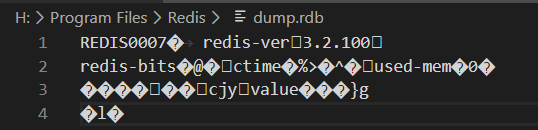
命令执行完成后会在下面redis.windows.conf文件(linux为redis.conf)配置的目录下生成,默认文件名dump.rdb,我们可以根据需求来修改配置
配置文件:
# 后台存储过程中如果出现错误,是否停止报错操作,默认开启—— bgsave
stop-writes-on-bgsave-error yes
# 设置是否压缩数据,默认为YES,采用 LZF 压缩
# 不压缩可以节省时间,但存储的文件会更大
rdbcompression yes
# 是否进行RDN文件格式校验,在文件读写过程都会进行
# 默认开启,如果不开启,可以节约读写过程时间,但是有数据损坏风险
rdbchecksum yes
# The filename where to dump the DB
# 设置本地数据库文件名,默认值为dump.rdb,通常设置成 dump-端口号.rdb
dbfilename dump.rdb
# The DB will be written inside this directory, with the filename specified
# 设置存储.rdb文件的路径,通常设置到存储空间较大的目录中
dir ./
RDB启动方式:
-
手工(管理员手工执行命令备份)==》save 命令 | bgsave 命令
-
自动执行(Redis服务器执行命令备份)==》save second changes
在满足的second时间范围内key变化达到changes数量,即执行一次持久化,需要至少changes数量足够才执行,否则重新计时,如设置10秒内至少5个key改变执行,但是10秒过去了只有2个key改变,则重新计时,在conf文件里进行新增配置规则
save second changes可以配置多个规则,只要满足其中一个规则就执行
注意事项:
通过配置save second changes 执行的在后台实际是bgsave操作
RDB三种方式对比:
| 方式 | save命令 | bgsave命令 | save配置==bgsave命令 |
|---|---|---|---|
| 读写 | 同步(阻塞) | 异步(新进程) | 异步 |
| 阻塞客户端 | 是(单进程) | 否(新进程) | 否 |
| 额外消耗内存 | 否(没有新进程) | 是(新进程) | 是 |
| 启动新进程 | 否 | 是 | 是 |
RDB优点,在上面介绍过一遍了,再做一次总结
- RDB是一个紧凑压缩的二进制文件,存储效率较高
- RBD内部存储的是Redis在某个时间点的快照,非常适合于数据备份,全量复制
- RDB数据恢复速度比AOF快
- 服务器可以每几小时执行一次bgsave备份,并将RDB文件复制到远程机器中,做容灾。
RDB缺点,在上面介绍过一遍了,再做一次总结
- RDB快照方式执行无法做到实时持久化,服务器突然挂了的话,具有较大数据丢失的风险,快照时间点后的数据是没有的
- bgsave执行每次都会调用fork函数创建新的子进程做操作,会牺牲部分性能
- RDB文件格式不统一:
数据头+Redis版本号+数据内容,可能会出现不同版本数据格式不兼容的情况 - 每次读写的都是全部数据,当数据量巨大时,IO性能效率较低
AOF(Append Only File) 过程记录
过程:
与RDB持久化通过保存数据库中的键值对来记录数据库状态不同,AOF持久化是通过保存Redis所执行的写命令来记录数据库状态的。如:在PS或者其他工具用的比较多的——“撤回” 功能,在PS历史记录就有很好的体现,每执行一个操作,都将它的命令给记录下来,当我们在操作失误时,可以调出历史记录去选择恢复到某一步操作的位置
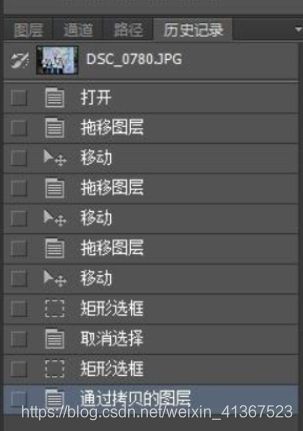
在Redis中就是将命令操作步骤记录下来,当需要恢复数据的时候,将命令重新执行一遍就可以了。这种方案可以解决数据持久化的实时性(上面RDB数据快照时间点后的数据可能丢失),在备份的时候可以没必要每次都进行全部数据备份,只追加记录部分数据,并将记录的数据变为记录数据命令的过程。
AOF写过程
当AOF功能打开时,服务器在执行命令完成之后,服务器没有直接记录到AOF文件,而是将被执行的命令写到一个临时存储的区域——AOF_BUFF缓冲区末尾,然后再将命令在一定条件下同步到AOF文件中。
AOF同步条件的三种策略(appendfsync):
- everysec(系统控制)
AOF_FSYNC_NO :系统来控制同步到AOF文件的周期,根据空闲情况触发同步,整体过程不可控,系统挂了,损失的数据就随缘了。。
- everysec(每秒) Redis默认使用
AOF_FSYNC_EVERYSEC :每一秒钟将缓冲区命令同步保存一次到AOF文件中,数据准确还是比较高的,且性能会较好。系统突然挂掉,同步损失的就只有那一秒的数据,比较推荐用
- always(每次)
AOF_FSYNC_ALWAYS :每执行一个命令同步一次到AOF文件,0误差,但是性能差(同时来个十几万条数据,IO消耗大量资源,大概率崩溃)
文件配置路径:redis.windows.conf | redis.conf
注意:如果RDB和AOF同时存在,那么redis会以AOF为准,因为在通常情况下AOF文件保存的数据集要比RDB文件完整
# 默认不开启,AOF和RDB持久化可以同时启用,实际场景得根据自己需求了
#appendonly yes 的时候优先级比RDB高
appendonly no
# The name of the append only file (default: "appendonly.aof")
# 默认名:appendonly.aof 可加上端口号:appendonly-端口号.aof
appendfilename "appendonly.aof"
