基于HoG 的图像特征提取及其分类研究
目录
- 前言
- 1 介绍
- 2 方法
-
- 2.1 数据集准备
- 2.2 特征提取
- 2.3 降维
- 2.4 分类
- 3 实验结果及分析
-
- 3.1 模型对分类性能的影响
- 3.2 特征对分类性能的影响
- 4 结论
前言
最近写了一个python的图片分类任务的作业,本篇博客是将我所做的流程所进行的整理。数据链接:百度网盘 提取码:rkhw,HoG特征理论知识可参考这里,PCA降维可参考这里
1 介绍
特征提取是图像处理中的一大领域,著名的提取算法有HoG(Histogram of Oriented Gradient)[1]、LBP(Local Binary Pattern)[2]和Haar-like[3]等等。近些年来,随着GPU算力的急速发展,深度学习也得到了迅速发展,使得图像特征提取的效率大大提升,各种分类任务的正确率不断的刷新提升。而深度学习存在着较差的可解释性和海量数据需求的问题,这是对机器视觉任务来说是伪命题,与之相反的是,传统特征提取方法可视性非常强,且现有的卷积神经网络可能与这些特征提取方法有一定类似性,因为每个滤波权重实际上是一个线性的识别模式,与这些特征提取过程的边界与梯度检测类似。因此对我们的学习来说,传统特征提取方法的学习是不可少的,本次实验是基于HoG 的图像特征提取及其分类研究。
HOG特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。最早出现在2005年CVPR上,法国的研究人员Navneet Dalal 和Bill Triggs利用HOG特征+SVM进行行人检测,在当时得到了较好的检测效果。主要流程如下:

本次的实验也是基于上述流程进行一步一步实现,最终实现分类。
2 方法
2.1 数据集准备
本次分类任务是对猫、狗、人脸、蛇四种类别的分类。收集每种类别各4000张图片,其中87.5%作为训练集,12.5%作为预测集,且每个类别的占比相同。灰度图的形式读取图片,将图片重塑大小至256×256,最后给数据集的车、狗、人脸、蛇分别打上1,2,3,4的标签,以便训练预测以及后续的性能评估。
2.2 特征提取
1)采用不同的Gamma值(默认2.2)校正法对输入图像进行颜色空间的标准化(归一化),目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰。2)计算图像每个像素的梯度(包括大小和方向),主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。本实验使用Sobel算子进行计算。3)将图像划分成小cells,因考虑到设备的性能及维度过大问题,而本实验一个cell的大小为32×32个像素。3)统计每个cell的梯度直方图(不同梯度的个数),形成每个cell的描述子。4)对每个cell的梯度方向进行投票,本实验将cell的梯度方向180度分成9个方向块即9个bins,每个bin的范围为20,cell梯度的大小作为权值加到bins里面。5)本实验将每四个cell组成一个block(2×2cell/block),一个block内所有cell的特征描述子串联起来便得到该block的HOG特征描述子。6)将图像image内的所有block的bins串联起来就可以得到该图片的HoG特征向量。这一步中由于是串联求和过程,使得梯度强度的变化范围非常大。这就需要对block的梯度强度做归一化。归一化能够进一步地对光照、阴影和边缘进行压缩。
2.3 降维
在提取特征的步骤中,我们可以算出每一张图片提取出的特征向量的维度是2×2×9×7×7等于1764维,这是较大的维数,里面包含了许多冗余信息,所以我们应考虑对特征向量进行降维。本实验实现的是PCA(主成分分析)算法的降维,其主要过程如下:1)对所有样本进行中心化: x i x_i xi← x i x_i xi- ∑ i = 1 n x i \displaystyle\sum_{i=1}^{n} x_i i=1∑nxi。2)计算样本的协方差矩阵 x x T xx^T xxT。3)对协方差矩阵 x x T xx^T xxT做特征值分解。4)取最大的m个特征值所对应的单位特征向量: ω 1 , ω 2 , ⋯ , ω m ω_1,ω_2,⋯,ω_m ω1,ω2,⋯,ωm。5)得到投影矩阵。
