旷视YOLOX论文思想理解
目录
- 引语
- 一、训练配置
- 二、Decoupled Head
- 三、数据增强:Mosaic和Mix-up
- 四、Anchor-free
- 五、Multi positives
- 六、OTA(Optimal Transport Assignment)
- 七、代码测试
- 八、参考文献
引语
YOLOX 的设计,在大方向上主要遵循以下几个原则:
- 所有组件全平台可部署
- 避免过拟合 COCO,在保持超参规整的前提下,适度调参
- 不做或少做稳定涨 点但缺乏新意的工作(更大模型,更多的数据)所以大家可以看到,首发的 YOLOX 没有 deformable conv ,没有用额外数据做 pretrain,没有 momentum=0.937…
——引自YOLOX原团队
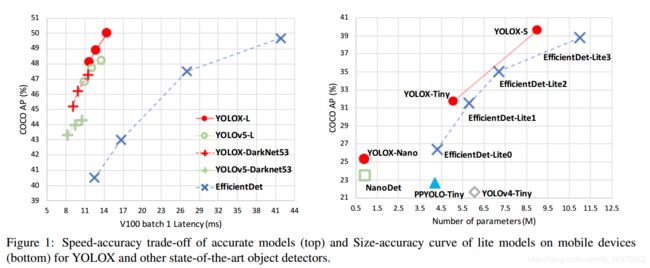
一、训练配置
1.300epoch的训练长度,其中,前5个epoch使用warmup学习率策略,;
2.优化器使用标配的SGD;
学习率: L r ∗ B a t c h s i z e 64 Lr * \frac{Batchsize}{\ 64} Lr∗ 64Batchsize,其中初始学习率 L r = 0.01 Lr= 0.01 Lr=0.01。使用余弦学习率策略;
3.batch size为128,使用8块GPU……当然,作者也说了,单卡GPU和64batch size也是可以work,就是训练得挺久~
4.多尺度训练:448-832,不再是以往的320-608了。这应该是追求large input size的涨点。
5.Backbone就是v3所使用的DarkNet-53。
6.预测部分加入了IoU-aware分支,这一点应该是和PP-YOLO是对齐的
7.损失函数:obj分支和cls分支还是使用BCE,reg分支则使用IoU loss;
8.使用EMA训练技巧(这个很好用,可以加快模型的收敛速度);
数据增强仅使用RandomHorizontalFlip、ColorJitter以及多尺度训练,不使用RandomResizedCrop,作者认为RandomResizedCrop和Mosaic有点重合了。由于后续会上Mosaic Augmentation,所以这里暂时先不要了。
通过上述的训练配置,YOLOX的baseline:YOLOv3在COCO val上的性能达到了38.5AP。
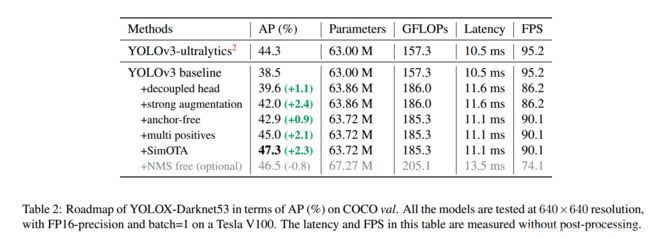
二、Decoupled Head
第一个改进就是YOLOv3的head部分。一直以来,YOLO工作都是仅使用一个branch就同时完成obj、cls以及reg三部分的预测。而我们所熟知的RetinaNet则是使用两个并行分支去分别做cls和reg的预测。YOLOX作者认为仅使用一个分支是不合适的,于是,就把原先的Coupled head改成类似于RetinaNet的那种Decoupled head,如下图所示:

