深度学习——分类网络的总结(持续更新ing~)
-
-
- 一、AlexNet(2012年)
- 二、ZFNet(2013年)
- 三、NIN(2014年)
- 四、VGGNet(2014年)
- 五、GoogLeNet系列(2014年)
-
- 5.1 GooLeNet(2014年)
- 5.2 Inception v2
- 5.3 Inception v3
- 六、ResNet系列(2015年)
- 七、DenseNet(2017年)
- 八、轻量级网络系列
-
- 8.1 MobileNet & MobileNet v2
-
- 8.1.1 MobileNet
- 8.1.2 MobileNet v2
- 8.2 ShuffleNet & ShuffleNet v2
-
- 8.1.1 ShuffleNet
- 8.1.2 ShuffleNet v2
-
为了让学习思路比较清晰,我们把近期网络篇学习的大纲放在下面(实际上也是激励我们…认真学习不能放弃呜呜呜)!后面会将持续更新的网络篇的博客地址放在下面,还请各位大大们持续关注和支持!!!蟹蟹大家!给你们比心心~

说到对深度学习分类网络的总结,我们不妨先来回顾一下这些网络都做了什么优秀的事情(因为是总结,可能不够全面,想要详细了解的小伙伴可以看我们博客链接的详细介绍)。
一、AlexNet(2012年)
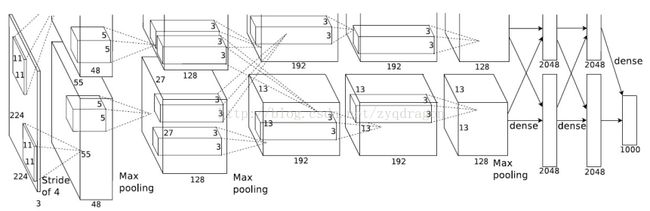
成绩: 2012年ILSVRC的比赛冠军;
网络结构: 采用了8层的神经网络,其中包含5个卷积层(其中有3个卷积层后连接了最大池化层,激活函数选用的Relu,并且做了标准化),3个全连接层(2048)和softmax层(1000);卷积核大小:11x11、5x5、3x3;
AlexNet=(conv+relu+maxpooling)×3+(conv+relu)×2+fc×2+softmax
训练过程: 两台GPU串联提高运行速度;
防止过拟合: 一是数据增强:将原始图像227x227x3进行水平翻转,随机裁剪为224x224x3的输入图像,并做了PCA的主成分分析;二是用了Dropout,随机忽略一部分的神经元,训练时keep_prob为0.5,测试时keep_prob为1;
博客的链接:
深度学习网络篇——AlexNet
深度学习网络篇——AlexNet在MNIST的代码实现
二、ZFNet(2013年)

成绩: 2013年ILSVRC的比赛冠军;
ZFNet的目的:可视化和理解卷积神经网络! 所以在网络中引入了反池化和反卷积,可视化过程为:输入图片-> 卷积-> Relu-> 最大池化->得到结果特征图-> 反池化-> Relu-> 反卷积。
网络结构: 网络结构与AlexNet的网络结构基本相同,只是把第一层卷积的卷积核大小替换为7x7,把全连接层的神经元个数增加到4096;卷积核大小:7x7、5x5、3x3;
ZFNet=(conv+relu+maxpooling)×2+(conv+relu)×3+fc×2+softmax
训练过程: 单GPU的密集运算;
博客的链接:
深度学习网络篇——ZFNet(Part1 从AlexNet到ZFNet)
深度学习网络篇——ZFNet(Part2 ZFNet的训练细节)
深度学习网络篇——ZFNet(Part3 ZFNet的实验环节)
三、NIN(2014年)