# If unsure, use "everysec".
# 默认使用 everysec
# 下面是三种同步策略
# appendfsync always
appendfsync everysec
# appendfsync no
# 文件保存路径
dir
AOF 重写
随着命令不断写入AOF,文件会越来越大,有可能会记录很多无效或重复的数据,或者是后面的把前面覆盖的数据,可以将数据进行整理合并。为了解决这个问题,Redis引入了AOF重写机制压缩文件体积,AOF文件重写是将redis进程内的数据转化为写命令同步到新AOF文件的过程,简单滴就是说对用一个数据的若干条命令执行结果转化成最终结果对应的指令进行记录。
总之重写干的就是优化AOF文件的活,减小AOF文件的体积
AOF重写作用
- 降低磁盘占用率,提高磁盘利用率
- 提高持久化效率,降低持久化写时间,提高IO性能
- 降低数据恢复用时,提高恢复效率
- 例:
可以合并的指令:
lpush list a
lpush list b
lpush list c
可以合并成为 lpush list a b c ,执行1次总比执行3次效率高
--------------------------------------------------------------------------
无效的指令:
del keya
hdel keyb
srem keyc
可以直接利用内存中的数据来直接生成命令,内存中没有的数据就不需要生成,这就避免了先添加-再删除两步
--------------------------------------------------------------------------
后面的指令已经覆盖前面的:
set key a
set key b
可以直接利用内存中的数据来直接生成一条添加 b 命令,添加内存本来的 b 数据,这就避免了先添加a-再修改为 b 两步
--------------------------------------------------------------------------
进程中已经超时的数据:
setex key seconds values
如果数据超时了,即是此数据已被删除,无需再写到文件了,参考无效指令
--------------------------------------------------------------------------

为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序在处理list、 hash、set、sorted set 等类型,会先检查键所包含的元素数 量,如果元素的数量超过了redis.h的REDIS_AOF_REWRITE_ITEMS_PER_CMD = 64常量的值,那么重写程序将使用多条命令来记录键的值,而不单单使用一条命令。
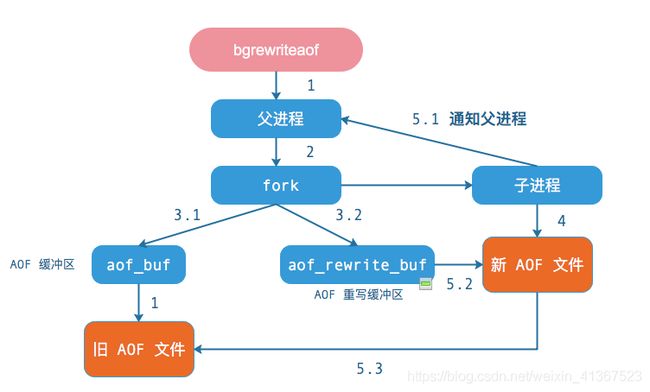
AOF 重写方式
- 手动重写-后台自动重写

bgrewriteaof // 重写
流程类似 RDB 的: bgsave 命令
AOF文件内容:
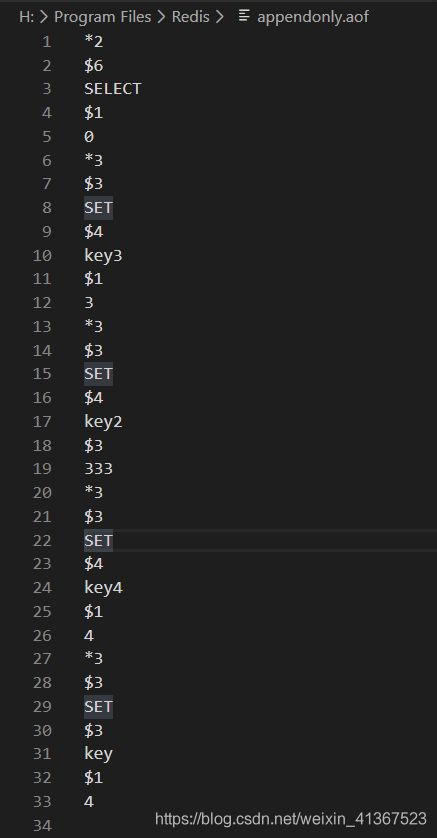
执行日志:
[4928] 09 Jun 21:28:26.356 * Background append only file rewriting started by pid 17824
[4928] 09 Jun 21:28:26.533 * AOF rewrite child asks to stop sending diffs.