2.4 分类
本实验的分类器利用了sklearn库中的svm模型,设置不同的惩罚参数(默认1.0)和核函数(默认’rbf’)的类型进行多次训练和测试。
3 实验结果及分析
本实验采用不同的惩罚程度、核函数、gamma校正值、特征维数的分类性能进行对比,采用了精确率、召回率和micro_F1分数对实验结果进行性能评估。
3.1 模型对分类性能的影响
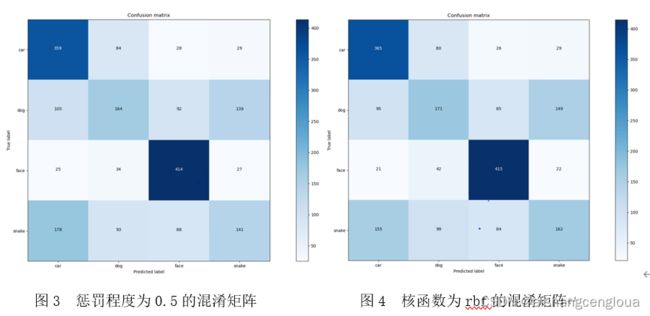
不同惩罚程度的模型性能对比如表1所示。随着惩罚程度的减少,也即松弛变量减小,训练集的正确率从0.866降低至0.753,这是因为对误分类的惩罚减小,允许容错。按照理论来讲此时模型的泛化能力应增强,但是测试集精确率、召回率和micro_F1分数均从0.557减小至0.539,原因未能找到。此外,本实验还统计了此特征提取方法对应的每一类的分类情况,从表1中我们可以看出在车和人脸两类上召回率分别达到0.730和0.830左右,而狗和蛇两类分类的效果很差,分别只有0.334和0.324左右。

不同和函数对模型性能的影响表2所示。在rbf、linear和poly三种核函数中,高斯核函数rbf的性能是最好的有0.557,这是因为训练的维度是14000×404,样本数n远远大于特征维数m,这也导致了linear性能最差;而多项式核函数poly的训练集的精确率有0.977,原因是多项式的阶数很高,网络变得更加复杂,但这也导致了过拟合。对于四种类别之间的分类召回率差异仍未得到很好的改善。

3.2 特征对分类性能的影响
不同gamma值对分类性能的影响如表3所示。随着gamma值从2.2减小至0.5,模型性能由0.557减小至0.530,车、人脸两类分类的召回率由0.730、0.830减小至0.694、0.722,蛇的召回率由0.324升至0.460,狗的召回率先有小幅度上升后减小至0.242,而训练集的精确率由0.866升至0.880,说明模型存在较为明显的过拟合问题。此外,车和人脸的分类召回率依然大幅度超过狗和蛇的分类精确率。

不同特征维数对分类性能的影响如表4所示。特征维数由100增加至704,训练集精确率由0.779增加至0.879,性能由0.589减小至0.555,四个类别的分类召回率出了狗均减小。原因是随着特征维数的增大,保留了更多的冗余信息,导致模型过拟合。






4 结论
本实验通过修改模型参数和特征提取参数来对比分类性能,从表1到表4,无论怎么修改参数,分类性能最高为0.589,始终未超过0.600。本次实验的测试集正确率很低,便考虑到可能是出现预测失衡的原因,因此在具体类别的分类情况上用召回率来衡量更合适。将四个类别的分类召回率进行统计,发现车和人脸的分类效果十分好,最高可以分别达到0.758和0.848,HoG特征与SVM的结合之所以对这两类数据分类有较好的结果是因为HoG特征有对光照的不敏感,即使存在部分遮挡也可检测出来、能够反映人体的轮廓,并且它对图像中的人体的亮度和颜色变化不敏感的优点,因此HoG特征适合行人检测和车俩检测等领域。而本次实验对狗和蛇的分类性能很差,最高分别只有0.354和0.467,原因可能是HoG无法从含有狗和蛇的图片中有效提取它们的梯度和梯度方向,是否可以通过对图片的预处理比如裁剪操作来提高精度,还需要后续的实验。
[1] Dalal N , Triggs B . Histograms of Oriented Gradients for Human Detection[C]// IEEE Computer Society Conference on Computer Vision & Pattern Recognition. IEEE, 2005.
[2] Ojala T , Pietikainen M , Maenpaa T . Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns[C]// IEEE Transactions on Pattern Analysis and Machine Intelligence. IEEE, 2002:971-987.