网络结构: 一系列mlpconv层(mlp:多层感知机)的堆叠,最后端接一个GAP层(全局平均池化层)和分类层;NIN每层包含三个mlpconv层,每个mlpconv层包含一个三层的感知器,并且都加上了最大池化层;除了最后一个mlpconv层之外,前面的所有mlpconv层都加上了dropout;引入了1x1的卷积(在GoogLeNet中效果更好),实现特征图的跨通道聚合;
训练过程: 手动初始化权重以及学习率,使用128的batch size进行训练;直到训练集上的准确率停止改善,然后学习率以0.1的权重进行衰减,再继续训练,重复直到学习率衰减到初始值的1%;
网络的创新点: 一是MLPconv;二是全局平均池化;
博客的链接:
深度学习网络篇——NIN(Network in Network)
四、VGGNet(2014年)
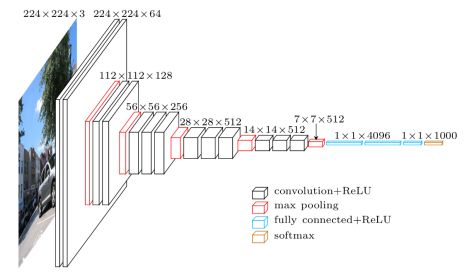
网络结构: 效果较好的是VGG16和VGG19,VGG16是13个卷积层+2个全连接层+softmax层,VGG19是16个卷积层+2个全连接层+softmax层,使用了小卷积核提取特征,卷积核大小:3x3;
训练过程: 训练的大体过程通过小批量图像的(带动量的)梯度下降进行优化多项式的逻辑回归目标函数进行的;此外,在训练图像尺寸方面也做了文章,一种是固定训练图像尺寸S,两一种是多尺度训练来设定S(VGGNet中Smin=256,Smax=512);
测试过程: 首先论证了测试图像尺寸Q和训练尺寸S不必相等,将全连接层转换卷积层(第一个全连接层转为7x7的卷积层,后两个转为1x1的卷积层);
博客的链接:
深度学习网络篇——VGGNet(Part1 网络结构&训练环节)
深度学习网络篇——VGGNet(Part2 分类测试&总结)
五、GoogLeNet系列(2014年)
5.1 GooLeNet(2014年)
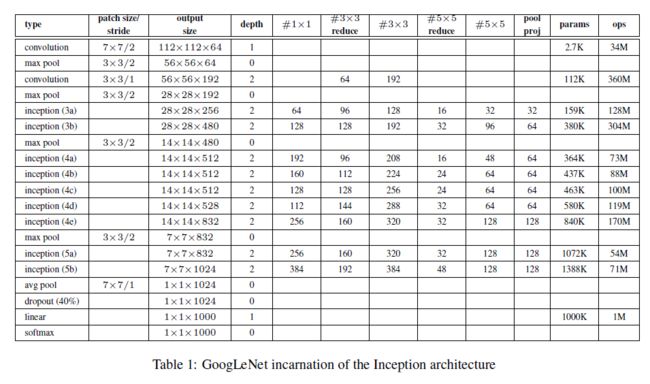
成绩: 2014年ILSVRC的比赛冠军;
网络结构: 一种结合了稀疏性和密集计算的网络结构(Inception),巧妙地使用了1ⅹ1卷积来实现数据降维;卷积核大小:5x5,3x3,1x1;
训练过程: 单个CPU上训练的GoogLeNet;训练过程使用异步随机梯度下降,动量参数为0.9[17],固定的学习率计划(每8次遍历下降学习率4%);各种尺寸的图像块的采样,它的尺寸均匀分布在图像区域的8%——100%之间,方向角限制为[3/4, 4/3];在训练阶段引入了辅助分类器;
5.2 Inception v2
Inception v2讨论的主要内容是Batch Normalization。 总体来说,BN有许多优点,比如说增大学习率,可以移除Dropout,减小L2正则化参数等等(对公式推导感兴趣的小伙伴可以去看博客和原论文);
5.3 Inception v3
Inception v3讨论的主要内容是有效的利用计算机的资源来扩大卷积网络。 更好更快的优化网络可以做很多尝试,举例:降维处理,分解卷积核;有效缩减特征图网络尺寸;讨论了辅助分类器的作用;对比其他模型论证了Inception的优越性;
其他工作: 提出了可以有效扩展卷积网络的一般原则和优化思想(总体设计原则,共4条,具体细节参见博客和原论文)
博客的链接:
深度学习网络篇——GoogLeNet
深度学习网络篇——Inception v2
深度学习网络篇——Inception v3
六、ResNet系列(2015年)
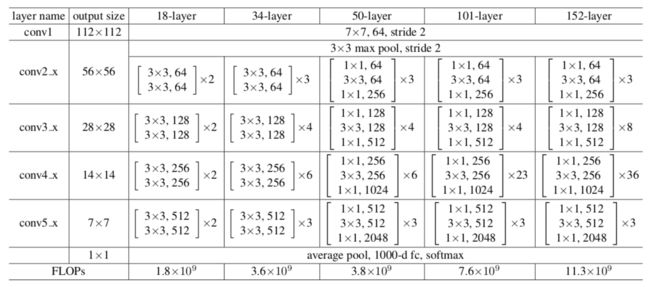
成绩: 2015年ILSVRC的比赛冠军;
网络结构: 提出了残差模块(Residual module)来帮助网络实现恒等映射(Identity mapping),改变了前向和后向信息传递的方式从而很大程度上促进了网络的优化;此外,还利用了Inception v3提出的四个准则对残差模块进行了优化,加入了1x1的卷积核,得到了成为bottleneck的残差模块形式;ResNet网络最深达到了152层,相比于之前的网络已经进步很多了;
ResNet系列: ResNet不是单一的网络,它有一群演变的变形和发展,例如ResNeXt,Inception-ResNet等等,感兴趣的伙伴们可以参见我们的博客和原论文;
博客的链接:
深度学习网络篇——ResNet
七、DenseNet(2017年)