[4928] 09 Jun 21:28:26.633 # fork operation complete
[4928] 09 Jun 21:28:26.635 * Background AOF rewrite terminated with success
[4928] 09 Jun 21:28:26.637 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB)
[4928] 09 Jun 21:28:26.637 * Background AOF rewrite finished successfully
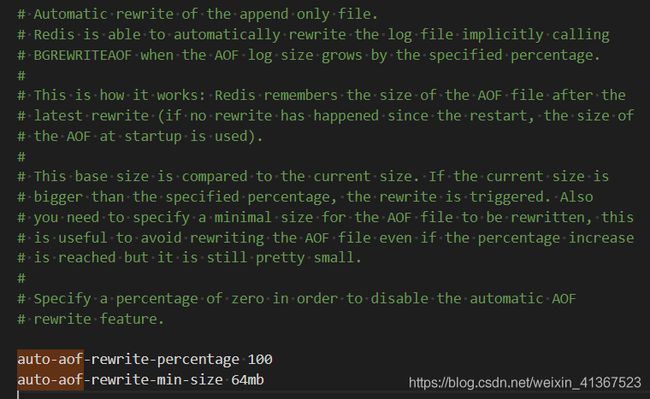
- 配置自动重写
# 配置文件:redis.conf | redis.windows.conf
# 自动触发的条件配置
//这两个配置项的意思是,在aof文件体量超过64mb,且比上次重写后的体量增加了100%时自动触发重写。我们可以修改这些参数达到自己的实际要求
auto-aof-rewrite-percentage 100 // 自动重写的百分比增长率,百分比达到100%才重写
auto-aof-rewrite-min-size 64mb //触发重写的最小容量,不同版本默认值不一样,缓冲区到64M才进行重写
# 自动触发对比参数
# 基础大小
aof_base_size
# 当前缓冲区容量大小
aof_current_size
触发重写所需条件;
第一种:当前容量超出设置的最小容量
aof_current_size > auto-aof-rewrite-min-size
第二种:基本大小与当前大小进行比较,如果当前大小大于指定的百分比,将触发重写
(aof_current_size - aof_base_size) / aof_base_size >= auto-aof-rewrite-percentage
看图注释:
AOF 工作流程
aways(每次都写入)非重写
everysec(每秒够后才写入)非重写
everysec(每秒够后才写入)重写
RDB 对比 AOF
| 持久化方式 | RDB | AOF |
|---|---|---|
| 占用存储空间 | 小(数据级:可配置压缩) | 大(指令级:可配置重写) |
| 存储速度 | 慢(每次都得全部存一次) | 快(可追加) |
| 恢复速度 | 快(二进制存储,直接载入内存) | 慢(要重新执行命令,文件大) |
| 数据安全性 | 会丢失数据(丢失快照时间点后的数据) | 依据策略决定 (可能丢失一秒的(每秒),也可能未知(系统调度)) |
| 资源消耗 | 高/重量级(save单进程阻塞/bgsave子进程) | 低/轻量级 (不阻塞) |
| 启动优先级 | 低 | 高(同时开启是AOF高) |
| 备份选择 | 全量备份 | 增量备份 |
RDB 和 AOF 选择
每种都有利有弊,看实际需求。。。。。
对数据非常敏感,不能承受数分钟以内数据丢失——AOF
能承受数分钟以内数据丢失,追求大数据恢复速度——RDB
双保险:综合使用AOF和RDB两种持久化机制,使用AOF来保证数据不丢失,作为数据恢复的第一选择;用RDB做不同程度的冷备,当AOF备份文件丢失或损坏不可用时,可以使用RDB快照文件快速的恢复数据——RDB+AOF