[3] Papageorgiou C P , Oren M , Poggio T . General framework for object detection[C]// Computer Vision, 1998. Sixth International Conference on. IEEE, 1998.
代码
import cv2 as cv
import numpy as np
import os
import random
import math
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
%matplotlib
class HoG(object) :
def __init__(self, img, cell_w, bin_count) :
rows, cols = img.shape
img = np.power(img / 255.0, 2.2) * 255
self.img = img
self.cell_w = cell_w
self.bin_count = bin_count
self.angle_unit = 180.0 / bin_count
self.cell_x = int(rows / cell_w)
self.cell_y = int(cols / cell_w)
#求每个像素的x和y方向的梯度值和梯度方向
def Pixel_gradient(self) :
gradient_values_x = cv.Sobel(self.img, cv.CV_64F, 1, 0, ksize = 5)#x方向梯度
gradient_values_y = cv.Sobel(self.img, cv.CV_64F, 0, 1, ksize = 5)#y方向梯度
gradient_magnitude = np.sqrt(np.power(gradient_values_x, 2) + np.power(gradient_values_y, 2))#计算总梯度
# gradient_angle = cv.phase(gradient_values_x, gradient_values_y, angleInDegrees=True)#计算梯度方向
gradient_angle = np.arctan2( gradient_values_x, gradient_values_y )
gradient_angle[ gradient_angle > 0 ] *= 180 / 3.14
gradient_angle[ gradient_angle < 0 ] = ( gradient_angle[ gradient_angle < 0 ] + 3.14 ) * 180 / 3.14
return gradient_magnitude, gradient_angle
#求每个cell的x和y方向的梯度值和梯度方向
def Cell_gradient(self, gradient) :
cell = np.zeros((self.cell_x, self.cell_y, self.cell_w, self.cell_w))
gradient_x = np.split(gradient, self.cell_x, axis = 0)
for i in range(self.cell_x) :
gradient_y = np.split(gradient_x[i], self.cell_y, axis = 1)
for j in range(self.cell_y) :
cell[i][j] = gradient_y[j]
return cell
#对每个梯度方向进行投票
def Get_bins(self, cell_gradient, cell_angle) :
bins = np.zeros((cell_gradient.shape[0], cell_gradient.shape[1], self.bin_count))
for i in range(bins.shape[0]) :
for j in range(bins.shape[1]) :
tmp_unit = np.zeros(self.bin_count)
cell_gradient_list = np.int8(cell_gradient[i][j].flatten())
cell_angle_list = cell_angle[i][j].flatten()
cell_angle_list = np.int8( cell_angle_list / self.angle_unit )#0-9
cell_angle_list[ cell_angle_list >=9 ] = 0
# cell_angle_list = cell_angle_list.flatten()
# cell_angle_list = np.int8(cell_angle_list / self.angle_unit) % self.bin_count
for m in range(len(cell_angle_list)) :
tmp_unit[cell_angle_list[m]] += int(cell_gradient_list[m])#将梯度值作为投影的权值
bins[i][j] = tmp_unit
return bins
#获取整幅图像的特征向量
def Block_Vector(self) :
gradient_magnitude, gradient_angle = self.Pixel_gradient()
cell_gradient_values = self.Cell_gradient(gradient_magnitude)
cell_angle = self.Cell_gradient(gradient_angle)
bins = self.Get_bins(cell_gradient_values, cell_angle)
block_vector = []
for i in range(self.cell_x - 1) :
for j in range(self.cell_y - 1) :
feature = []
feature.extend(bins[i][j])
feature.extend(bins[i + 1][j])
feature.extend(bins[i][j + 1])
feature.extend(bins[i + 1][j + 1])
mag = lambda vector : math.sqrt(sum(i ** 2 for i in vector))
magnitude = mag(feature)
if magnitude != 0 :
normalize = lambda vector, magnitude: [element / magnitude for element in vector]
feature = normalize(feature, magnitude)
block_vector.extend(feature)
return np.array(block_vector)
class PCA() :
def __init__(self, n_components) :
self.n_components = n_components
def fit(self, X) :
def deMean(X) :
return X - np.mean(X, axis = 0)
def calcCov(X) :
return np.cov(X, rowvar = False)
def deEigenvalue(cov) :
return np.linalg.eig(cov)
n, self.d = X.shape
assert self.n_components <= self.d
assert self.n_components <= n
X = deMean(X)
cov = calcCov(X)