完成这个改进后,baseline的性能再一次提升,不过速度略微下降,但完全在可接受的范围内。

后续的YOLOX会改成end-to-end的形式,也就是不适用NMS操作,作者发现原先的Coupled head会掉点严重,而采用RetinaNet的那种Decoupled head就会缓解很多,同时,性能还略有提升。
其实,这一点是很好理解的,毕竟cls的学习显然和reg不一样,仅使用一个branch来完成两个类型完全不同的目标,确实有点难度。
上图的下半部分没有了anchor,也就是anchor box被去掉了,变成了anchor box free工作。
三、数据增强:Mosaic和Mix-up
YOLOX继续给baseline增加了Mosaic和Mix-up两个数据增强手段。在训练的最后15个epoch,这两个数据增强会被关闭掉,而在这之前,Mosaic和Mix-up是都开着的,如果从头到尾都开这两个数据增强,性能反而提升不大:Mosaic+Mixup 生成的训练图片,远远脱离自然图片的真实分布,并且 Mosaic 大量的 crop 操作会带来很多不准确的标注框。
加入了这两个strong data augmentation后,baseline的性能直接涨到了42.0AP:
由于加入了这么强的两个数据增强后,YOLOX从这里开始就不再需要pre-trained mode了,而是直接train from scratch。
四、Anchor-free
YOLOX作者去掉了anchor box,和FCOS一样,每个grid都只预测一个目标。
去掉了anchor box,也就是去掉了size的先验,故而FPN肯定会出现问题:如何做尺度分配?对于这一问题,YOLOX直接使用FCOS的路子,预先设定一个尺寸范围,根绝每个gt的size来判断应该分配到哪个尺度上去。这个预先设定的size范围,论文里没有给出,就需要我们自己去看源码了,但这个不是实质问题,不影响后续的阅读。
对于一个给定的gt边界框,首先根据它的size确定所匹配的尺度,然后就和YOLOv3一样了,计算它在这个尺度上的中心点位置,计算中心点偏差 tx、ty,至于宽高 w、h,就直接作为回归目标(注意,这里要把宽高做归一化,这是yolo基操)。
Anchor Free 的好处是全方位的:
1). Anchor Based 检测器为了追求最优性能通常会需要对anchor box 进行聚类分析,这无形间增加了算法工程师的时间成本;
2). Anchor 增加了检测头的复杂度以及生成结果的数量,将大量检测结果从NPU搬运到CPU上对于某些边缘设备是无法容忍的。当然还有;
3). Anchor Free 的解码代码逻辑更简单,可读性更高。
完成了anchor-free化的操作后,性能略微提升:
可见,对于YOLO来说,anchor box不是必要的,去掉anchor box性能依旧很好,而且由于预测层的参数少了,推理速度上来了。
anchor-free再怎么anchor-free,它的本质还是anchor-based,只不过,一个anchor处没再放k个anchor box。真正的anchor free,在笔者看来,应该是完全不要spatial维度,或者说,完全不需要再spatial维度上去做遍历(俗称查网格)找目标。所以,相较于anchor-free,笔者更喜欢用更加提切的、误导性更小的anchor box free。
五、Multi positives
在完成了anchor-free化的改进后,我们会发现一个问题,那就是一个gt框只有一个正样本,也就是one-to-one,这个问题所带来的最大阻碍就是训练时间会很长,同时收敛速度很慢。为了缓解这一问题,YOLOX作者便自然想到可以增加正样本的数量,使用one-to-many策略。
很简单,之前只考虑中心点所在的网格,这会改成以中心点所在的网格的3x3邻域,都作为正样本,直观上来看,正样本数量增加至9倍。每个grid都去学到目标中心点的偏移量和宽高,此时,显然这个中心点偏移量不再是01了,这一点细节的变化需要留意一下。
加入更多的positives后,性能提升显著:
六、OTA(Optimal Transport Assignment)
OTA概念来自《OTA: Optimal Transport Assignment for Object Detection》。简而言之是基于Optimal Transport问题提出了一个新的label assign方法,来提升FCOS这种基于point的anchor-free工作的性能。
并且,使用了OTA策略后,就完全不需要类似于FCOS那种基于size的尺度分配策略,这一点大大减少了数据预处理部分的人工先验,还是挺舒服的~
将OTA加入到YOLOX中,涨点也是很明显的:
七、代码测试
代码链接:
https://github.com/Megvii-BaseDetection/YOLOX
测试环境:

切换到对应目录文件夹下:
cd /content/drive/MyDrive/YOLOX
安装规定的各类包:
pip install -r requirements.txt
执行对应文件夹下的demo.py文件:
!python tools/demo.py image -n yolox-nano -c /content/drive/MyDrive/YOLOX/weights/yolox_nano.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device gpu
执行结果:

原图:
检测结果(小车多个框可能是因为NMS没设好阈值的问题):
八、参考文献
https://www.zhihu.com/question/473350307
https://zhuanlan.zhihu.com/p/391396921