网络结构: 简单来说,DenseNet中的dense block中每一层的输入都是来自前面所有层的输出,也就是说每一层输出的feature map都会作为后面的层的输入;针对DenseNet中参数太多,论文提出了瓶颈层(Bottleneck layers,在每个dense block中33的conv(卷积)层前面引入11的conv层)和压缩(compression,引入一个参数m,提高模型的紧密性)的想法;将卷积过程中采用的三个连续函数——BN->ReLU->Conv(3*3)成为复合函数(Composite function);
博客的链接:
深度学习网络篇——DensesNet
八、轻量级网络系列
8.1 MobileNet & MobileNet v2
8.1.1 MobileNet

轻量化方法: 改变了传统卷积结构; 将卷积分为深度卷积(Depthwise Convolution,即DW)和点态卷积(Pointwise Convolution,即1x1);
MobileNet = [深度卷积3x3+BN+Relu] + [点态卷积1x1+BN+Relu]
网络超参: 宽度因子(Width Multiplier: Thinner Models,将原输入通道M压缩为 α M αM αM,将原输出通道N压缩为 α N αN αN) 和分辨率因子(Resolution Multiplier: Reduced representation,将原输入图像的大小压缩为 ρ D F ∗ ρ D F ρDF∗ρDF ρDF∗ρDF)
8.1.2 MobileNet v2
轻量化方法: 是MobileNet的升级版,将MobileNet的思想应用在了Shortcut connection上,实际上就是对残差结构的轻量化(具体细节参见博客和原论文);
8.2 ShuffleNet & ShuffleNet v2
8.1.1 ShuffleNet

轻量化方法: 通道混洗(channel shuffle operation)和点态卷积群(pointwise group convolution,GConv);通道混洗是让不同组的卷积进行“通信”;点态卷积群是将1x1的卷积做分组操作,因为作者认为1x1的卷积操作的计算量不可忽视,在大多数情况下建议选取g=3的分组;
网络超参: 通道数应用比例因子s,记作ShuffleNet sx,可以得出结论:更宽的通道对于小网络尤其重要;
8.1.2 ShuffleNet v2

轻量化方法: 是ShuffleNet的升级版,弃用了1x1的点态卷积群,重新使用1x1的点态卷积;使用了通道级联(Concat)而不是线性相加(Add);提出了通道分片(Channel Split),将输入的通道分成了两个部分,一部分向下直接传递,另一部分做向后的卷积运算;通道混洗的位置了做了调整,放在了Concat的后面;
其他工作: 论证了评判一个网络性能的标准——准确率(accuracy)、FLOPs、 MAC(memory access cost);提出了两个基本原则和四个应用指南(详情参见博客和原论文)
博客的链接:
轻量级深度学习网络——MobileNet & MobileNet v2
轻量级深度学习网络——ShuffleNet & ShuffleNet v2
深度学习分类任务是入门级别,也是重要的基础任务。再放上一张大佬的图镇楼。
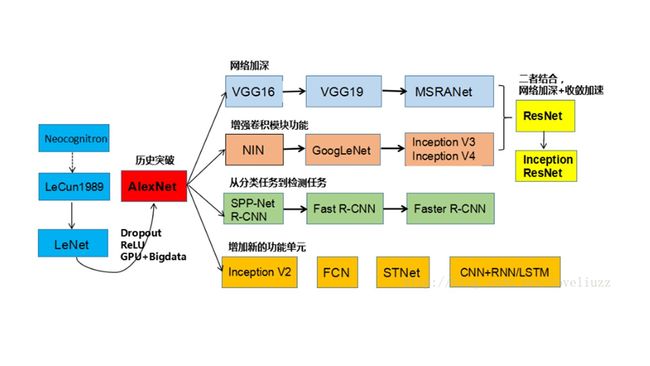
通过这张图我们也可以看清楚分类网络的发展脉络。
----->从AlexNet的历史突破开始,深度学习就走向了热门;
----->为了解释Alexnet为什么成功,所以有了ZFNet进行解释和可视化;
----->为了让网络层数加深,所以VGGNet使用了小卷积核;
----->为了让卷积模块有更强的功能,所以GoogLeNet系列的网络充分发挥了1x1卷积的功能;
----->为了解决网络深度更深,性能更好,就是要把过去所有优秀的经验总结起来,并且提出了残差结构,就有了ResNet系列网络;
----->为了让好的网络可以实际应用落地生产,就有了轻量化网络的需求,MobileNet和ShuffleNet也算是轻量代表作了;
----->分类再往外扩展就是检测任务了,这也是我们博客接下来要分享的内容。
2019年新学期我们也要正式开工啦,我们在2018年结束了分类任务,今年开始检测任务的学习,还请各位小伙伴们时常来我们博客逛一下,欢迎小伙伴们关注我们(并且打赏小编~啊哈哈哈)!!!新的一学期大家一起撸起袖子加油干!!!冲鸭!!!