eigenvalue, featurevector = deEigenvalue(cov)
index = np.argsort(eigenvalue)
n_index = index[-self.n_components : ]
self.w = featurevector[ : , n_index]
return self
def transform(self, X) :
n, d = X.shape
assert d == self.d
return np.dot(X, self.w)
class DataSet(object) :
def __init__(self, root, division) :
self.root = root
self.division = division
def data_segmentation(self, car, dog, face, snake) :
#将每一类图片分割成训练集和测试集,四种类分别设置标签是[1, 2, 3, 4]方便后续的性能评估
train_car, test_car = car[ : int(car.shape[0] * self.division)], car[int(car.shape[0] * self.division) : ]
train_car_target, test_car_target = np.full(len(train_car) , 1, dtype = np.int64), np.full(len(test_car) , 1, dtype = np.int64)
train_dog, test_dog = dog[ : int(dog.shape[0] * self.division)], dog[int(dog.shape[0] * self.division) : ]
train_dog_target, test_dog_target = np.full(len(train_dog) , 2, dtype = np.int64), np.full(len(test_dog) , 2, dtype = np.int64)
train_face, test_face = face[ : int(face.shape[0] * self.division)], face[int(face.shape[0] * self.division) : ]
train_face_target, test_face_target = np.full(len(train_face) , 3, dtype = np.int64), np.full(len(test_face) , 3, dtype = np.int64)
train_snake, test_snake = snake[ : int(snake.shape[0] * self.division)], snake[int(snake.shape[0] * self.division) : ]
train_snake_target, test_snake_target = np.full(len(train_snake) , 4, dtype = np.int64), np.full(len(test_snake) , 4, dtype = np.int64)
#将四类图片拼接成一个大的矩阵
train_data = np.concatenate([train_car, train_dog, train_face, train_snake])
test_data = np.concatenate([test_car, test_dog, test_face, test_snake])
train_target = np.concatenate([train_car_target, train_dog_target, train_face_target, train_snake_target])
test_target = np.concatenate([test_car_target, test_dog_target, test_face_target, test_snake_target])
#以索引方式打乱训练集
index = [i for i in range(len(train_data))]
random.shuffle(index)
train_data = train_data[index]
train_target = train_target[index]
return train_data, train_target, test_data, test_target
def datasets(self) :
#读取每类图片的名字
image_car = list(sorted(os.listdir(os.path.join(self.root, 'car'))))
image_dog = list(sorted(os.listdir(os.path.join(self.root, 'dog'))))
image_face = list(sorted(os.listdir(os.path.join(self.root, 'face'))))
image_snake = list(sorted(os.listdir(os.path.join(self.root, 'snake'))))
#储存图片
car = np.zeros((4000, 256, 256), dtype = np.uint8)
dog = np.zeros((4000, 256, 256), dtype = np.uint8)
face = np.zeros((4000, 256, 256), dtype = np.uint8)
snake = np.zeros((4000, 256, 256), dtype = np.uint8)
#读取车、狗、人脸、蛇的图片,进行resize至256 * 256
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'car', image_car[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
car[i] = img
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'dog', image_dog[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
dog[i] = img
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'face', image_face[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
face[i] = img
for i in range(4000) :
img = cv.imread(os.path.join(self.root, 'snake', image_snake[i]), cv.IMREAD_GRAYSCALE)
img = cv.resize(img, (256, 256), cv.INTER_CUBIC)
snake[i] = img
print(car.shape, dog.shape, face.shape, snake.shape)
#分割
train_data, train_target, test_data, test_target = self.data_segmentation(car, dog, face, snake)
return train_data, train_target, test_data, test_target
def micro_f1(pred, target) :
#第一类
target1 = target.copy()
pred1 = pred.copy()
target1 = target1 == 1
pred1 = pred1 == 1
TP1 = np.sum(target1[pred1 == 1] == 1)
FN1 = np.sum(target1[pred1 == 0] == 1)
FP1 = np.sum(target1[pred1 == 1] == 0)
TN1 = np.sum(target1[pred1 == 0] == 0)
#第二类
target2 = target.copy()
pred2 = pred.copy()
target2 = target2 == 2
pred2 = pred2 == 2
TP2 = np.sum(target2[pred2 == 1] == 1)
FN2 = np.sum(target2[pred2 == 0] == 1)
FP2 = np.sum(target2[pred2 == 1] == 0)
TN2 = np.sum(target2[pred2 == 0] == 0)
#第三类
target3 = target.copy()
pred3 = pred.copy()
target3 = target3 == 3
pred3 = pred3 == 3
TP3 = np.sum(target3[pred3 == 1] == 1)
FN3 = np.sum(target3[pred3 == 0] == 1)
FP3 = np.sum(target3[pred3 == 1] == 0)
TN3 = np.sum(target3[pred3 == 0] == 0)
#第四类
target4 = target.copy()
pred4 = pred.copy()
target4 = target4 == 4
pred4 = pred4 == 4
TP4 = np.sum(target4[pred4 == 1] == 1)
FN4 = np.sum(target4[pred4 == 0] == 1)
FP4 = np.sum(target4[pred4 == 1] == 0)
TN4 = np.sum(target4[pred4 == 0] == 0)
TP = TP1 + TP2 + TP3 + TP4
FN = FN1 + FN2 + FN3 + FN4
FP = FP1 + FP2 + FP3 + FP4
TN = TN1 + TN2 + TN3 + TN4
precision = TP / (TP + FP)
recall = TP / (TP + FN)
f1 = 2 * precision * recall / (precision + recall)
confusion_matrix =np.array([[np.sum(pred[target == 1] == 1), np.sum(pred[target == 1] == 2), np.sum(pred[target == 1] == 3), np.sum(pred[target == 1] == 4)],
[np.sum(pred[target == 2] == 1), np.sum(pred[target == 2] == 2), np.sum(pred[target == 2] == 3), np.sum(pred[target == 2] == 4)],
[np.sum(pred[target == 3] == 1), np.sum(pred[target == 3] == 2), np.sum(pred[target == 3] == 3), np.sum(pred[target == 3] == 4)],
[np.sum(pred[target == 4] == 1), np.sum(pred[target == 4] == 2), np.sum(pred[target == 4] == 3), np.sum(pred[target == 4] == 4)]])
return precision, recall, f1, TP1, TP2, TP3, TP4, confusion_matrix
dataset = DataSet(root = 'data', division = 0.875)
train_data, train_target, test_data, test_target = dataset.datasets()
# 绘制混淆矩阵
def plot_confusion_matrix(cm, classes, title = 'Confusion matrix', cmap = plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap = cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i in range(cm.shape[0]) :
for j in range(cm.shape[1]) :
plt.text(j, i, f'{cm[i][j]}', horizontalalignment="center", color="white" if cm[i][j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
# print(train_data.shape, train_target.shape, test_data.shape, test_target.shape)
# print(test_target, train_target)
#HoG特征获取
train_feature = []
test_feature = []
for i in range(len(train_data)) :
hog = HoG(train_data[i], 32, 9)
temp_feature = hog.Block_Vector()
train_feature.append(temp_feature)
for i in range(len(test_data)) :
hog = HoG(test_data[i], 32, 9)
temp_feature = hog.Block_Vector()
test_feature.append(temp_feature)
train_feature = np.array(train_feature)
test_feature = np.array(test_feature)
# print(train_feature.shape, test_feature.shape)
#PCA降维
pca = PCA(n_components = 704)
pca.fit(train_feature)
train_reduction = pca.transform(train_feature)
test_reduction = pca.transform(test_feature)
print(train_reduction.shape)
print(test_reduction.shape)
#模型训练和预测
clf = svm.SVC()
clf.fit(train_reduction, train_target)
print(clf.score(test_reduction, test_target))
print(clf.score(train_reduction, train_target))
pred = clf.predict(test_reduction)
precision, recall, f1, TP1, TP2, TP3, TP4, confusion_matrix = micro_f1(pred, test_target)
print( precision, recall, f1, TP1, TP2, TP3, TP4, confusion_matrix)
#绘制混淆矩阵
plot_confusion_matrix(cm = confusion_matrix, classes = ['car', 'dog', 'face', 'snake'])